Brief Review: YOLOv5 for Object Detection
Brief Explanation of YOLOv5, It Outperforms EfficientDet
5 min readJun 9, 2023
YOLOv5 for Object Detection,
YOLOv5, by Ultralytics,
Jun 26, 2020, GitHub (Sik-Ho Tsang @ Medium)Object Detection
2014 … 2020 [EfficientDet] [CSPNet] [YOLOv4] [SpineNet] [DETR] [Mish] [PP-YOLO] [Open Images] 2021 [Scaled-YOLOv4] [PVT, PVTv1] [Deformable DETR] [HRNetV2, HRNetV2p] 2022 [PVTv2] [Pix2Seq] [MViTv2] 2023 [YOLOv7]
==== My Other Paper Readings Are Also Over Here ====
- YOLOv5 version v1 is published on Jun 26, 2020. The latest version is v7, which is published on Nov 22, 2022. Yet, it seems that there is no paper or tech report provided talking about it.
- (One way is to read the codes directly, which is cumbersome. Or finding blogs/vlogs which explains about it. To me, one of the famous blogs to explain YOLOv5 is from Zhihu, which is in Chinese language.)
- (Thus, I decide to write one on my own so that I can easily review it again later. To do this, I’ve found some papers that enhance YOLOv5. Based on these papers, I summarize the basic YOLOv5 as below.)
Outline
- YOLOv5: Overall Architecture
- YOLOv5: Backbone
- YOLOv5: Neck
- YOLOv5: Head
- YOLOv5: Model Variants
- Results
1. YOLOv5: Overall Architecture
- (YOLOv5 is explained in a paper: 2022 MDPI J. Sensors, SF-YOLOv5: A Lightweight Small Object Detection Algorithm Based on Improved Feature Fusion Mode.)
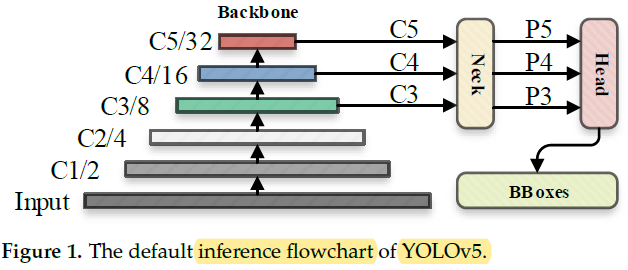
- The image was processed through a input layer (input) and sent to the backbone for feature extraction.
- The backbone obtains feature maps of different sizes, and then fuses these features through the feature fusion network (neck) to finally generate three feature maps P3, P4, and P5 (in the YOLOv5, the dimensions are expressed with the size of 80×80, 40×40 and 20×20) to detect small, medium, and large objects in the picture, respectively.
- After the three feature maps were sent to the prediction head (head), the confidence calculation and bounding-box regression were executed for each pixel in the feature map using the preset prior anchor, so as to obtain a multi-dimensional array (BBoxes) including object class, class confidence, box coordinates, width, and height information.
- By setting the corresponding thresholds (confthreshold, objthreshold) to filter the useless information in the array, and performing a non-maximum suppression (NMS) process, the final detection information can be output.
2. YOLOv5: Backbone


- The backbone is CSPDarknet53.
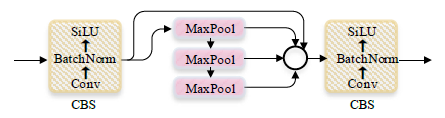
- The main structure is the stacking of multiple CBS (Conv + BatchNorm + SiLU) modules and C3 modules, and finally one SPPF module is connected.
- CBS module is used to assist C3 module in feature extraction, while SPPF module enhances the feature expression ability of the backbone.
3. YOLOv5: Neck


- YOLOv5 uses the methods of FPN and PAN.
- The basic idea of FPN is to up-sampling the output feature map (C3, C4, and C5) generated by multiple convolution down sampling operations from the feature extraction network to generate multiple new feature maps (P3, P4, and P5) for detecting different scales targets.
4. YOLOv5: Head


- The coordinate value of the upper left corner of the feature map is set to (0, 0).
- rx and ry are the unadjusted coordinates of the predicted center point.
- gx, gy, gw, gh represent the information of the adjusted prediction box.
- pw and ph are for the information of the prior anchor.
- sx and sy represent the offsets calculated by the model.
- The process of adjusting the center coordinate and size of the preset prior anchor to the center coordinate and size of the final prediction box.
5. YOLOv5: Model Variants

