Brief Review — Unified Language Model Pre-training for Natural Language Understanding and Generation
UniLM, Pretraining BERT, Using 3 Language Modeling Tasks
Unified Language Model Pre-training for Natural Language Understanding and Generation, UniLM, by Microsoft Research
2019 NeurIPS, Over 800 Citations (Sik-Ho Tsang @ Medium)
Natural Language Processing, NLP, Language Model, BERT, Transformer
- UniLM is proposed, which is pre-trained using three types of language modeling tasks: unidirectional, bidirectional, and sequence-to-sequence prediction.
- The unified modeling is achieved by employing a shared Transformer network and utilizing specific self-attention masks to control what context the prediction conditions on.
Outline
- UNIfied pre-trained Language Model (UNILM) Pretraining
- Experimental Results
1. UNIfied pre-trained Language Model (UNILM) Pretraining
1.1. SOTA Pretraining Comparisons

- In previous SOTA language model (LM), ELMo, GPT, and BERT, they only have either unidirectional, or bidirectional LM pretraining.
UniLM is proposed to have all types of LM pretraining objectives.
1.2. UniLM Pretraining

- The input vectors {xi} is first packed into H0 = [x1, …, ], and then encoded into contextual representations at different levels of abstract Hl using an L-layer Transformer.
- In each Transformer block, multiple self-attention heads are used to aggregate the output vectors of the previous layer.
- The output of a self-attention head Al is computed via:

- The previous layer’s output Hl-1 is linearly projected to a triple of queries, keys and values using parameter matrices WQl, WKl, and WVl respectively.
To have different LM pretraining objectives, different mask matrices M are used to control what context a token can attend to when computing its contextualized representation.
1.3. LM Pretraining Objectives
- Similar to BERT, some WordPiece tokens are randomly replaced with special token [MASK]. Then, their corresponding output vectors are fed and computed by the Transformer network into a softmax classifier to predict the masked tokens.
1.3.1. Unidirectional LM

- Both left-to-right and right-to-left LM objectives are falled into this category.
- For instance, to predict the masked token of “x1x2 [MASK] x4”, only tokens x1, x2 and itself can be used.
- This is done by using a triangular matrix for the self-attention mask M.
1.3.2. Bidirectional LM
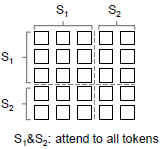
- Bidirectional LM allows all tokens to attend to each other.
- Thus, the self-attention mask M is a zero matrix.
- For the bidirectional LM, the next sentence prediction is also included.
1.3.3. Sequence-to-Sequence LM
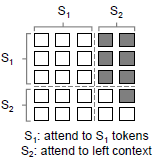
- The tokens in the first (source) segment can attend to each other from both directions within the segment, while the tokens of the second (target) segment can only attend to the leftward context in the target segment and itself, as well as all the tokens in the source segment.
- For example, given source segment t1t2 and its target segment t3t4t5, the input “[SOS] t1 t2 [EOS] t3 t4 t5 [EOS]” is fed into the model.
- While both t1 and t2 have access to the first four tokens, including [SOS] and [EOS], t4 can only attend to the first six tokens.
1.4. Setup
- Within one training batch, 1/3 of the time it uses the bidirectional LM objective, 1/3 of the time it employs the sequence-to-sequence LM objective, and both left-to-right and right-to-left LM objectives are sampled with rate of 1/6.
- For natural language understanding (NLU) tasks, a classification layer is added on top for fine-tuning.
- For natural language generation (NLG) tasks, the model is fine-tuned by masking some percentage of tokens in the target sequence at random, and learning to recover the masked words.
2. Experimental Results
2.1. Text Summarization

- Automatic text summarization produces a concise and fluent summary conveying the key information in the input.
UniLM outperforms all previous abstractive systems, creating a new state-of-the-art abstractive summarization result on the dataset. UniLM also outperforms the best extractive model [27] by 0.88 point in ROUGE-L.
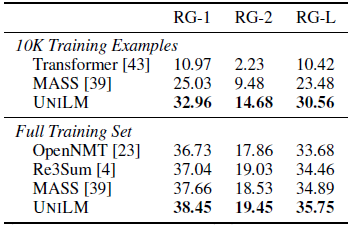
UniLM achieves better performance than previous work. Besides, in the low-resource setting (i.e., only 10,000 examples are used as training data),UniLM outperforms MASS by 7.08 point in ROUGE-L.
2.2. Question Answering (QA)

- Extractive QA (Left/Middle): predict the start and end positions of the answer spans within the passage.
UniLM is fine-tuned in the same way as BERTLARGE. UniLM outperforms BERTLARGE.
- Generative QA (Right): generates free-form answers for the input question and passage, which is a NLG task.
UniLM outperforms previous generative methods by a wide margin, which significantly closes the gap between generative method and extractive method.
2.3. Question Generation
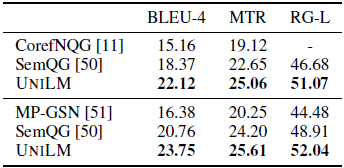
- Given an input passage and an answer span, the goal is to generate a question that asks for the answer.
- The first segment is the concatenation of input passage and answer, while the second segment is the generated question.
UniLM outperforms previous models and achieves a new state-of-the-art for question generation.
2.4. Generated Questions Improve QA

- The question generation model in 2.3. can automatically harvest a large number of question-passage-answer examples from a text corpus, which generates five million answerable examples, and four million unanswerable examples by modifying the answerable ones.
The augmented data generated by UniLM improves question answering model.
2.5. Response Generation

- Given a multi-turn conversation history and a web document as the knowledge source, the system needs to generate a natural language response that is both conversationally appropriate and reflective of the contents of the web document.
UNILM outperforms the best system [41] in the DSTC7 shared task [14] across all evaluation metrics.
2.6. GLUE Benchmark

- GLUE is a collection of nine language understanding tasks, including question answering [33], linguistic acceptability [46], sentiment analysis [38], text similarity [5], paraphrase detection [10], and natural language inference (NLI).
- UniLM obtains comparable performance on the GLUE tasks in comparison with BERTLARGE.
By using three LM pretraining objectives, UniLM outperforms BERT.
Reference
[2019 NeurIPS] [UniLM]
Unified Language Model Pre-training for Natural Language Understanding and Generation
4.1. Language Model / Sequence Model
1997 … 2019 … [UniLM] 2020 [ALBERT] [GPT-3] [T5] [Pre-LN Transformer] [MobileBERT] [TinyBERT]
