Brief Review — OPT: Open Pre-trained Transformer Language Models
OPT-175B, Replicate GPT-3, With Model Weights are Open to Public

OPT: Open Pre-trained Transformer Language Models,
OPT, by Meta AI,
2022 arXiv v4, Over 300 Citations (Sik-Ho Tsang @ Medium)Language Model
1991 … 2022 [GPT-NeoX-20B] [GPT-3.5, InstructGPT] [GLM] [MT-NLG 530B] [Chinchilla] [PaLM] [AlexaTM] [BLOOM] [AlexaTM 20B] 2023 [GPT-4]
==== My Other Paper Readings Are Also Over Here ====
- LLMs are difficult to replicate without significant capital. No access is granted to the full model weights, making them difficult to study.
- Open Pre-trained Transformers (OPT) are presented, which are a suite of decoder-only pre-trained Transformers ranging from 125M to 175B parameters.
- The goal of OPT is to replicate GPT-3 with the provision of open access. OPT-175B is comparable to GPT-3 while requiring only 1/7th the carbon footprint to develop.
Outline
- Open Pre-trained Transformer (OPT)
- Results
1. Open Pre-trained Transformer (OPT)
1.1. Model Architecture

- 8 Transformer language models ranging from 125 million to 175 billion parameters are constructed. The models and hyperparameters largely follow GPT-3.
- For weight initialization, OPT follows the same settings provided in the Megatron-LM codebase.
- All models are trained with ReLU and a sequence length of 2048.
- The batch sizes range from 0.5M to 4M depending on the model size.
1.2. Pre-training Corpus
- The pre-training corpus contains a concatenation of datasets used in RoBERTa, the Pile, and PushShift.io Reddit, with some subset selections.
- OPT tokenizes all corpora using the GPT-2 byte level BPE tokenizer.
1.3. Training

- OPT-175B is trained on 992 80GB A100 GPUs, by utilizing Fully Sharded Data Parallel with Megatron-LM Tensor Parallelism.
- Up to 147 TFLOP/s per GPU throughput is obtained.
- Adam state is stored in FP32 while the model weights are in FP16.
- Unfortunately, there were hardware failures contributed to at least 35 manual restarts and the cycling of over 100 hosts over the course of 2 months.
- Loss divergence happens and it is solved by lowering the learning rate and restarting from an earlier checkpoint, as above.
2. Results
2.1. Zero-Shot & Multi-Shot NLP Tasks

Left: Overall, the average performance follows the trend of GPT-3.
Right: OPTs consistently underperform GPT-3. It is hypothesized that the one- and few-shot evaluation setup may differ significantly from GPT-3.
2.2. Dialogue

- OPT compares primarily against existing open source dialogue models including the fine-tuned BlenderBot 1.
OPT-175B significantly outperforms the also-unsupervised Reddit 2.7B model on all tasks.
2.3. Bias, Toxicity, & Dialogue Safety
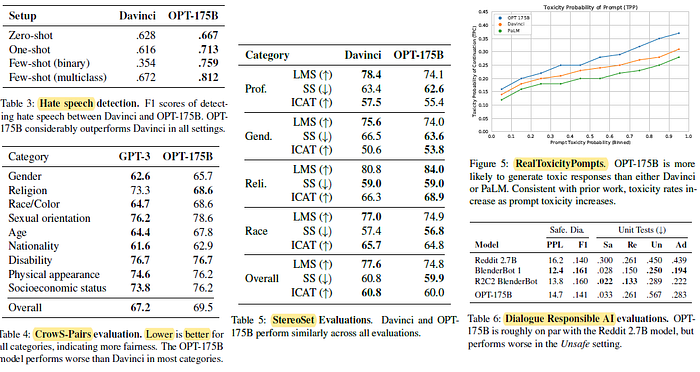
- Table 3: The model is presented with text and asked to consider whether the text is racist or sexist and provide a yes/no response.
OPT-175B performs considerably better than Davinci.
- Table 4: CrowS-Pairs, to measure intrasentence level biases in 9 categories: gender, religion, race/color, sexual orientation, age, nationality, disability, physical appearance, and socioeconomic status. Higher score, higher bias.
OPT-175B appears to exhibit more stereotypical biases in almost all categories except for religion. This is due to the data source for OPT-175B, the model may have learned more discriminatory associations, which directly impacts its performance.
- Table 5: StereoSet measures stereotypical bias across 4 categories.
Davinci and OPT-175B exhibit similar scores on aggregate.
- Figure 5: Prompts from RTP are randomly sampled, and mean toxicity probabilities are reported.
OPT-175B has a higher toxicity rate than either PaLM or Davinci. It is also observed that all 3 models have increased likelihood of generating toxic continuations as the toxicity of the prompt increases.
- Table 6: See if the models generate toxic responses.
OPT-175B has similar performance as the Reddit 2.7B model across both SaferDialogues and the Unit Tests, with OPT-175B performing marginally better in the Safe and Adversarial settings.
2.4. Limitations
- OPT-175B suffers from the same limitations noted in other LLMs:
OPT-175B does not work well with declarative instructions or point-blank interrogatives.
OPT-175B also tends to be repetitive and can easily get stuck in a loop.
Similar to other LLMs, OPT-175B can produce factually incorrect statements.
- And so on.
2.5. Carbon footprint
- There exists significant compute and carbon cost to reproduce models of this size.
While OPT-175B was developed with an estimated carbon emissions footprint (CO2eq) of 75 tons, GPT-3 was estimated to use 500 tons, while Gopher required 380 tons.
