Review — Grid R-CNN (Object Detection)
Predicting Grid Points Using Fully Convolutional Network (FCN), Outperforms CornerNet, Mask R-CNN, RetinaNet, RefineDet, DSSD, SSD, YOLOv2

In this story, Grid R-CNN, by SenseTime Research, The Chinese University of Hong Kong, and Beihang University, is reviewed. In this paper:
- The Grid R-CNN is proposed to capture the spatial information explicitly and enjoys the position sensitive property of fully convolutional architecture.
- A multi-point supervision formulation is designed to encode more clues in order to reduce the impact of inaccurate prediction of specific points.
- A two-stage information fusion strategy is used to fuse feature maps of neighbor grid points. The grid guided localization approach is easy to be extended to different state-of-the-art detection frameworks.
This is a paper in 2019 CVPR with over 130 citations. (Sik-Ho Tsang @ Medium)
Outline
- Difference From CornerNet
- Grid R-CNN: Framework
- Ablation Study
- SOTA Comparison
- Further Analysis
1. Difference From CornerNet
- Grid R-CNN is quite different from CornerNet.
- CornerNet is a bottom-up method, which means it directly generate keypoints from the entire image without defining instance. The key step of the CornerNet is to recognize keypoints and grouping them correctly.
- In contrast to that, Grid R-CNN is a top-down two-stage detector which defines instance at first stage. What focusing on is how to locate the grid points accurately.
2. Grid R-CNN: Framework

2.1. Grid Guided Localization
- Most previous methods use several fully connected layers as a regressor to predict the bounding box, as in the (a) of the first figure.
- In Grid R-CNN, an N×N grid form of target points aligned in the bounding box of object is designed so that any FCN architectures can be applied, as in (b) of the first figure.
- Features of each proposal are extracted by RoIAlign, used in Mask R-CNN, operation with a fixed spatial size of 14×14, followed by eight 3×3 dilated(for large receptive field) convolutional layers.
- After that, two 2× group deconvolution layers are adopted to achieve a resolution of 56×56.
- The grid prediction branch outputs N×N heatmaps with 56×56 resolution, and a pixel-wise sigmoid function is applied on each heatmap to obtain the probability map.
- Each heatmap has a corresponding supervision map, where 5 pixels in a cross shape are labeled as positive locations of the target grid point.
- Binary cross-entropy loss is utilized for optimization.
2.1.1. Mapping of Grid Points from Heatmap to Original Image
- During inference, on each heatmap, the pixel with highest confidence is selected and the corresponding location on the original image is calculated as the grid point.
- Formally, a point (Hx, Hy) in heatmap will be mapped to the point (Ix, Iy) in original image by the following equation:
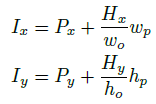
- where (Px, Py) is the position of upper left corner of the proposal in input image, wp and hp are width and height of proposal, wo and ho are width and height of output heatmap.
2.1.2. Determining Bounding Box According to the Grid Points
- Then the four boundaries of the box of object are determined with the predicted grid points.
- Specifically, the four boundary coordinates are denoted as B = (xl, yu, xr, yb) representing the left, upper, right and bottom edge respectively.
- Let gj represent the j-th grid point with coordinate (xj, yj) and predicted probability pj.
- Ei is defined as the set of indices of grid points that are located on the i-th edge.
- If gj lies on the i-th edge of the bounding box. We have the following equation to calculate B with the set of g:
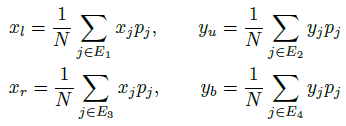
- Taking the upper boundary yu as an example, it is the probability weighted average of y axis coordinates of the three upper grid points.
2.2. Grid Points Feature Fusion
- The grid points have inner spatial correlation, and their locations can be calibrated by each other to reduce overall deviation.
- To distinguish the feature maps of different points, N×N group of filters are used to extract the features for them individually (from the last feature map).
- Intermediate supervision are given for their corresponding grid points.
- Thus each feature map has specified relationship with a certain grid point and the feature map corresponding to the i-th point is denoted as Fi.
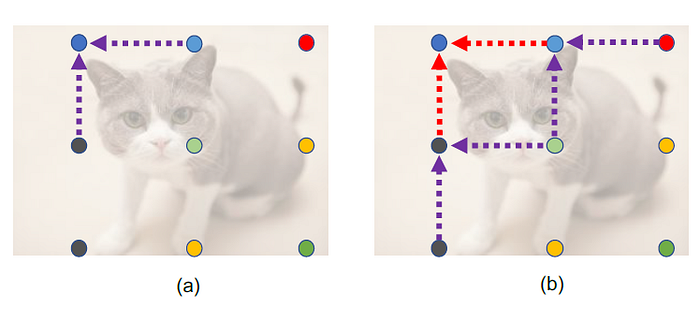
- (a) First Order: For each grid point, the points that have a L1 distance of 1 (unit grid length) will contribute to the fusion, which are called source points. The set of source points w.r.t the i-th grid point is defined as Si.
- For the j-th source point in Si, Fj will be processed by three consecutive 5×5 convolution layers for information transfer and this process is denoted as a function Tj→i.
- The processed features of all source points are then fused with Fi to obtain an fusion feature map F′i.

