Review — iGPT: Generative Pretraining from Pixels
Generative Pretraining from Pixels, iGPT, by OpenAI
2020 ICML, Over 300 Citations (Sik-Ho Tsang @ Medium)
Self-Supervised Learning, Unsupervised Learning, Representation Learning, Image Classification, NLP, GPT, GPT-2, BERT, Transformer
- GPT is used, where Transformer is trained to auto-regressively predict pixels, without incorporating knowledge of the 2D input structure.
- With pixel prediction as pretext task, GPT-2 scale model learns strong image representations.
Outline
- iGPT
- Experimental Results
1. iGPT

1.1. Overview
- First, raw images are pre-processed by resizing to a low resolution and reshaping into a 1D sequence.
- Then, one of two pre-training objectives is chosen for pre-training, auto-regressive next pixel prediction, i.e. GPT, or masked pixel prediction, i.e. BERT.
- Finally, the representations learned by these objectives are evaluated with linear probes or fine-tuning.
- (This paper strongly related to GPT, GPT-2 & BERT. Please feel free to read if interested.)
1.1. GPT (AR: Auto-Regressive)
- Given an unlabeled dataset X consisting of high dimensional data x=(x1, …, xn), we can pick a permutation of the set [1, n] and model the density p(x) auto-regressively as follows:

- When working with images, the identity permutation of pixels is picked which is also known as raster order. The model is trained by minimizing the negative log-likelihood of the data, LAR:

1.2. BERT
- Similarly, BERT objective can be applied. The model is trained by minimizing LBERT, the negative log-likelihood of the “masked” elements xM conditioned on the “unmasked” ones x[1, n]\M:

1.3. Architecture
- The Transformer decoder takes an input sequence x1, …, xn of discrete tokens and produces a d-dimensional embedding for each position. The decoder is realized as a stack of L blocks. GPT-2 formulation is used:

- In particular, layer norms precede both the attention and MLP operations, and all operations lie strictly on residual paths.
- Following the final Transformer layer, a layer norm is applied:

1.4. Fine-Tuning
- When fine-tuning, nL is average pooled across the sequence dimension to extract a d-dimensional vector of features per example:

- A projection from fL to class logits is learnt, in which a cross entropy loss LCLF is minimized. While fine-tuning on LCLF yields reasonable downstream performance, the joint objective is considered:

- where
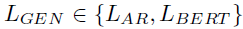
The joint objective is found to have better performance:
1.5. Linear Probing
- Extracting fixed features for linear probing follows a similar procedure to fine-tuning, except that average pooling is not always at the final layer:

- where 0≤l≤L.
It is found that the best features often lie in the middle of the network.
1.6. Practical Issues
- When naively training a Transformer on a sequence of length 224²×3, the attention logits would be tens of thousands of times larger than those used in language models and even a single layer would not fit on a GPU.
- To deal with this, image is firstly resized to a lower resolution, the input resolution (IR). An IR of 32²×3, 48²×3, 96²×3, or 192²×3 is used.
- Or using a VQ-VAE (van den Oord et al., 2017) with a latent grid size of 48², to downsample the images and stay at a MR of 48². (A a latent vocabulary size of 4096 is used.
1.7. Models
- The largest model, iGPT-L, is essentially identical to GPT-2.
- Both models contain L=48 layers, an embedding size of d=1536 (vs 1600) is used, resulting in a slightly reduced parameter count (1.4B vs 1.5B).
- The same model code as GPT-2 is used.
- iGPT-M: A 455M parameter model with L=36 and d=1024.
- iGPT-S: A 76M parameter model with L=24 and d=512.
- A batch size of 128 is used for both pretraining and fine-tuning.
2. Experimental Results
2.1. What Representation Works Best in a Generative Model Without Latent Variables?