- There are 5 versions of YOLOv5, namely YOLOv5x, YOLOv5l, YOLOv5m, YOLOv5s, and YOLOv5n.
- There are also 5 corresponding larger versions, YOLOv5x6, YOLOv5l6, YOLOv5m6, YOLOv5s6, and YOLOv5n6.
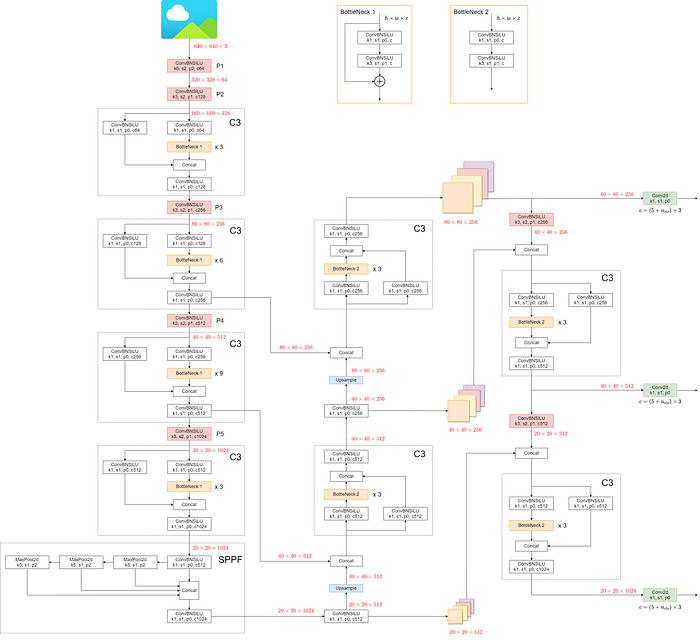
- YOLOv5l model architectures are in details as above.
6. Results
6.1. Larger Models

All YOLOv5 larger models outperforms EfficientDet by large margin.
6.2. Smaller Models
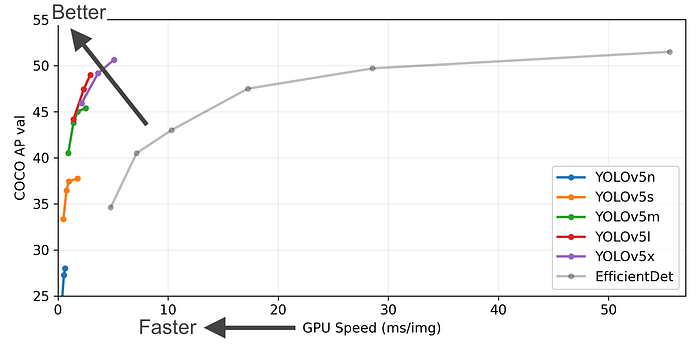
- Similar to smaller models, all YOLOv5 smaller models outperforms EfficientDet by large margin as well, with even faster speed.
6.3. Detailed Results
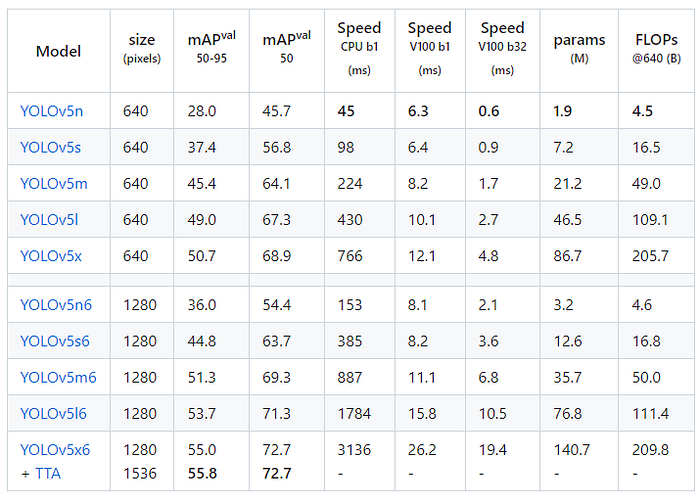
- The detailed results are shown above.
References
- GitHub: https://github.com/ultralytics/yolov5
- Documentation: https://docs.ultralytics.com/yolov5/
- Paper: 2022 MDPI J. Sensors, SF-YOLOv5: A Lightweight Small Object Detection Algorithm Based on Improved Feature Fusion Mode.
- (Since YOLOv5 has been updated for multiple times, the above explanation may not be the same as the most updated version.)