- Simple sum operation is used as the fusion as shown above.
- (b) Second Order: Based on F′i for each grid point, a second order of fusion is then performed with new conv layers T+j→i that don’t share parameters with those in first order of fusion.
- And the second order fused feature map F′′i is utilized to output the final heatmap for the grid point location prediction.
- The second order fusion enables an information transfer in the range of 2 (L1 distance).
- Taking the upper left grid point in 3 × 3 grids as an example (shown in (b) pf the above figure), it synthesizes the information from five other grid points for reliable calibration.
In brief, feature maps corresponding to neighbor grid points can help the current grid point for more accurate prediction, with the use of convolutional layers as equated above.
2.3. Extended Region Mapping
- An output heatmap naturally corresponds to the spatial region of the input proposal in original image.
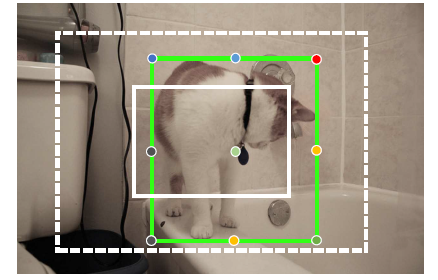
- However, a region proposal may not cover the entire object, which means some of the ground truth grid points may lie outside of the region of proposal and can’t be labeled on the supervision map or predicted during inference.
- As shown above, the proposal (the small white box) is smaller than ground truth bounding box and 7 of the 9 grid points cannot be covered by output heatmap.
- A natural idea is to enlarge the proposal area. This approach can make sure that most of the grid points will be included in proposal area, but it will also introduce redundant features of background or even other objects.
- Authors modify the relationship of output heatmaps and regions in the original image by a extended region mapping approach.
- Specifically, when the proposals are obtained, the RoI features are still extracted from the same region on the feature map without enlarging proposal area.
- While re-defining the representation area of the output heatmap as a twice larger corresponding region in the image, so that all grid points are covered in most cases as shown in the above figure (the dashed box).
- The Extended Region Mapping uses the new mapping:

In brief, when considering feature maps, only considered those in the original RoI. When considering the grid points, the extended region mapping should be used, i.e. using the above mapping equations.
3. Ablation Study
3.1. Multi-point Supervision

- The experiment of 2 points uses the supervision of upper left and bottom right corner of the ground truth box.
- In 4-point grid we add supervision of two other corner grid points.
- 9-point grid is a typical 3x3 grid formulation.
It can be observed that as the number of supervised grid points increases, the accuracy of the detection also increases.
3.2. Grid Points Feature Fusion
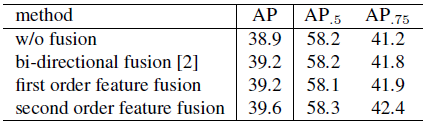
- The feature maps from the first order feature fusion stage for grid point location prediction, see a same gain of 0.3% AP as bi-directional fusion.
- The second order fusion further improves the AP by 0.4%, with a 0.7% gain from the non-fusion baseline.
- Especially, the improvement of AP0.75 is more significant than that of AP0.5, which indicates that feature fusion mechanism helps to improve the localization accuracy of the bounding box.
3.3. Extended Region Mapping
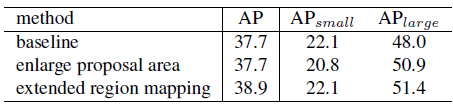
- Directly enlarging the region of proposal box for RoI feature extraction helps to cover more grid points of big objects but also brings in redundant information for small objects.
- Thus, there is a increase in APlarge but a decrease in APsmall.
- The extended region mapping strategy improves APlarge performance as well as producing no negative influences on APsmall, which leads to 1.2% improvement on AP.
4. SOTA Comparison
4.1. PASCOL VOC

