Review — gMLP: Pay Attention to MLPs
gMLP, for Both Computer Vision & Natural Language Processing
Pay Attention to MLPs,
gMLP, by Google Research, Brain Team,
2021 NeurIPS, Over 130 Citations (Sik-Ho Tsang @ Medium)
Image Classification, Natural Language Processing, NLP, Language Model, LM, BERT, Transformer, Vision Transformer, ViT
- gMLP, based on MLPs with gating, is proposed to replace the self-attention in Transformer, which can perform as good as Transformers in key language and vision applications.
Outline
- gMLP Design Purpose
- Spatial Gating Unit (SGU)
- Image Classification Results
- NLP Results
- aMLP: gMLP with Attention Results
1. gMLP Design Purpose
- gMLP, consists of a stack of L blocks with identical size and structure.
- Let X be the token representations with sequence length n and dimension d. Each block is defined as:

- where σ is an activation function such as GELU. U and V define linear projections along the channel dimension — the same as those in the FFNs of Transformers.
- The key ingredient is s(), a layer which captures spatial interactions. (When s is an identity mapping, the above transformation degenerates to a regular FFN.)
The major focus is therefore to design a good s capable of capturing complex spatial interactions across tokens.
- The overall block layout is inspired by inverted bottlenecks in MobileNetV2, which define s() as a spatial depthwise convolution.
- Unlike Transformers, the proposed model does not require position embeddings because such information will be captured in s().
2. Spatial Gating Unit (SGU)
2.1. SGU

- To enable cross-token interactions, it is necessary for the layer s() to contain a contraction operation over the spatial dimension. The simplistic option would be a linear projection:

- Unlike self-attention where W(Z) is dynamically generated from Z, the spatial projection matrix W is independent from the input representations.
- s() is formulated as the output of linear gating:

- where ⊙ denotes element-wise multiplication. For training stability, it is critical to initialize W as near-zero values and b as ones.
- It is further found to be effective to split Z into two independent parts (Z1, Z2) along the channel dimension for the gating function and for the multiplicative bypass:

- Also, normalizing the input to fW,b empirically improves stability of large NLP models.
2.2. Connections to Existing Layers
- The overall formulation of SGU resembles Gated Linear Units (GLUs) [26, 27, 28] as well as earlier works including Highway Networks [29] and LSTM-RNNs.
- SGU is also related to Squeeze-and-Excite (SE) blocks in SENet [30] in terms of element-wise multiplication. However, different from SE blocks, SGU does not contain cross-channel projections.
3. Image Classification Results

- The input and output protocols follow ViT/B16 where the raw image is converted into 16×16 patches at the stem. Regularization is used as in DeiT.
- 3 gMLP variants are designed for image classification.
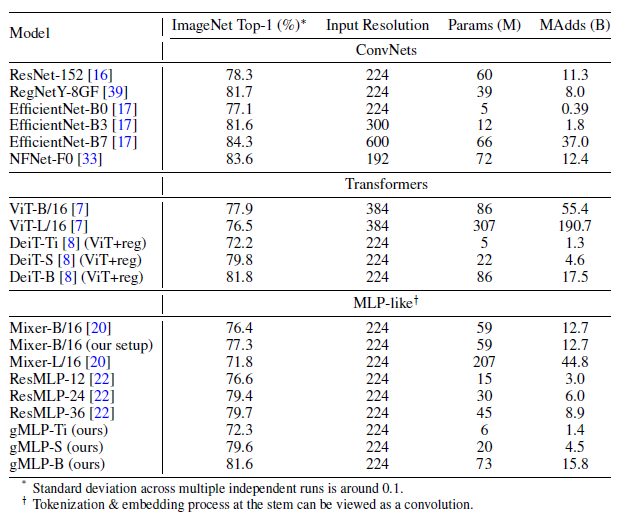
- While gMLPs are competitive with vanilla Transformers, i.e. ViT, their performance is behind the best existing ConvNet models, e.g.: EfficientNet, or hybrid models.
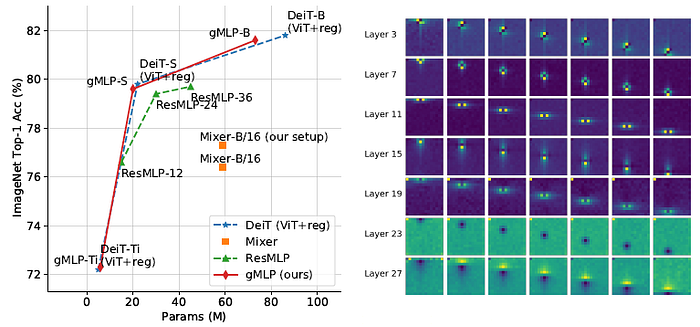
Left: gMLPs are comparable with DeiT. The results suggest that models without self-attention can be as data-efficient as Transformers for image classification.
Moreover, the accuracy-parameter/FLOPs tradeoff of gMLPs surpasses all concurrently proposed MLP-like architectures, e.g.: MLP-Mixer, and ResMLP.
- Right: Each spatial projection matrix effectively learns to perform convolution with a data-driven, irregular (non-square) kernel shape.
4. NLP Results


