Review — Learning to Summarize From Human Feedback
A lot of Procedures is Followed Here to Train InstructGPT. And ChatGPT is One Sibling Model of InstructGPT
Learning to Summarize From Human Feedback,
Human Feedback Model, by OpenAI
2020 NeurIPS, Over 160 Citations (Sik-Ho Tsang @ Medium)
NLP, Large Language Model, LLM, InstructGPT, ChatGPT, GPT-3, Transformer
- To improve summary quality that is aligned to human preferences, a large and high-quality dataset of human comparisons between summaries is collected.
- Using the above dataset, the GPT model is used to predict the human-preferred summary.
- This supervised-trained model is used as a reward function to fine-tune a summarization policy using reinforcement learning.
- This paper has been treated as a basis for InstructGPT. A lot of procedures is followed here to train InstructGPT. And ChatGPT, the very hot AI topic right now, is one sibling model of InstructGPT.
Outline
- TL;DR Dataset & GPT-3-Styled Model
- Proposed Human Feedback Model
- Results
1. TL;DR Dataset & GPT-3-Styled Model
1.1. TL;DR Dataset

- The TL;DR summarization dataset [63], which contains ~3 million posts from Reddit, is used.
- The final filtered dataset contains 123,169 posts, and ~5% is held out as a validation set, as TL;DR used in this paper.
1.2. GPT-3-Styled Model
- All of the models are Transformer decoders in the style of GPT-3.
- Two model sizes of 1.3 billion (1.3B) and 6.7 billion (6.7B) parameters are considered.
2. Proposed Human Feedback Model
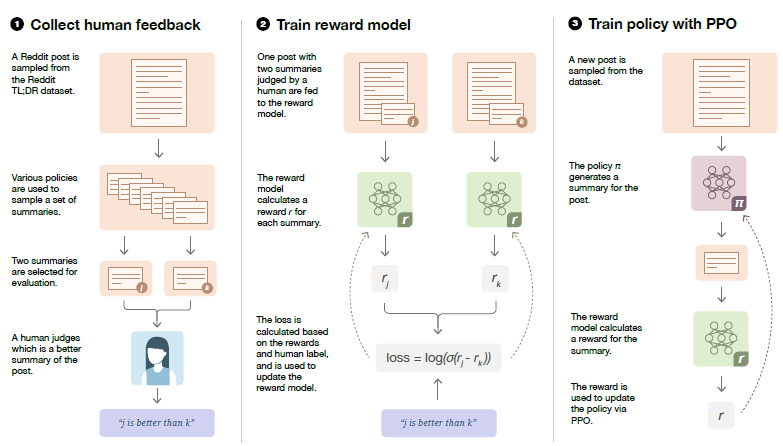
Step 1: Collect samples from existing policies and send comparisons to humans.
- For each Reddit post, summaries are sampled from several sources including the current policy, initial policy, original reference summaries and various baselines.
- A batch of pairs of summaries is sent to the human evaluators, who are tasked with selecting the best summary of a given Reddit post.
- The data collection procedure is expensive.
Step 2: Learn a reward model from human comparisons.
- Given a post and a candidate summary, a reward model is trained to predict the log odds that this summary is the better one, as judged by the human labelers.
- Specifically, start from a supervised baseline, as described above, a randomly initialized linear head is added that outputs a scalar value.
- This model is trained to predict which summary y ∈ {y0, y1} is better as judged by a human, given a post x. If the summary preferred by the human is yi, the RM loss is written as as:

- where rθ(x, y) is the scalar output of the reward model for post x and summary y with parameters θ, and D is the dataset of human judgments.
Step 3: Optimize a policy against the reward model.
- The logit output of the reward model is treated as a reward for optimization using reinforcement learning, specifically with the PPO algorithm [58].
- A term in the reward is added that penalizes the KL divergence between the learned πφRL policy RL with parameters φ and this original supervised model πSFT.
- The full reward R is written as:
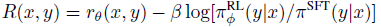
- This KL term serves two purposes:
- First, it acts as an entropy bonus, encouraging the policy to explore and deterring it from collapsing to a single mode.
- Second, it ensures the policy doesn’t learn to produce outputs that are too different from those that the reward model has seen during training.
- For the PPO value function, a Transformer is used, with completely separate parameters from the policy. This prevents updates to the value function from partially destroying the pretrained policy early in training.
- The reward model, policy, and value function are of the same size.
- Fine-tuning the 6.7B model with RL required approximately 320 GPU-days.
3. Results
3.1. Summarizing Reddit Posts from Human Feedback