Starting around the middle layer, begin to deteriorate until the penultimate layer. Consequently, when evaluating a generative model with a linear probe, it is important to search for the best layer.
2.2. Better Generative Models Learn Better Representations
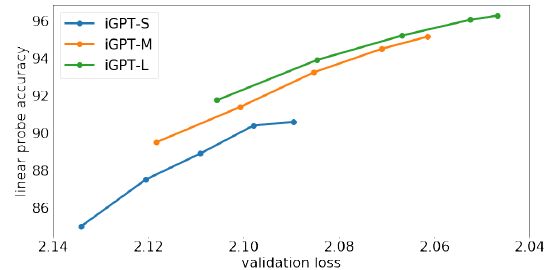
Higher capacity models achieving better validation losses.
2.3. Linear Probes on CIFAR and STL-10
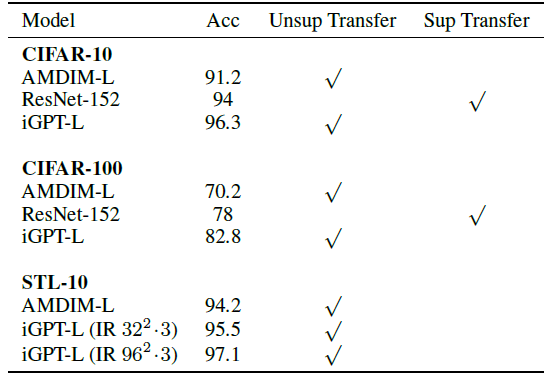
State-of-the-art results are achieved across the entire spectrum of pre-training approaches.
- For example, on CIFAR-10, iGPT-L achieves 96.3%, outperforming both AMDIM-L (pre-trained on ImageNet without labels) and a ResNet-152 (pre-trained on ImageNet with labels).
- In fact, on all three datasets a linear classifier fit to the representations of iGPT-L outperforms the end-to-end supervised training of a WideResNet (WRN) baseline.
2.4. Linear Probes on ImageNet
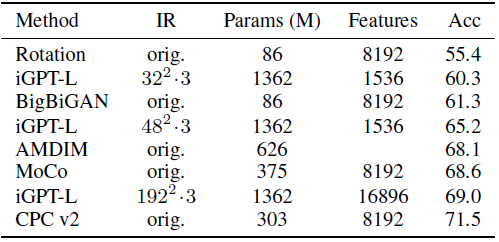
- With a model resolution (MR) of 32², only 60.3% bestlayer linear probe accuracy is achieved. As with CIFAR-10, scale is critical to iGPT approach: iGPT-M achieves 54.5% accuracy and iGPT-S achieves 41.9% accuracy.
- With a MR of 48², a best-layer accuracy of 65.2% is achieved using 1536 features.
If features are concatenated from 11 layers centered at the best single layer, an accuracy of 67.3% using 16896 features is achieved.
2.5. Full Fine-Tuning
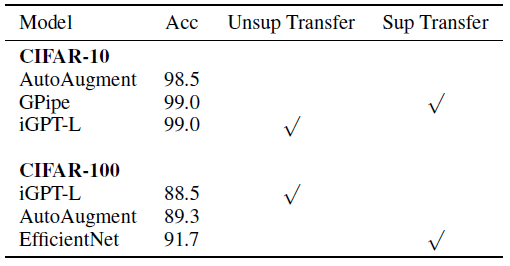
For fine-tuning, on CIFAR-10, 99.0% accuracy is achieved. On CIFAR-100, 88.5% accuracy is achieved.
- On ImageNet, When finetuning at MR 48², 72.6% accuracy is achieved, with a similar 7% bump over linear probing.
2.6. GPT vs BERT
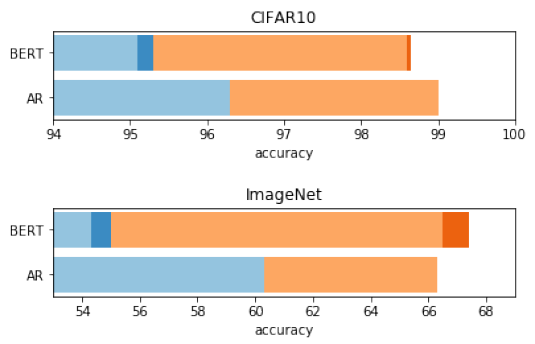
- Blue bars display linear probe accuracy and orange bars display fine-tune accuracy. Bold colors show the performance boost from ensembling BERT masks.
We see that auto-regressive models produce much better features than BERT models after pre-training, but BERT models catch up after fine-tuning.
2.7. Low-Data CIFAR-10 Classification
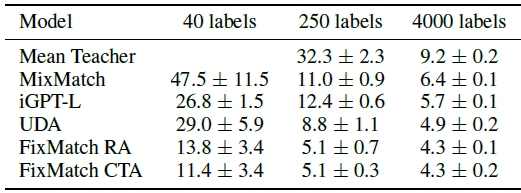
iGPT-L is able to outperform methods such as Mean Teacher (Tarvainen & Valpola, 2017) and MixMatch (Berthelot et al., 2019) but still underperforms the state of the art methods (Xie et al., 2019; Sohn et al., 2020).
2.8. Visualization

- Both reconstructions are generally almost as good as the groundtruth (top), but L1 tends to produce slightly more diffuse images.
2.9. Class-Unconditional Samples from iGPT-L


- Although the goal is not explicitly to produce high quality samples, training an auto-regressive objective gives this capability.
Reference
[2020 ICML] [iGPT]
Generative Pretraining from Pixels
Unsupervised/Self-Supervised Learning
1993 [de Sa NIPS’93] 2008–2010 [Stacked Denoising Autoencoders] 2014 [Exemplar-CNN] 2015 [Context Prediction] [Wang ICCV’15] 2016 [Context Encoders] [Colorization] [Jigsaw Puzzles] 2017 [L³-Net] [Split-Brain Auto] [Motion Masks] [Doersch ICCV’17] 2018 [RotNet/Image Rotations] [DeepCluster] [CPC/CPCv1] [Instance Discrimination] 2020 [CMC] [MoCo] [CPCv2] [PIRL] [SimCLR] [MoCo v2] [iGPT]
