Brief Review — The “Something Something” Video Database for Learning and Evaluating Visual Common Sense
Moving Objects Dataset, Recognize Gestures in the Context of Everyday Objects

The “Something Something” Video Database for Learning and Evaluating Visual Common Sense, Something Something, by TwentyBN
2017 ICCV, Over 600 Citations (Sik-Ho Tsang @ Medium)
Video Classification, Action Recognition, Video Captioning, Dataset
- This paper proposes a “something-something” database of video prediction tasks whose solutions require a common sense understanding of the depicted situation, which contains more than 100,000 videos across 174 classes, which are defined as caption-templates.
- A news article (link shown at the bottom) about TwentyBN makes me read this paper!
Outline
- Something-Something Dataset
- Results
- Something-Something v2
1. Something-Something Dataset
1.1. Crowdsourcing

In this dataset, crowd-workers are asked to record videos and to complete caption-templates, by providing appropriate input-text for placeholders.
- In this example, the text provided for placeholder “something” is “a shoe”.
- Using natural language instead of an action provides a much weaker learning signal than a one-hot label.
- The complexity and sophistication of caption-templates is increased over time, to the degree that models succeed at making predictions, finally having a “Something-Something v2” dataset later on.
- (The paper talks about the detailed rules and procedures of constructing the datasets. Please feel free to read paper directly if interested.)
1.2. Dataset Summary


- The version in the paper, contains 108,499 videos across 174 labels, with duration ranging from 2 to 6 seconds.
- The dataset is split into train, validation and test-sets in the ratio of 8:1:1. All videos provided by the same worker occur only in one split.
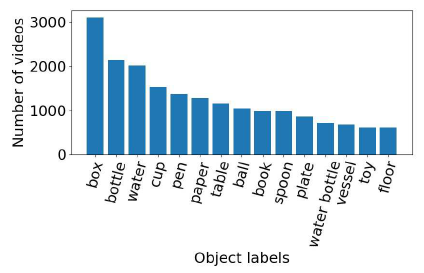
- The dataset contains 23,137 distinct object names. The estimated number of actually distinct objects to be at least a few thousand.
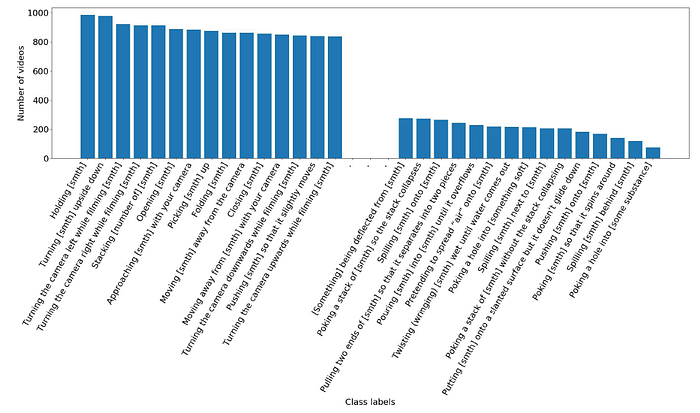
- A truncated distribution of the number of videos per class is shown above, with an average of roughly 620 videos per class, a minimum of 77 for “Poking a hole into [some substance]” and a maximum of 986 for “Holding [something]”.

- The above figure shows some of the example videos.
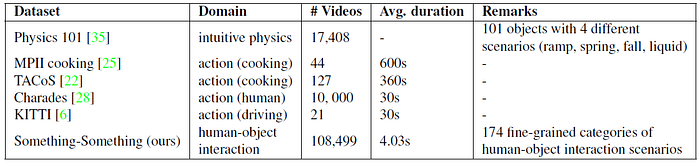
- The above shows the comparison of video datasets.
2. Results
2.1. Datasets

- 10-Class Dataset: 41 “easy” classes are firstly pre-selected. Then, 10 classes are generated by grouping together one or more of the original 41 classes with similar semantics. The total number of videos in this case is 28198.
- 40-Class Dataset: Keeping the above 10 groups, 30 additional common classes are selected. The total number of samples in this case is 53267.
- 174-Class Dataset: Full dataset.
2.2. Baseline Results
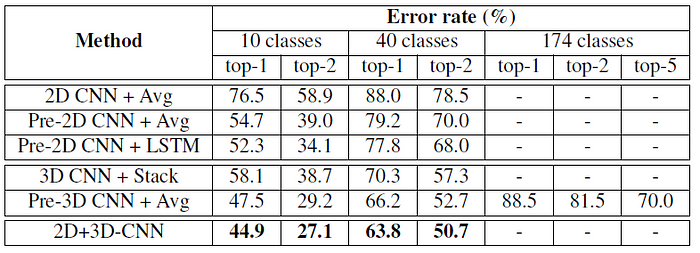
- 2D-CNN+Avg: VGG-16 is used to represent individual frames and averaging the obtained features for each frame in the video to form the final encoding.
- Pre-2D-CNN+Avg: ImageNet-Pretrained 2D-CNN+Avg.
- Pre-2D-CNN+LSTM: ImageNet-Pretrained 2D-CNN but using LSTM. The last hidden state of the LSTM is used as the video encoding.
- 3D-CNN+Stack: C3D with a size of 1024 units for the fully-connected layers and a clip size of 9 frames. Features are extracted from non-overlapping clips of size 9 frames. The obtained features are stacked to obtain a 4096 dimensional representation.
- Pre-3D-CNN+Avg: Sport1M-Pretrained C3D with fine-tuning on this dataset.
- 2D+3D-CNN: A combination of the best performing 2D-CNN and 3D-CNN trained models, obtained by concatenating the two resulting video-encodings.
The difficulty of the task grows significantly as the number of classes are increased.
- On all 174 classes using a 3D-CNN model pre-trained on the 40 selected classes, and obtained error rates of top-1: 88.5%, top-5: 70.3%.
- An informal human evaluation on the complete dataset (174 classes) with 10 individuals is also performed, with 700 test samples in total, about 60% accuracy.
3. Something-Something v2


News Article: https://seekingalpha.com/news/3716397-qualcomm-acquires-team-and-assets-from-ai-company-twenty-billion-neurons
- Later, the assets and the teams of TwentyBN is acquired by QualComm, in July 2021.
- The larger “Something-Something v2” with 220,847 videos, now is hosted in QualComm website.
References
[2017 ICCV] [Something-Something]
The “Something Something” Video Database for Learning and Evaluating Visual Common Sense
[Dataset] [Moving Objects Dataset: Something-Something v. 2]
https://developer.qualcomm.com/software/ai-datasets/something-something
[News Article] [Acquired by Qualcomm]
https://seekingalpha.com/news/3716397-qualcomm-acquires-team-and-assets-from-ai-company-twenty-billion-neurons
1.12. Video Classification / Action Recognition
2014 [Deep Video] [Two-Stream ConvNet] 2015 [DevNet] [C3D] [LRCN] 2016 [TSN] 2017 [Temporal Modeling Approaches] [4 Temporal Modeling Approaches] [P3D] [I3D] [Something Something] 2018 [NL: Non-Local Neural Networks] [S3D, S3D-G] 2019 [VideoBERT]
5.4. Video Captioning
2015 [LRCN] 2017 [Something Something] 2019 [VideoBERT]