Policies trained with human feedback are preferred to much larger supervised policies.
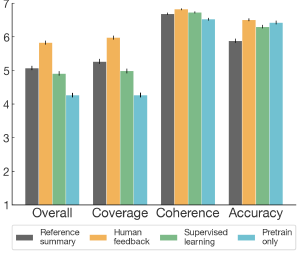
- An additional analysis where human labelers assess summary quality across four dimensions (or “axes”) using a 7-point Likert scale.
The human feedback models outperform the supervised baselines across every dimension of quality, but particularly coverage.
3.2. Transfer to Summarizing News Articles
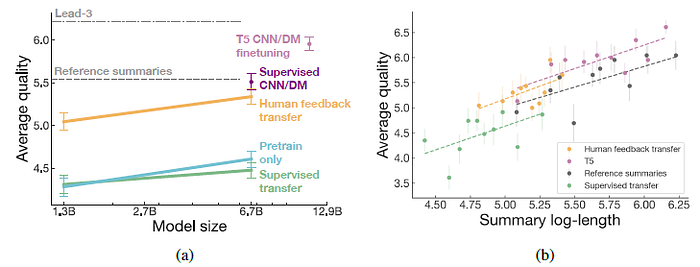
Left: In fact, the proposed 6.7B human feedback model performs almost as well as a 6.7B model that was fine-tuned on the CNN/DM reference summaries, despite generating much shorter summaries.
- Right: The human feedback models transferred to CNN/DM have little overlap in summary length distribution with models trained on CNN/DM, they are difficult to compare directly.
Qualitatively, CNN/DM summaries from the proposed human feedback models are consistently fluent and reasonable representations of the article.
3.3. Understanding the Reward Model
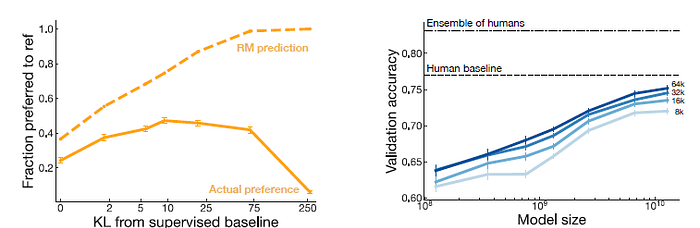
- The reward model isn’t a perfect representation of the labeler preferences, as it has limited capacity and only sees a small amount of comparison data from a relatively narrow distribution of summaries, while we can hope the reward model generalizes to summaries unseen during training.
- Left: The the results for PPO at a range of KL penalty coefficients (β).
- Under light optimization, the models improve (according to labelers). However, as optimizing further, true preferences fall off compared to the prediction, and eventually the reward model becomes anti-correlated with human preferences.
- Right: 7 reward models are trained ranging from 160M to 13B parameters, on 8k to 64k human comparisons from the proposed dataset.
Doubling the training data amount leads to a ~1.1% increase in the reward model validation set accuracy, whereas doubling the model size leads to a ~1.8% increase.
3.4. Analyzing Automatic Metrics for Summarization
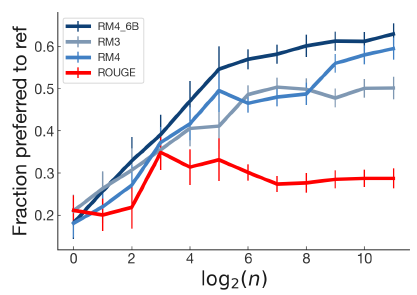
Optimizing ROUGE using a simple optimization scheme doesn’t consistently increase quality while the learned reward models consistently outperform other metrics.
Authors also mentioned about limitations, future directions, and impacts. Please feel free to read the paper directly if interested.
Reference
[2020 NeurIPS] [Human Feedback Model]
Learning to Summarize From Human Feedback
2.1. Language Model / Sequence Model
(Some are not related to NLP, but I just group them here)
1991 … 2020 [ALBERT] [GPT-3] [T5] [Pre-LN Transformer] [MobileBERT] [TinyBERT] [BART] [Longformer] [ELECTRA] [Megatron-LM] [SpanBERT] [UniLMv2] [Human Feedback Model] 2021 [Performer] [gMLP] [Roformer] 2022 [GPT-NeoX-20B] [InstructGPT]
