Brief Review — ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators

ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators,
ELECTRA, by Stanford University, Google Brain, & CIFAR Fellow
2020 ICLR, Over 1800 Citations (Sik-Ho Tsang @ Medium)
Natural Language Processing, NLP, Language Model, LM, BERT
- A more sample-efficient pre-training task called replaced token detection is proposed as the name of Efficiently Learning an Encoder that Classifies Token Replacements Accurately (ELECTRA).
- Generator: Instead of masking the input (e.g. BERT), ELECTRA corrupts it by replacing some tokens with plausible alternatives sampled from a small generator network.
- Discriminator: Then, instead of training a model that predicts the original identities of the corrupted tokens (e.g. BERT), a discriminative model is trained to predict whether each token in the corrupted input was replaced by a generator sample or not.
Outline
- Efficiently Learning an Encoder that Classifies Token Replacements Accurately (ELECTRA)
- Results
1. Efficiently Learning an Encoder that Classifies Token Replacements Accurately (ELECTRA)

1.1. Idea
ELECTRA trains two networks, a generator G and a discriminator D.
- Each one primarily consists of an encoder (e.g., a Transformer network) that maps a sequence on input tokens x=[x1, …, xn] into a sequence of contextualized vector representations h(x)=[h1, …, hn].
- For where xt=[MASK], the generator outputs a probability for generating a particular token xt with a softmax layer:

- where e denotes token embeddings.
- For a given position t, the discriminator predicts whether the token xt is “real,” i.e., that it comes from the data rather than the generator distribution, with a sigmoid output layer:

The generator is trained to perform masked language modeling (MLM).
1.2. Procedures
- MLM first select a random set of positions to mask.

- Then, the generator then learns to predict the original identities of the masked-out tokens.

- The discriminator is trained to distinguish tokens in the data from tokens that have been replaced by generator samples.
- The loss functions are:

- The combined loss is:
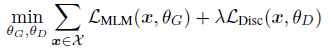
1.3. Downstream
2. Results
2.1. Ablation Study

- Left: Models work best with generators 1/4–1/2 the size of the discriminator.
- Right: Different training strategies are tried, such as adversarial learning, the one that proposed is the best. It is conjectured that adversarially trained generator produces a low-entropy output distribution where most of the probability mass is on a single token, which means there is not much diversity in the generator samples.
2.2. Small Models on GLUE
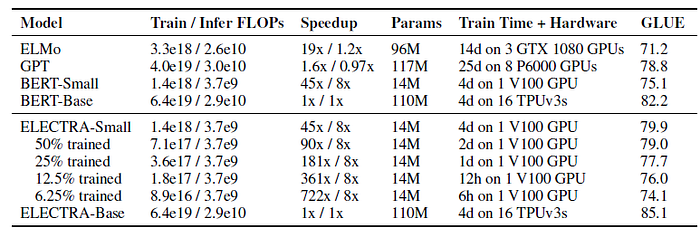
ELECTRA-Small performs remarkably well given its size, achieving a higher GLUE score than other methods using substantially more compute and parameters.
- For example, it scores 5 points higher than a comparable BERT-Small model and even outperforms the much larger GPT model. ELECTRA-Small is trained mostly to convergence, with models trained for even less time (as little as 6 hours) still achieving reasonable performance.
2.3. Large Models on GLUE
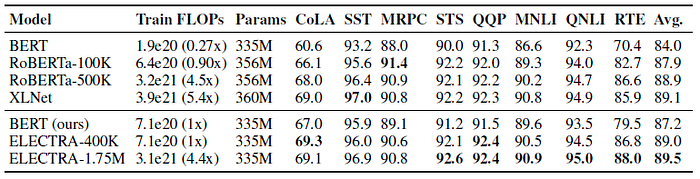
- However, it took less than 1/4 of the compute to train ELECTRA-400K as it did to train RoBERTa and XLNet, demonstrating that ELECTRA’s sample-efficiency gains hold at large scale.
- Training ELECTRA for longer (ELECTRA-1.75M) results in a model that outscores them on most GLUE tasks while still requiring less pre-training compute.
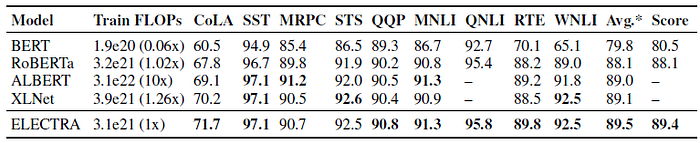
ELECTRA’s gains hold on the GLUE test set, although these comparisons are less apples-to-apples due to the additional tricks employed by the models.
2.4. SQuAD
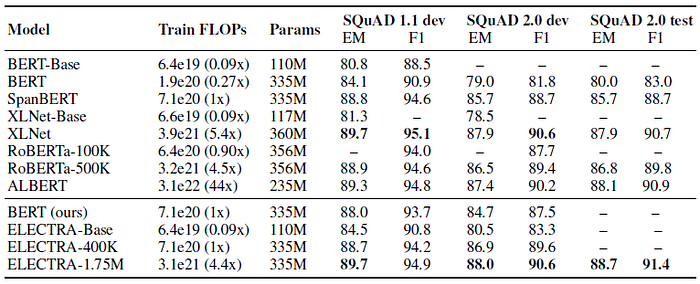
ELECTRA scores better than masked-language-modeling-based methods given the same compute resources. Unsurprisingly, training ELECTRA longer improves results further.
Reference
[2020 ICLR] [ELECTRA]
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
4.1. Language Model / Sequence Model
(Some are not related to NLP, but I just group them here)
1991 … 2020 [ALBERT] [GPT-3] [T5] [Pre-LN Transformer] [MobileBERT] [TinyBERT] [BART] [Longformer] [ELECTRA]
