Review — context2vec: Learning Generic Context Embedding with Bidirectional LSTM
Using Bidirectional LSTM Instead of Averaging in Word2Vec
4 min readDec 4, 2021
In this story, context2vec: Learning Generic Context Embedding with Bidirectional LSTM, (context2vec), by Bar-Ilan University, is briefly reviewed. In this paper:
- A bidirectional LSTM is proposed for efficiently learning a generic context embedding function from large corpora.
This is a paper in 2016 CoNLL with over 400 citations. (Sik-Ho Tsang @ Medium)
Outline
- CBOW in Word2Vec
- Bidirectional LSTM in context2vec
- Experimental Results
1. CBOW in Word2Vec

- In brief, CBOW represents the context around a target word as a simple average of the embeddings of the context words in a window around it.
- The context window can be larger, e.g. extend to [-5, 5] to have 5 previous words and 5 future words.
- Obviously, averaging is not good enough, the weighting should be depending on the contexts around the word.
2. Bidirectional LSTM in context2vec

- A bidirectional LSTM recurrent neural network, feeding one LSTM network with the sentence words from left to right, and another from right to left.
- The parameters of these two networks are completely separate, including two separate sets of left-to-right and right-to-left context word embeddings.
- The LSTM output vector representing its left-to-right context (“John”) with the one representing its right-to-left context (“a paper”), are concatenated. With this, the relevant information in the sentential context can be captured:

- Next, this concatenated vector is fed into a multi-layer perceptron (MLP) to be capable of representing non-trivial dependencies between the two sides of the context:

- where MLP is two-layer MLP:

- Negative Sampling is used to optimize the network:
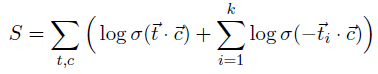
- where the summation goes over each word token t in the training corpus and its corresponding (single) sentential context c, and σ is the sigmoid function. t1, …, tk are the negative samples, independently sampled from a smoothed version of the target words unigram distribution:
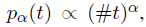
- where 0⩽α<1 is a smoothing factor, which increases the probability of rare words for Negative Sampling.
- Some details in the network:

3. Experimental Results
3.1. MSCC Corpus Development Set

- context2vec outperforms AWE, which is another SOTA approach.
- Training the proposed models with more iterations and it is found that with 3 iterations over the ukWaC corpus and 10 iterations over the MSCC corpus, some further improvement can be obsereved.
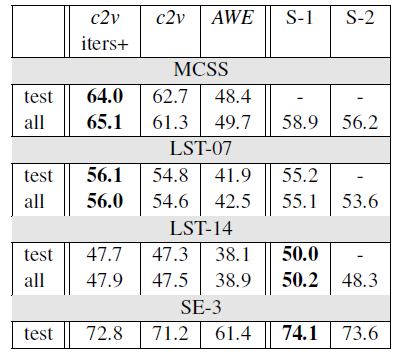
- As shown above, context2vec substantially outperforms AWE across all benchmarks.
- S-1/S-2 stand for the best/second-best prior result reported for the benchmark. context2vec either surpass or almost reach the state-of-the-art on all benchmarks.
3.2. Others
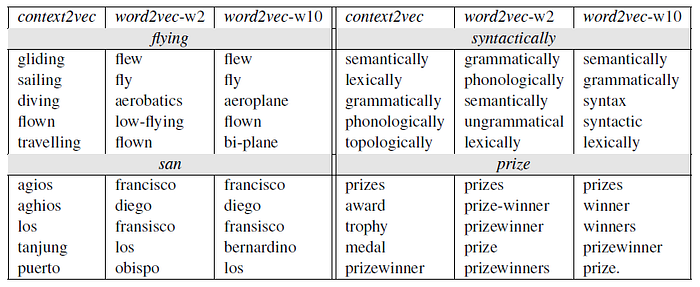
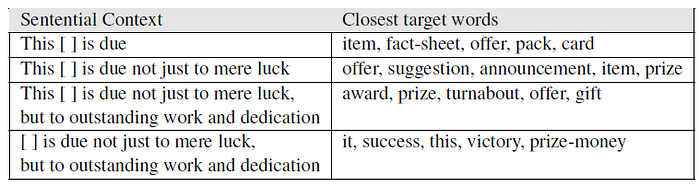
- The above table illustrates context2vec’s sensitivity to long range dependencies, and both sides of the target word.
Reference
[2016 CoNLL] [context2vec]
context2vec: Learning Generic Context Embedding with Bidirectional LSTM
Natural Language Processing (NLP)
Language Model: 2007 [Bengio TNN’07] 2013 [Word2Vec] [NCE] [Negative Sampling] 2014 [GloVe] [GRU] [Doc2Vec] 2015 [Skip-Thought] 2016 [GCNN/GLU] [context2vec]
Machine Translation: 2014 [Seq2Seq] [RNN Encoder-Decoder] 2015 [Attention Decoder/RNNSearch] 2016 [GNMT] [ByteNet] [Deep-ED & Deep-Att] 2017 [ConvS2S] [Transformer]
Image Captioning: 2015 [m-RNN] [R-CNN+BRNN] [Show and Tell/NIC] [Show, Attend and Tell]
