Review —ViL: Multi-Scale Vision Longformer A New Vision Transformer for High-Resolution Image Encoding
Using Idea From Longformer in NLP, for Computer Vision Tasks
Multi-Scale Vision Longformer A New Vision Transformer for High-Resolution Image Encoding,
ViL, by Microsoft Corporation
2021 ICCV, Over 100 Citations (Sik-Ho Tsang @ Medium)
Image Classification, Vision Transformer, Transformer, Longformer
- Multi-Scale Vision Longformer with 2 techniques is proposed:
- The first is the multi-scale model structure, which provides image encodings at multiple scales with manageable computational cost.
- The second is the attention mechanism of Vision Longformer, which is a variant of Longformer.
Outline
- Multi-Scale Model Architecture
- Vision Longformer: A “Local Attention + Global Memory” Mechanism
- Comparisons With Other Attention Approaches
- Experimental Results
1. Multi-Scale Model Architecture

- Efficient ViT (E-ViT) is modified from ViT:
- Layer Normalization (LayerNorm) is added after the patch embedding.
- A number of global tokens, including the CLS token, is included. The the tokens associated image and feature patches are referred to as local tokens afterwards..
- The vanilla full self-attention is replaced with an efficient attention mechanism, denoted as a.
- An Absolute 2-D Positional Embedding (APE for short, separately encoding x and y coordinates and concatenating them) or a Relative Positional Bias (RPB for short) to replace the original absolute 1-D positional embedding:

- where LN is the added Layer Normalization after the patch embedding E, MSAa is the multi-head self-attention with attention type a, MLP is the multi layer perceptron.
- By stacking Multiple E-ViT Modules, Multi-Scale Vision Transformer is formed.
- Except for attention a, E-ViT has the following architecture parameters inherited from the vanilla ViT: input patch size p, number of attention blocks n, hidden dimension d and number of heads h, denoted as E-ViT(a×n/p; h, d, ng).
- The deficient E-ViT(full×12/16; h, d, 1) (full: full self-attention) models still achieve better ImageNet classification performance than the baseline ViT for both tiny and small model sizes.
2. Vision Longformer: A “Local Attention + Global Memory” Mechanism

2.1. 2-D Vision Longformer
- The 2-D Vision Longformer is an extension of the 1-D Longformer originally developed for NLP tasks.
- ng global tokens (including the CLS token) are added that are allowed to attend to all tokens, serving as global memory.
- Local tokens are allowed to attend to only global tokens and their local 2-D neighbors within a window size.
- After all, there are four components in this “local attention + global memory” mechanism, namely global-to-global, local-to-global, global-to-local, and local-to-local.
- Vision Longformer attention mechanism is denoted as MSAViL, i.e., a=ViL in Eq. (2) above.
2.2. Relative Positional Bias
- Following UniLMv2 [2], T5, and Swin Transformer, a relative positional bias B is added to each head when computing the attention score:
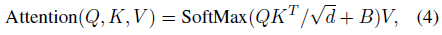
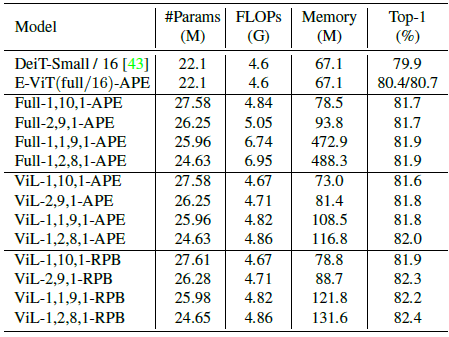
The deficient E-ViT outperforms ViT-variant DeiT. With full self-attention and APE, further improvement is observed. ViL With RPB, even further improvement is observed.
2.3. Random-Shifting Training Strategy

- At the beginning, instead of attending to all 8 neighbor patches, one patch can only attend to itself and one random neighbor patch during training.
- This random-shifting mode is switch to the default 8-neighbor mode after x% training iterations, and this switch time x% is a hyper-parameter with default value 75%. This switch, can be seen as fine-tuning.
This random-shifting training strategy accelerates the Vision Longformer training significantly, while not harming the final model performance.
3. Comparisons With Other Attention Approaches