4.2. COCO minival
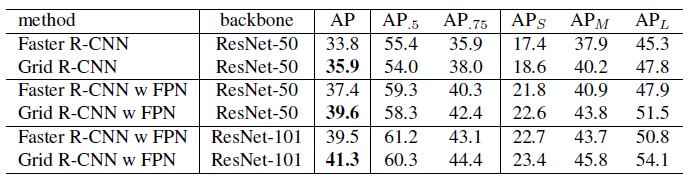
- Compared with Faster R-CNN framework, Grid R-CNN improves AP over baseline by 2.1% with ResNet-50 backbone.
- Grid R-CNN significantly improve the performance of middle and large objects by about 3 points.
4.3. COCO test-dev
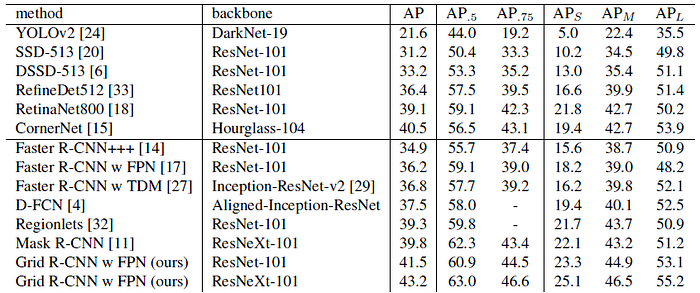
- ResNet-101 and ResNeXt-101 are adopted with FPN constructed on the top.
- Grid R-CNN achieves very competitive performance comparing with other state-of-the-art detectors.
- It outperforms Mask R-CNN by a large margin without using any extra annotations.
- Grid R-CNN also outperforms YOLOv2, SSD, DSSD, RefineDet, RetinaNet, CornerNet.
5. Further Analysis
5.1. Accuracy in Different IoU Criteria

- Grid R-CNN outperforms regression at higher IoU thresholds (greater than 0.7). The improvements over baseline at AP0.8 and AP0.9 are 4.1% and 10% respectively.
- In addition, the results of AP0.5 indicates that grid branch may slightly affect the performance of the classification branch.
5.2. Varying Degrees of Improvement in Different Categories

- The categories with the most gains usually have a rectangular or bar like shape (e.g. keyboard, laptop, fork, train, and refrigerator), while the categories suffering declines or having least gains usually have a round shape without structural edges (e.g. sports ball, frisbee, bowl, clock and cup).
- This phenomenon is reasonable since grid points are distributed in a rectangular shape.
5.3. Qualitative Results Comparison

- As shown in the figure, Grid R-CNN (in the 1st and 3rd row) has an outstanding performance in accurate localization compared with the widely used Faster R-CNN (in the 2nd and 4th row).
Reference
[2019 CVPR] [Grid R-CNN]
Grid R-CNN
Object Detection
2014: [OverFeat] [R-CNN]
2015: [Fast R-CNN] [Faster R-CNN] [MR-CNN & S-CNN] [DeepID-Net]
2016: [OHEM] [CRAFT] [R-FCN] [ION] [MultiPathNet] [Hikvision] [GBD-Net / GBD-v1 & GBD-v2] [SSD] [YOLOv1]
2017: [NoC] [G-RMI] [TDM] [DSSD] [YOLOv2 / YOLO9000] [FPN] [RetinaNet] [DCN / DCNv1] [Light-Head R-CNN] [DSOD] [CoupleNet]
2018: [YOLOv3] [Cascade R-CNN] [MegDet] [StairNet] [RefineDet] [CornerNet]
2019: [DCNv2] [Rethinking ImageNet Pre-training] [GRF-DSOD & GRF-SSD] [CenterNet] [Grid R-CNN]
