Review — NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection
Searching Architectures for FPN, Combining with RetinaNet, Outperforms MobileNetV2 and Mask R-CNN with Less Complexity

In this story, NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection, (NAS-FPN), by Google Brain, is reviewed.
- FPN is widely used in object detection task as it efficiently searched for small and large objects via multi-scale feature maps in pyramid-style.
In this paper:
- While there are prior arts searching the feature extraction parts or the backbone, Neural architecture search (NAS), this time, is used to search the FPN architecture.
- Finally, the discovered architecture, named NAS-FPN, consists of a combination of top-down and bottom-up connections to fuse features across scales.
- This NAS-FPN can be stacked N times for better accuracy. Combining with RetinaNet, the object detection network achieves better accuracy and latency tradeoff.
This is a paper in 2019 CVPR with over 400 citations. (Sik-Ho Tsang @ Medium)
Outline
- NAS-FPN
- Neural Architecture Search Space
- Deeply Supervised Anytime Object Detection
- Experimental Results
1. NAS-FPN


- The network is based on RetinaNet which has 2 components: backbone and FPN.
- The goal of the proposed algorithm is to discover a better FPN architecture for RetinaNet.
- NAS, as proposed in NASNet, is used such that there is a RNN controller to select best model architectures in a given search space using reinforcement learning.
- The RNN controller uses the accuracy of a child model in the search space as the reward to update its parameters. Through trial and error, the RNN controller learns to generate better architectures over time.
- For scalability of the FPN, during the search, the FPN is forced to repeat itself N times and then concatenated into a large architecture.
2. Neural Architecture Search Space
- FPN takes multiscale feature layers as inputs and generate output feature layers in the identical scales, as in the above figure.
- FPN uses the last layer in each group of feature layers as the inputs to the first pyramid network. The output of the first pyramid network are the input to the next pyramid network.
- The inputs features are in 5 scales {C3, C4, C5, C6, C7} with corresponding feature stride of {8, 16, 32, 64, 128} pixels. The C6 and C7 are created by simply applying stride 2 and stride 4 max pooling to C5.
- The input features are then passed to a pyramid network consisting of a series of merging cells (see below) that introduce cross-scale connections.
- The pyramid network then outputs augmented multiscale feature representations {P3, P4, P5, P6, P7}.
- Since both inputs and outputs of a pyramid network are feature layers in the identical scales, the architecture of the FPN can be stacked repeatedly for better accuracy. Controlling the number of pyramid networks is one simple way to tradeoff detection speed and accuracy.
2.1. Merging Cell
- It is essential to “merge” features at different scales.
- The cross-scale connections allow model to combine high-level features with strong semantics and low-level features with high resolution.
Merging cell, is a fundamental building block of a FPN, to merge any two input feature layers into a output feature layer.
- A FPN consists of N different merging cells, where N is given during search. (The N here is not the same as the N used for the number of stacked FPN. N is used again just because I want to synchronize with the paper.)
- In a merging cell, all feature layers have the same number of filters.
2.2. Searching of Merging Cell
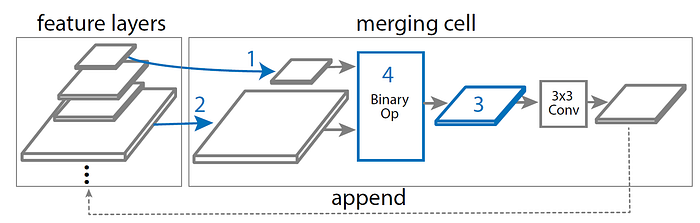
- The decisions of how to construct the merging cell are made by a controller RNN.
- The RNN controller selects any two candidate feature layers and a binary operation to combine them into a new feature layer.