First, SGU outperforms other variants in perplexity.
Secondly and remarkably, gMLP with SGU also achieves perplexity comparable to Transformer.
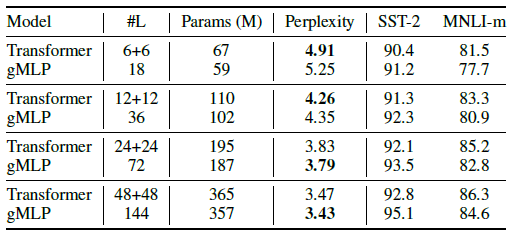
The results above show that a deep enough gMLP is able to match and even outperform the perplexity of Transformers with comparable capacity.
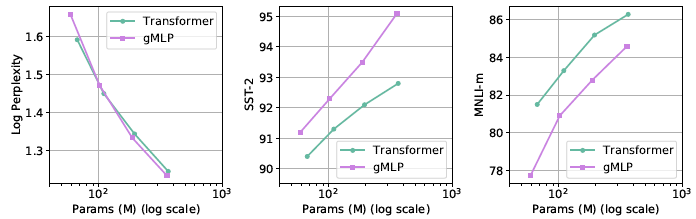
Despite the architecture-specific discrepancies between pretraining and finetuning, gMLPs and Transformers exhibit comparable scalability (slope) on both finetuning tasks.
5. aMLP: gMLP with Attention Results

- To isolate the effect of self-attention, a hybrid model is designed where a tiny self-attention block is attached to the gating function of gMLP, named as aMLP (“a” for attention).
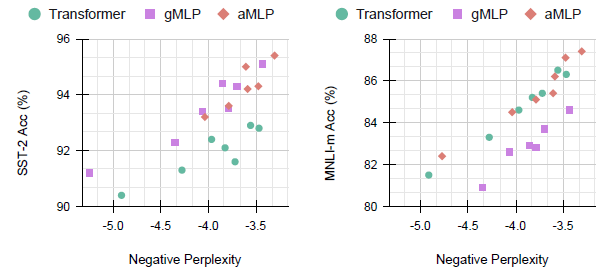
gMLPs transfer better to SST-2 than Transformers regardless of the presence of self-attention, while gMLP performs worse on MNLI, attaching a tiny bit of self-attention is sufficient to close the gap.
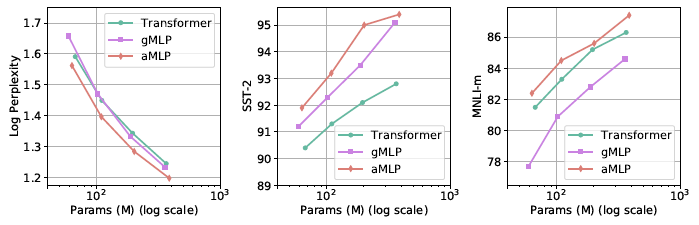
Putting together the scaling properties of the three models, showing that aMLP (gMLP + tiny attention) consistently outperforms Transformer on both finetuning tasks.
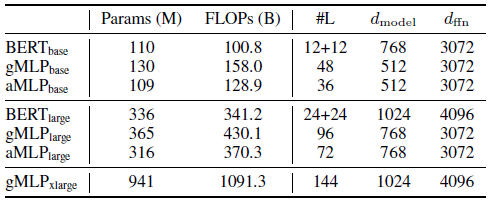
- Using BERT base and large models as basis, gMLP and aMLP are constructed.
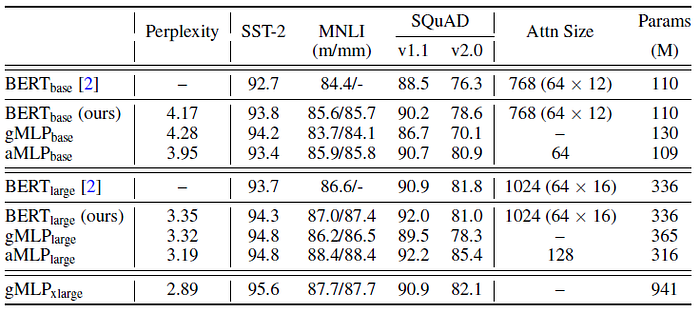
gMLPs are competitive with Transformers in terms of perplexity, especially in the larger scale setup.
- On finetuning tasks where gMLPs underperform Transformers, the performance gap tends to narrow as the model capacity increases.
One additional data point is added by scaling up gMLP even further. The resulting model, gMLPxlarge, outperforms BERTlarge on SQuAD-v2.0 — a difficult task involving question-answer pairs — without any self-attention.
aMLP: Blending in a tiny single-head self-attention of size either 64 or 128 is sufficient to make gMLPs outperform Transformers of similar capacity, sometimes by a significant margin.
Reference
[2021 NeurIPS] [gMLP]
Pay Attention to MLPs
1.1. Image Classification
1989 … 2021 [gMLP] … 2022 [ConvNeXt] [PVTv2] [ViT-G] [AS-MLP] [ResTv2] [CSWin Transformer] [Pale Transformer]
2.1. Language Model / Sequence Model
(Some are not related to NLP, but I just group them here)
1991 … 2020 [ALBERT] [GPT-3] [T5] [Pre-LN Transformer] [MobileBERT] [TinyBERT] [BART] [Longformer] [ELECTRA] [Megatron-LM] [SpanBERT] 2021 [Performer] [gMLP]
