Review — ResT: An Efficient Transformer for Visual Recognition
ResT / ResTv1, Design Efficient Multi-Head Self-Attention (EMSA) Using Depth-Wise Convolution
ResT: An Efficient Transformer for Visual Recognition,
ResT, ResTv1, by Nanjing University,
2021 NeurIPS, Over 60 Citations (Sik-Ho Tsang @ Medium)
Image Classification, Vision Transformer, ViT, Transformer
- Standard Transformer tackles fixed-resolution images only. ResT is proposed, which has 3 advantages:
- A memory-efficient multi-head self-attention is built, which compresses the memory by a simple depth-wise convolution, and projects the interaction across the attention-heads dimension while keeping the diversity ability of multi-heads.
- Positional encoding is constructed as spatial attention, which is more flexible and can tackle with input images of arbitrary size without interpolation or fine-tune.
- Instead of the straightforward tokenization at the beginning of each stage, the patch embedding is designed as a stack of overlapping convolution operation with stride on the token map.
Outline
- ResT Model Architecture
- Efficient Multi-Head Self-Attention (EMSA), Patch Embedding, & Pixel Attention (PA) as Position Encoding
- Experimental Results
1. ResT Model Architecture


ResT shares exactly the same pipeline as ResNet, a stem module applied followed by four stages. Each stage consists of three components, 1) one patch embedding module (or stem module), 2) one positional encoding module, and 3) a set of L efficient Transformer blocks.
- At the beginning of each stage, the patch embedding module is adopted to reduce the resolution of the input token and expanding the channel dimension.
- The positional encoding module is fused to restrain position information and strengthen the feature extracting ability of patch embedding.
2. Efficient Multi-Head Self-Attention (EMSA), Patch Embedding, & Pixel Attention (PA) as Position Encoding
2.1. Efficient Multi-Head Self-Attention (EMSA)
- Original MSA has two shortcomings: (1) The computation scales quadratically with dm or n according to the input token. (2) Each head in MSA only responsible for a subset of embedding dimensions.

To compress memory, the 2D input token is reshaped into 3D token, and then is fed to a depth-wise convolution (Conv) operation to reduce the height and width dimension by a factor s.
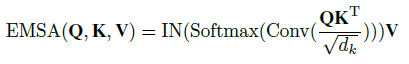
To restore this diversity ability, Instance Normalization (IN) is added for the dot product matrix (after Softmax).
- Finally, the output values of each head are then concatenated and linearly projected to form the final output.
- FFN is added after EMSA for feature transformation and non-linearity.
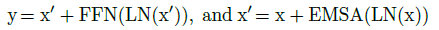
2.2. Patch Embedding
A simple but effective way, i.e, stacking three 3×3 standard convolution layers (all with padding 1) with stride 2, stride 1, and stride 2, respectively.
- Batch Normalization and ReLU activation are used for the first 2 layers.
2.3. Pixel Attention (PA) as Position Encoding
- In ViT, a set of learnable parameters are added into the input tokens to encode positions.
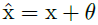
- The length of positions is exactly the same as the input tokens length, which limits the application scenarios.
A simple yet effective spatial attention module calling Pixel Attention (PA) is use to encode positions. Specifically, PA applies a 3×3 depth-wise convolution (with padding 1) operation to get the pixel-wise weight and then scaled by a sigmoid function σ.
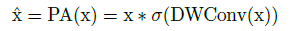
2.4. ResT Model Variants
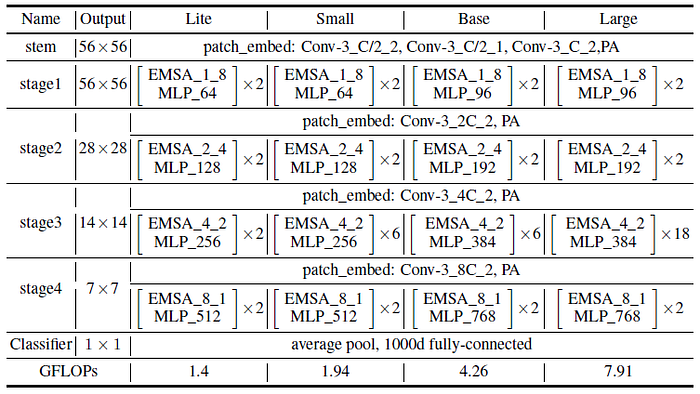
- Lite, Small, Base, Large versions are developed.
3. Experimental Results
3.1. ImageNet-1k