- Steps are as follow:
- Select a feature layer hi from candidates.
- Select another feature layer hj from candidates without replacement.
- Select the output feature resolution.
- Select a binary op to combine hi and hj selected in Step 1 and Step 2 and generate a feature layer with the resolution selected in Step 3.
- The newly-generated feature layer is appended to the list of existing input candidates and becomes a new candidate for the next merging cell.
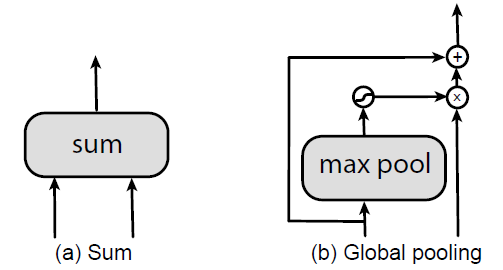
- Two binary operations, sum and global pooling, are considered in Step 4, since these 2 operations are parameter-free.
- Global pooling is based on the idea in PAN, except removing convolution layers in the original design.
2.3. Some Further Searching Details
- The input feature layers are adjusted to the output resolution by nearest neighbor upsampling or max pooling if needed before applying the binary operation.
- The merged feature layer is always followed by a ReLU, a 3×3 convolution, and a batch normalization layer.
(By observing the above considerations, we can see that parameter-free operations are used. ReLU-Conv-BatchNorm is used after the feature merging. This helps to reduce the search space a lot.)
- To reduce computation in discovered architecture, we avoid selecting stride 8 feature in Step 3.
- In the end, the last 5 merging cells are designed to outputs feature pyramid {P3, P4, P5, P6, P7}.
- The order of output feature levels is predicted by the controller. Each output feature layer is then generated by repeating the step 1, 2, 4 until the output feature pyramid is fully generated.
- Similar to NASNet, all input feature layers that have not been connected to any of output layer (i.e. not selected by the RNN controller) are sum to the output layer that has the corresponding resolution.
3. Deeply Supervised Anytime Object Detection
- One advantage of scaling NAS-FPN with stacked pyramid networks is that feature pyramid representations can be obtained at output of any given pyramid network.
- This property enables anytime detection which can generate detection results with early exit.
- Classifier and box regression heads can be placed after all intermediate pyramid networks and can be trained with deep supervision.
- During inference, the model does not need to finish the forward pass for all pyramid networks.
- This can be a desirable property when computation resource or latency is a concern and provides a solution that can dynamically decide how much computation resource to allocate for generating detections.
4. Experimental Results
4.1. Training Details
- The models are trained on TPUs with 64 images in a batch.
- Multiscale training with a random scale between [0.8, 1.2] is used to the output image size.
- α = 0.25 and γ = 1.5 for focal loss, as used in RetinaNet.
- The model is trained using 50 epochs.
- With DropBlock, a longer training schedule of 150 epochs is used.
- With AmoebaNet backbone on image size of 1280×1280, cosine learning rate schedule is used.
- The model is trained on COCO train2017 and evaluated on COCO val2017 for most experiments.
4.1. Architecture Search for NAS-FPN
- During searching, the proxy task is only trained for 10 epochs.
- To further speed up training proxy task, a small backbone of ResNet-10 is used with input 512×512 image size.
- Thus, the training time is 1hr for a proxy task on TPUs.
- A randomly selected 7392 images from the COCO train2017 set as the validation set, which is used to obtain rewards.
- The workqueue in the experiments consisted of 100 TPUs.
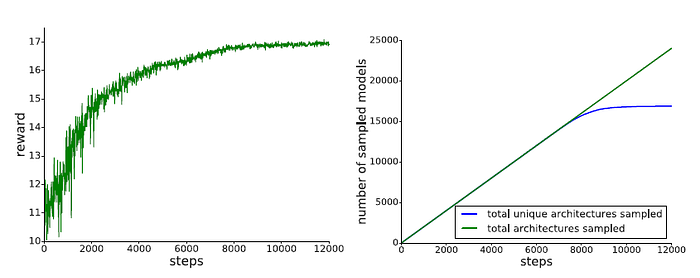
Left: The controller generated better architectures over time.
Right: The number of unique architectures converged after about 8000 steps.

