Brief Review — YOLOX: Exceeding YOLO Series in 2021

YOLOX: Exceeding YOLO Series in 2021
YOLOX, by Megvii Technology
2021 arXiv v2, Over 3300 Citations (Sik-Ho Tsang @ Medium)Object Detection
2014 … 2021 [Scaled-YOLOv4] [PVT, PVTv1] [Deformable DETR] [HRNetV2, HRNetV2p] [MDETR] [TPH-YOLOv5] 2022 [Pix2Seq] [MViTv2] [SF-YOLOv5] [GLIP] [TPH-YOLOv5++] 2023 [YOLOv7]
==== My Other Paper Readings Are Also Over Here ====
- YOLOX is proposed by switching the YOLO detector to an anchor-free manner and applying other advanced detection techniques, i.e., a decoupled head and the leading label assignment strategy SimOTA.
Outline
- YOLOX
- Results
1. YOLOX
1.1. Decoupled Head

- YOLOv3 is used as basedline. Originally, a single head in YOLOv3 is used to predict the classification, regression and objectness.
In YOLOX, decoupled head is proposed. It contains a 1×1 conv layer to reduce the channel dimension, followed by two parallel branches with two 3×3 conv layers respectively.
- The lite decoupled head brings additional 1.1 ms (11.6 ms v.s. 10.5 ms).

- Decoupled head also greatly improves the converging speed.
1.2. Strong Data Augmentation
- Mosaic in YOLOv4, and mixup are added for data augmentation.
- For small model, mixup is removed and mosaic is weaken.
1.3. Anchor-Free
- Originally, clustered anchors are used, which are domain-specific and less generalized. Also, anchor mechanism increases the complexity of detection heads, as well as the number of predictions for each image.
Anchor-free mechanism significantly reduces the number of design parameters. The predictions for each location are reduced from 3 to 1 and they are directly used for predicting 4 values, i.e., 2 offsets in terms of the left-top corner of the grid, and the height and width of the predicted box.
- The center location of each object is assigned as the positive sample and a scale range is pre-defined to designate the FPN level for each object.
- The center 3×3 is assigned as multi-positive.
1.4. SimOTA
- 4 key insights are concluded for an advanced label assignment: 1). loss/quality aware, 2). center prior, 3). dynamic number of positive anchors for each ground-truth (abbreviated as dynamic top-k), 4). global view.
- SimOTA first calculates pair-wise matching degree, represented by cost
- In SimOTA, the cost between groundtruth gi and prediction pj is calculated as:
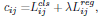
- where Lclsij and Lregij are classficiation loss and regression loss.
For groundtruth gi, YOLOX selects the top k predictions with the least cost within a fixed center region as its positive samples. Finally, the corresponding grids of those positive predictions are assigned as positives, while the rest grids are negatives.
- SimOTA raises the detector from 45.0% AP to 47.3% AP.
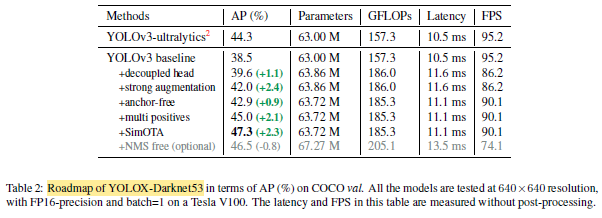
- The corresponding increment of each component is as shown above.




