Review — Bag of Freebies for Training Object Detection Neural Networks
Using Bag Of Freebies Improving Precisions Without Modifying Architecture

In this story, Bag of Freebies for Training Object Detection Neural Networks, Bag of Freebies, by Amazon Web Services, is reviewed. In this paper:
- Various training tweaks are applied to Faster R-CNN and YOLOv3.
- Without modifying the architecture, these freebies can improve up to 5% absolute precision.
This is a paper in 2019 arXiv with over 80 citations. (Sik-Ho Tsang @ Medium)
Outline (6 Freebies)
- mixup
- Classification Head Label Smoothing
- Data Augmentation
- Training Schedule Revamping
- Synchronized Batch Normalization
- Random Shapes Training for Single-Stage Object Detection Networks
- Experimental Results
1. mixup
1.1. mixup in Image Classification

- mixup was proposed in image classification task to regularize the neural network to favor simple linear behavior by mixing up pixels as interpolations between pairs of training images.
- Meanwhile, one-hot image labels are mixed up using the same ratio.
- (Please feel free to read mixup if interested.)
1.2. mixup in Object Detection

- In object detection, authors propose to use geometry preserved alignment for image mixup to avoid distort images at the initial steps.

- It is shown that using beta distribution of B(1.5, 1.5) is marginally better than 1.0 (equivalent to uniform distribution) and better than fixed even mixup.
It is recognized that for object detection where mutual object occlusion is common, networks are encouraged to observe unusual crowded patches, either presented naturally or created by adversarial techniques.
2. Classification Head Label Smoothing
- In image classification, the probablity pi after softmax is:

- where zi are the unnormalized logits.
- The cross entropy loss is:
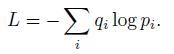
- where q is often a one-hot distribution.
- Label smoothing was proposed by Inception-v3, which is used to smooth the ground-truth label in order for network regularization:
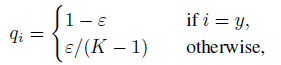
- where K is the total number of classes and ε is a small constant.
- This technique reduces the model’s confidence, measured by the difference between the largest and smallest logits.
- It is suggested to be used as one of the freebies.
3. Data Augmentation
- In image classification, it is actually encouraged to randomly perturb the spatial characteristics, e.g. randomly flip, rotate and crop images in order to improve generalization accuracy and avoid overfitting.
- In object detection, additional cautious are needed since detection networks are more sensitive to such transformations.
- Random geometry transformation including random cropping (with constraints), random expansion, random horizontal flip and random resize (with random interpolation).
- Random color jittering including brightness, hue, saturation, and contrast.
- For single-stage detector, such as YOLOv3, random geometry transformation is encouraged.
- For two-stage detector, such as Faster R-CNN, RoI is firstly cropped, then object detection is performed within the RoI. Such sample-based approach already conduct enormous cropping operations on feature maps.
- These networks do not require extensive geometric augmentations.
- Thus, Faster R-CNN does not use random cropping.
4. Training Schedule Revamping
- The step schedule is the most widely used learning rate schedule.
- With step schedule, the learning rate is multiplied by a constant number below 1 after reaching pre-defined epochs or iterations.
- Step schedule has sharp learning rate transition which may cause the optimizer to re-stabilize the learning momentum in the next few iterations.
- In contrast, for a smoother cosine learning rate adjustment, Cosine schedule scales the learning rate according to the value of cosine function on 0 to pi.
- It starts with slowly reducing large learning rate, then reduces the learning rate quickly halfway, and finally ends up with tiny slope reducing small learning rate until it reaches 0.
- Warmup learning rate is another common strategy to avoid gradient explosion during the initial training iterations.

- It is found that validation mAP achieved by applying cosine learning rate decay outperforms step learning rate schedule at all times in training.
5. Synchronized Batch Normalization
- Batch normalization hurts the performance in some tasks with a small batch size (e.g., 1 per GPU).
- Synchronized Batch Normalization is suggested to be used which can be performed across multiple GPUs.
6. Random Shapes Training for Single-Stage Object Detection Networks
- Natural training images come in various shapes.
- A mini-batch of N training images is resized to N×3×H×W, where H and W are multipliers of network stride.
- For example, H = W ∈ {320, 352, 384, 416, 448, 480, 512, 544, 576, 608} is used for YOLOv3 training given the stride of feature map is 32.
- i.e. the multi-scale training.
7. Experimental Results
- In order to remove side effects of test time tricks, only single scale, single model results are reported with standard Non maximum Suppression implementation. And no external training image or labels used.
7.1. YOLOv3 on PASCAL VOC 2007 Using Bag of Freebies

- Pascal VOC 2007 trainval and 2012 trainval are used for training and 2007 test set is used for validation.
- If random shape training is enabled, YOLOv3 models will be fed with random resolutions from 320×320 to 608×608 with 32×32 increments.
- Data augmentation contributed nearly 16% to the baseline mAP.
- Stacking Synchronized BatchNorm, Random Training, cosine learning rate schedule, Sigmoid label smoothing and detection mixup continuously improves validation performance, up to 3.43%, achieving 83.68% single model single scale mAP.
7.2. Faster R-CNN on PASCAL VOC 2007 Using Bag of Freebies
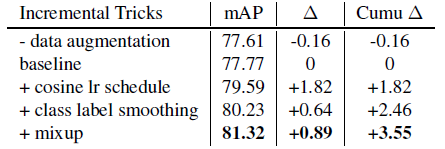
- Faster R-CNN models take arbitrary input resolutions.
- Disabling data augmentation only introduced a minimal 0.16% mAP loss. This phenomena is indicating that sampling based proposals can effectively replace random cropping.
- Incremental mAPs show strong confidence that the proposed tricks can effectively improve model performance, with a significant 3.55% gain.
- It is noted that it is challenging to achieve mAP higher than 80% with out external training data on Pascal VOC.
7.3. Bag of Freebies on MS COCO
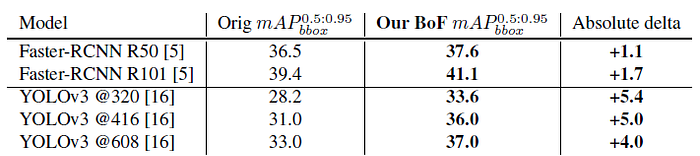
- COCO 2017 is 10 times larger than Pascal VOC and contains much more tiny objects.
- Similar observation is shown that bag of freebies help both YOLOv3 and Faster R-CNN.
7.4. Impact of mixup on Different Phases of Training Detection Network


- mixup can be applied in two phases of object detection networks:
- YOLOv4 later on further extended the scope of bag of freebies using more advanced techniques. Though YOLOv4 has been widely reviewed by many blogs, I will review it in the coming future.
Reference
[2019 arXiv] [Bag of Freebies]
Bag of Freebies for Training Object Detection Neural Networks
Object Detection
2014–2017: …
2018: [YOLOv3] [Cascade R-CNN] [MegDet] [StairNet] [RefineDet] [CornerNet]
2019: [DCNv2] [Rethinking ImageNet Pre-training] [GRF-DSOD & GRF-SSD] [CenterNet] [Grid R-CNN] [NAS-FPN] [ASFF] [Bag of Freebies]
2020: [EfficientDet]