- The architecture with the highest AP from all sampled architectures during RL training is finally picked up for usage as shown above.
- GP and R-C-B are stands for Global Pooling and ReLU-Conv-BatchNorm.
- This architecture is first sampled at 8000 step and sampled many times after that.
4.2. Discovered Feature Pyramid Architectures

- The above figure shows the NAS-FPN architectures with progressively higher reward during RL training.
- (a): Vanilla FPN
- (b): NAS-FPN from earlier searching stage to later searching stage.
The RNN controller can quickly pick up some important cross-scale connections in the early learning stage.
- For example, it discovers the connection between high resolution input and output feature layers, generating high resolution features for detecting small objects.
- The controller discovers architectures that have both top-down and bottom-up connections which is different from vanilla FPN.
- Better feature reuse is used as the controller converges.
- The controller learns to build connections on newly-generated layers to reuse previously computed feature representations.
4.3. Scalable Feature Pyramid Architecture

- Simpler notation is used here. For example, R-50, 5 @ 256 indicate a model using ResNet-50 backbone model, 5 stacked NAS-FPN pyramid networks, and 256 feature dimension.
- (a): Stacking the vanilla FPN architecture does not always improve performance whereas stacking NAS-FPN improves accuracy significantly.
- (b): NAS-FPN with both light and heavy backbone architectures benefits from stacking more pyramid networks.
- NAS-FPN with MobileNetV2 on the image size of 640×640, gets 36.6 AP with 160B FLOPs.
- When AmoebaNet-D is used as the backbone, it increases the FLOPs to 390B but also adds about 5 AP.
- (c): Not surprisingly, increasing the feature dimension improves detection performance but it may not be an efficient way.
- Also, increasing feature dimension would require model regularization technique, e.g. DropBlock, which will be mentioned later.
4.4. Architectures for High Detection Accuracy/Fast Inference

- (a): NAS-FPN R-50 5 @256 model has comparable FLOPs to the R-101 FPN baseline but with 2.5 AP gain.
- The NAS-FPN is as accurate as to the state-of-the-art Mask R-CNN model with less computation time.
- This shows using NAS-FPN is more effective than replacing the backbone with a higher capacity model.
- (b): NAS-FPNLite is introduced here for mobile object detection.
- It search a pyramid network that has outputs from P3 to P6 only.
- Convolution is replaced by depth-wise separable convolution.
- A 15-cell architecture is discovered.
- NAS-FPNLite and MobileNetV2 are combined in RetinaNet framework.
- FPNLite baseline: Similar to NAS-FPNLite but using FPN baseline.
- The feature dimension of NAS-FPN is controlled to be 48 or 64 so that it has similar FLOPs and CPU runtime on Pixel 1 as baseline methods.
- The above figures show that NAS-FPNLite outperforms both SSDLite and FPNLite.
4.5. Further Improvements with DropBlock

- Models are trained with backbone of ResNet-50 on image size of 1024×1024.
- DropBlock with block size 3×3 is applied after batch normalization layers in the the NAS-FPN layers.
- Adding DropBlock is more important when we increase feature dimension in pyramid networks.
Reference
[2019 CVPR] [NAS-FPN]
NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection
Object Detection
2014: [OverFeat] [R-CNN]
2015: [Fast R-CNN] [Faster R-CNN] [MR-CNN & S-CNN] [DeepID-Net]
2016: [OHEM] [CRAFT] [R-FCN] [ION] [MultiPathNet] [Hikvision] [GBD-Net / GBD-v1 & GBD-v2] [SSD] [YOLOv1]
2017: [NoC] [G-RMI] [TDM] [DSSD] [YOLOv2 / YOLO9000] [FPN] [RetinaNet] [DCN / DCNv1] [Light-Head R-CNN] [DSOD] [CoupleNet]
2018: [YOLOv3] [Cascade R-CNN] [MegDet] [StairNet] [RefineDet] [CornerNet]
2019: [DCNv2] [Rethinking ImageNet Pre-training] [GRF-DSOD & GRF-SSD] [CenterNet] [Grid R-CNN] [NAS-FPN]