The proposed ResT achieves significant improvement by a large margin.
- For example, for smaller models, ResT noticeably surpass the counterpart PVT architectures with similar complexities: +4.5% for ResT-Small (79.6%) over PVT-T (75.1%).
- For larger models, ResT also significantly outperform the counterpart Swin architectures with similar complexities: +0.3% for ResT-Base (81.6%) over Swin-T (81.3%), and +0.3% for ResT-Large (83.6%) over Swin-S(83.3%) using 224×224 input.
- Compared with RegNet, the ResT with similar model complexity also achieves better performance.
3.2. MS COCO
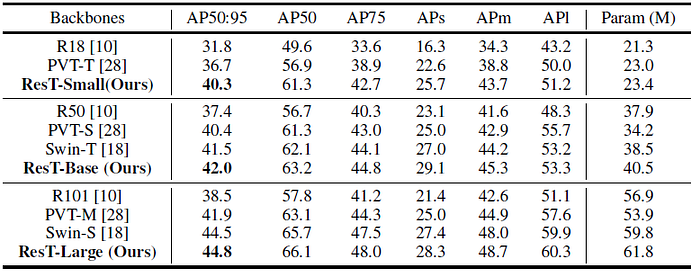
- For smaller models, ResT-Small is +3.6 box AP higher (40.3 vs. 36.7) than PVT-T with a similar computation cost.
- For larger models, our ResT-Base surpassing the PVT-S by +1.6 box AP.
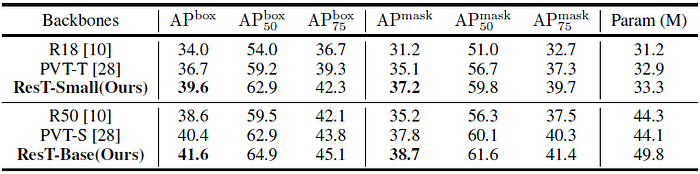
- Rest-Small exceeds PVT-T by +2.9 box AP and +2.1 mask AP on the COCO val2017 split.
- As for larger models, ResT-Base brings consistent +1.2 and +0.9 gains over PVT-S in terms of box AP and mask AP, with slightly larger model size.
3.3. Ablation Study

- Left: The stem module in the proposed ResT is more effective than that in PVT and ResNet: +0.92% and +0.64% improvements in terms of Top-1 accuracy, respectively.
- Right: As can be seen, average pooling achieves slightly worse results (-0.24%) compared with the original Depth-wise Conv2d, while the results of the Max Pooling strategy are the worst.
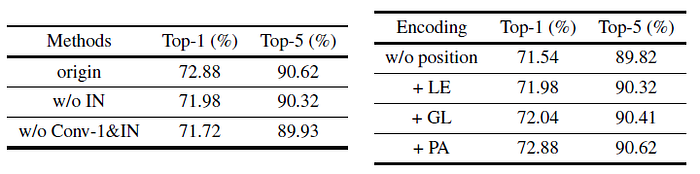
- Left: Without IN, the Top-1 accuracy is degraded by 0.9%. In addition, the performance drops 1.16% without the convolution operation and IN.
- Right: PA mode significantly surpasses others, achieving 0.84% Top-1 accuracy improvement.
Later, ResTv2 is invented.
Reference
[2021 NeurIPS] [ResT]
ResT: An Efficient Transformer for Visual Recognition
1.1. Image Classification
1989 … 2021 [ResT] … 2022 [ConvNeXt] [PVTv2] [ViT-G] [AS-MLP]
