[Paper] ShakeDrop: Shakedrop Regularization for Deep Residual Learning (Image Classification)
Outperforms Shake-Shake & RandomDrop (Stochastic Depth) on ResNeXt, ResNet, Wide ResNet (WRN) & PyramidNet

In this story, ShakeDrop Regularization for Deep Residual Learning (ShakeDrop), by Osaka Prefecture University, and Preferred Networks, Inc., is shortly presented. In this paper:
- ShakeDrop is proposed which is more effective than Shake-Shake and can be applied not only to ResNeXt but also ResNet, Wide ResNet (WRN), and PyramidNet.
This is a paper in 2019 IEEE ACCESS with over 40 citations, where ACCESS is an open access journal with high impact factor of 3.745. (Sik-Ho Tsang @ Medium)
Outline
- Brief Review of Shake-Shake
- Brief Review of RandomDrop (a.k.a. Stochastic Depth)
- ShakeDrop
- Experimental Results
1. Brief Review of Shake-Shake

- The basic ResNeXt building block, which has a three-branch architecture, is given as:

- Let α and β be independent random coefficients uniformly drawn from the uniform distribution on the interval [0, 1]. Then Shake-Shake is given as:

- where train-fwd and train-bwd denote the forward and backward passes of training, respectively. Expected values E[α] = E[1-α] = 0.5.
- The values of α and β are drawn for each image or batch.
1.1. Interpretation of Shake-Shake by Authors of ShakeDrop
- Authors of Shake-Shake did not provide interpretation.
- Shake-Shake makes the gradient β/α times as large as the correctly calculated gradient on one branch and (1-β)/(1-α) times on the other branch. It seems that the disturbance prevents the network parameters from being captured in local minima.
- Shake-Shake interpolates the outputs of two residual branches.
- The interpolation of two data in the feature space can synthesize reasonable augmented data. Hence the interpolation in the forward pass of Shake-Shake can be interpreted as synthesizing reasonable augmented data.
The use of random weight α enables us to generate many different augmented data. By contrast, in the backward pass, a different random weight β is used to disturb the updating parameters, which is expected to help to prevent parameters from being caught in local minima by enhancing the effect of SGD.
2. Brief Review of RandomDrop (a.k.a. Stochastic Depth)

- The basic ResNet building block, which has a two-branch architecture, is:
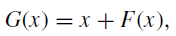
- RandomDrop makes the network appear to be shallow in learning by dropping some stochastically selected building blocks.
- The lth building block from the input layer is given as:
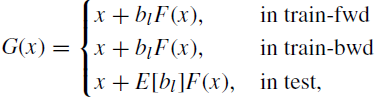
- where bl ∈{0, 1} is a Bernoulli random variable with the probability P(bl =1) =E[bl] = pl. And linear decay rule is used to determine pl:
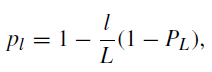
- where L is the total number of building blocks and PL=0.5.
- RandomDrop can be regarded as a simpli ed version of Dropout. The main difference is that RandomDrop drops layers, whereas Dropout drops elements.
3. ShakeDrop

- By mixing Shake-Shake and RandomDrop, it becomes ShakeDrop as above.
- It is expected that (i) when the original network is selected, learning is correctly promoted, and (ii) when the network with strong perturbation is selected, learning is disturbed, as shown in the first figure at the top of this story.
- ShakeDrop coincides with RandomDrop when α =β = 0.
4. Experimental Results
4.1. CIFAR

- “Type A’’ and “Type B’’ indicate that the regularization unit was inserted after and before the addition unit for residual branches, respectively.
- ShakeDrop can be applied not only to three-branch architectures (ResNeXt) but also two-branch architectures (ResNet, Wide ResNet (WRN), and PyramidNet), and ShakeDrop outperformed RandomDrop and Shake-Shake.
4.2. ImageNet
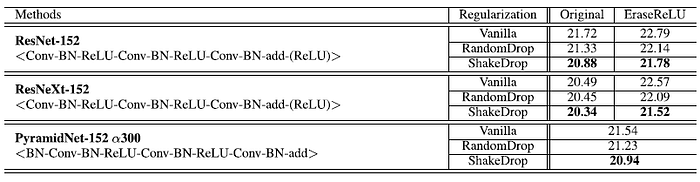
- On ResNet, ResNeXt, and PyramidNet, ShakeDrop clearly outperformed RandomDrop and the vanilla network.
4.3. COCO Detections and Segmentation
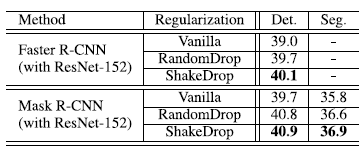
- Faster R-CNN and Mask R-CNN are used as the detectors with ImageNet pre-trained ResNet-152.
- On Faster R-CNN and Mask R-CNN, RandomDrop clearly outperformed RandomDrop and the vanilla network.
4.4. ShakeDrop with mixup
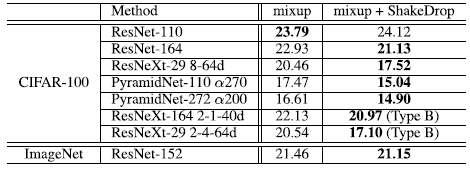
There are a lot of experimental studies on the determination of values for α, β and PL. If interested, please feel free to read the paper.
Reference
[2019 IEEE ACCESS] [ShakeDrop]
Shakedrop Regularization for Deep Residual Learning
Image Classification
1989–1998: [LeNet]
2012–2014: [AlexNet & CaffeNet] [Maxout] [Dropout] [NIN] [ZFNet] [SPPNet]
2015: [VGGNet] [Highway] [PReLU-Net] [STN] [DeepImage] [GoogLeNet / Inception-v1] [BN-Inception / Inception-v2]
2016: [SqueezeNet] [Inception-v3] [ResNet] [Pre-Activation ResNet] [RiR] [Stochastic Depth] [WRN] [Trimps-Soushen]
2017: [Inception-v4] [Xception] [MobileNetV1] [Shake-Shake] [Cutout] [FractalNet] [PolyNet] [ResNeXt] [DenseNet] [PyramidNet] [DRN] [DPN] [Residual Attention Network] [IGCNet / IGCV1] [Deep Roots]
2018: [RoR] [DMRNet / DFN-MR] [MSDNet] [ShuffleNet V1] [SENet] [NASNet] [MobileNetV2] [CondenseNet] [IGCV2] [IGCV3] [FishNet] [SqueezeNext] [ENAS] [PNASNet] [ShuffleNet V2] [BAM] [CBAM] [MorphNet] [NetAdapt] [mixup] [DropBlock]
2019: [ResNet-38] [AmoebaNet] [ESPNetv2] [MnasNet] [Single-Path NAS] [DARTS] [ProxylessNAS] [MobileNetV3] [FBNet] [ShakeDrop]