3.1 ImageNet Performance
- ViL outperforms other attention-based ViTs.
One possible reason is that the conv-like sparsity is a good inductive bias for Vision Transformers, compared with other attention mechanisms. Another explanation is that Vision Longformer keeps the key and value feature maps high resolution.
- However, low resolution-based attention mechanism like Linformer and SRA and pure global attention lose the high-resolution information in the key and value feature maps.
- For mixed attention mechanisms (Partial X-former, Par), efficient attention is used in the first two stages and to use full attention in the last two stages. All these Partial X-formers perform well on ImageNet classification, with very little (even no) gap between Full Attention and Vision Longformer. These Partial X-forms achieve very good accuracy-efficiency performance for low-resolution classification tasks.
3.2. Transfer to High-Resolution Tasks
- However, Linformer is not transferable as it is specific to a resolution.
- The Partial X-formers and Multi-scale ViT with full attention are not transferable due to its prohibitively large memory usage after transferred to high-resolution tasks.
4. Experimental Results
4.1. ImageNet-1K

The proposed ViLs outperform other models in the same scale by a large margin. The relative positional bias (RPB) outperforms the absolute 2-D positional embedding (APE) on ViL. When compared with Swin Transformers, ViLs still perform better with fewer parameters.
4.2. ImageNet-1K, Pretrained on ImageNet-21K
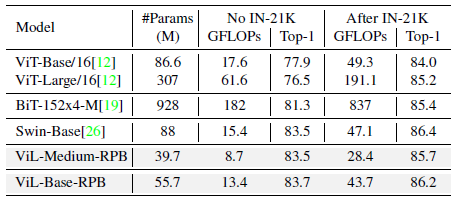
The performance gets significantly boosted after ImageNet-21K pretraining for both ViL medium and base models.
- The performance of ViL-Medium model has surpassed that of ViT-Base/16, ViT-Large/16 and BiT-152x4-M, in the ImageNet-21K pretraining setting.
4.3. Object Detection
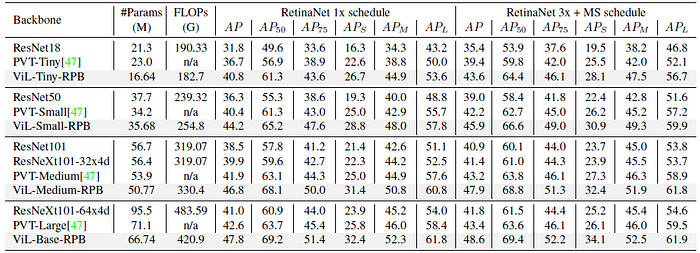
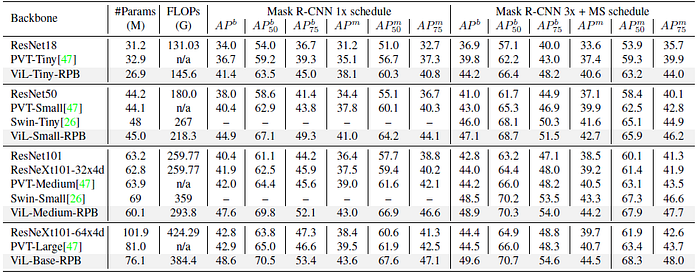
- To adapt the learned relative positional bias to the higher image resolution in detection, bilinear interpolation is performed prior to training.
ViL backbone significantly surpasses ResNet and PVT baselines on both object detection and instance segmentation.
4.4. Ablation Study
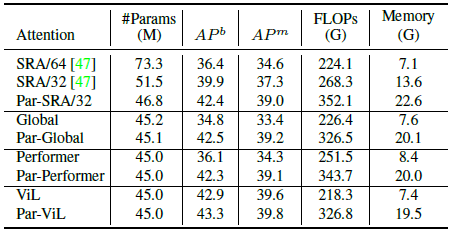
- ViL achieves much better performance than the other three mechanisms.
The “local attention + global memory” mechanism in Vision Longformer can retain the good performance of the full attention mechanism in ViT, and that it is a clear better choice than other efficient attention mechanisms for high-resolution vision tasks.

- Left: The window size plays a crucial role and the default window size 15 gives the best performance.
- Right: As long as there is one global token, adding more global tokens does not improve the performance any more.
By using Longformer concept that originated in NLP, ViL is invented.
Reference
[2021 ICCV] [ViL]
Multi-Scale Vision Longformer A New Vision Transformer for High-Resolution Image Encoding
1.1. Image Classification
1989 … 2021 [ViL] … 2022 [ConvNeXt] [PVTv2] [ViT-G] [AS-MLP]