Review — Swish: Searching for Activation Functions
Swish: f(x)=x • sigmoid(βx)

Searching for Activation Functions
Swish, by Google Brain
2018 ICLRW, Over 1600 Citations (Sik-Ho Tsang @ Medium)
Activation Function, Image Classification, Neural Machine Translation, Natural Language Processing, NLP
- Search space is defined to search for a better activation function.
- Finally, Swish is come up with better performance than ReLU.
Outline
- Search Space
- NAS Search
- Experimental Results
1. Search Space

A simple search space is designed that composes unary and binary functions to construct the activation function.
- The activation function is composed of multiple repetitions of the “core unit”, which consists of two inputs, two unary functions, and one binary function.

- Unary functions take in a single scalar input and return a single scalar output, such u(x)=x² or u(x)=σ(x).
- Binary functions take in two scalar inputs and return a single scalar output, such as b(x1, x2)=x1•x2 or b(x1, x2)=exp(-(x1-x2)²).
2. NAS Search

RNN controller, as in NASNet, is used to select the optimal operations in the large search space.
- At each timestep, the controller predicts a single component of the activation function. The prediction is fed back to the controller in the next timestep, and this process is repeated until every component of the activation function is predicted. The predicted string is then used to construct the activation function.
- A “child network” with the candidate activation function is trained on some task, such as image classification on CIFAR-10. After training, the validation accuracy of the child network is recorded and used to update the search algorithm.
- ResNet-20 is used as child on CIFAR-10.

- The above figure plots the top performing novel activation functions found by the searches.
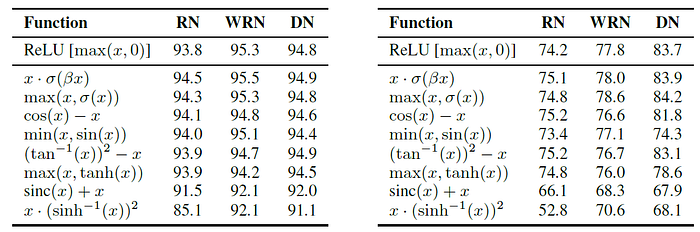
- ResNet, WRN, and DenseNet are used for evaluation.
- Complicated activation functions consistently underperform simpler activation functions, potentially due to an increased difficulty in optimization.
The best performing activation functions can be represented by 1 or 2 core units.
- Functions that use division tend to perform poorly because the output explodes when the denominator is near 0.
- Six of the eight activation functions successfully generalize. Of these six activation functions, all match or outperform ReLU on ResNet-164.
Furthermore, two of the discovered activation functions, x•σ(βx) and max(x,σ(x)), consistently match or outperform ReLU on all three models.
Finally, x•σ(βx), which called Swish, is chosen, where σ is sigmoid function and β and is either a constant or a trainable parameter.
3. Experimental Results
3.1. Swish Benchmarking

- Swish is benchmarked against ReLU and a number of recently proposed activation functions on challenging datasets, and it is found that Swish matches or exceeds the baselines on nearly all tasks.
3.2. CIFAR
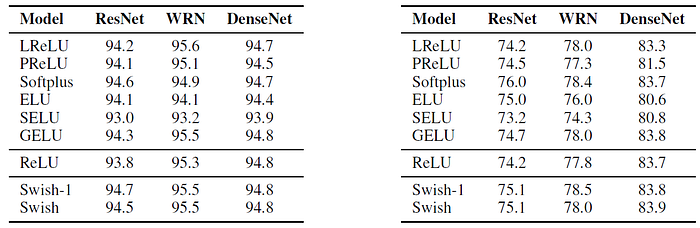
- Swish is with a trainable β and Swish-1 is with a fixed β=1.
Swish and Swish-1 consistently matches or outperforms ReLU on every model for both CIFAR-10 and CIFAR-100.
3.3. ImageNet
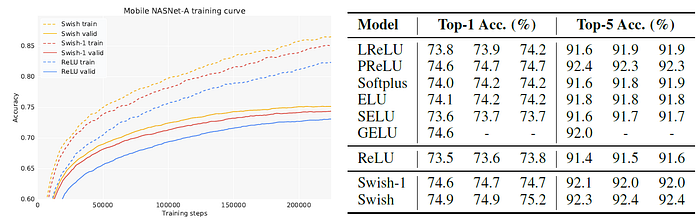
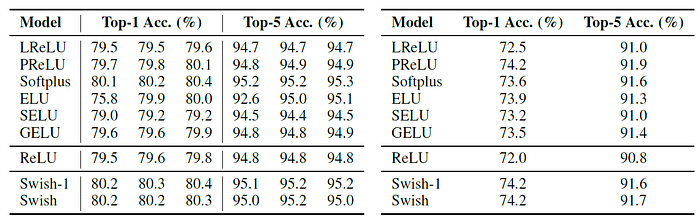
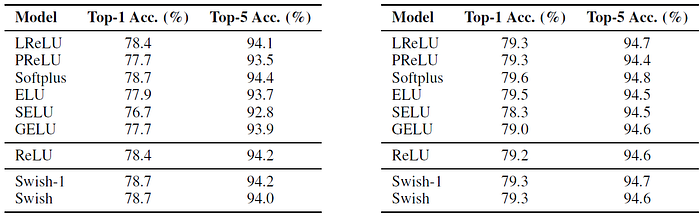
The above figure and 5 tables shows the strong performance of Swish.
3.4. WMT 2014 English→German Machine Translation
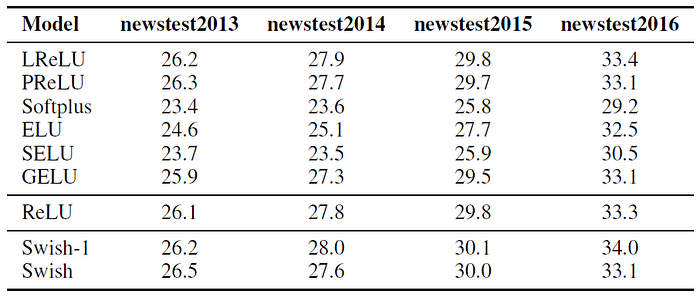
- Swish outperforms or matches the other baselines on machine translation.
Reference
[2018 ICLRW] [Swish]
Searching for Activation Functions
Image Classification
1989–2019 … 2020: [Random Erasing (RE)] [SAOL] [AdderNet] [FixEfficientNet] [BiT] [RandAugment] [ImageNet-ReaL]
2021: [Learned Resizer] [Vision Transformer, ViT] [ResNet Strikes Back] [DeiT] [EfficientNetV2]