Review — ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
VilBERT (Vision-and-Language BERT)
ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks, ViLBERT, by Georgia Institute of Technology, Oregon State University, and Facebook AI Research
2019 NeurIPS, Over 1400 Citations (Sik-Ho Tsang @ Medium)
Vision Language Model (VLM), BERT, Transformer
- ViLBERT (short for Vision-and-Language BERT) is proposed for learning task-agnostic joint representations of image content and natural language.
- The popular BERT architecture is extended to a multi-modal two-stream model, processing both visual and textual inputs in separate streams that interact through co-attentional Transformer layers.
Outline
- ViLBERT (Vision-and-Language BERT)
- Training Tasks and Objectives
- Experimental Results
1. ViLBERT (Vision-and-Language BERT)

1.1. ViLBERT: Extending BERT to Jointly Represent Images and Text
- ViLBERT model consists of two parallel BERT-style streams for visual (green) and linguistic (purple) processing that interact through novel co-attentional Transformer layers.
- This structure allows for variable depths for each modality and enables sparse interaction through co-attention.
- Each stream is a series of Transformer blocks (TRM) and novel co-attentional Transformer layers (Co-TRM).
Given an image I represented as a set of region features v1, .., vT and a text input w0, .., wT, the model outputs final representations hv0, …, hvT and hw0, …, hwT.
1.2. Co-Attentional Transformer Layers
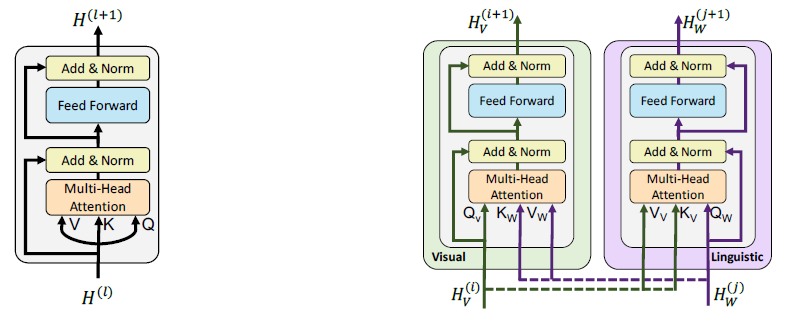
- Given intermediate visual and linguistic representations H(i)V and H(j)W, the module computes query, key, and value matrices as in a standard Transformer block. However, the keys and values from each modality are passed as input to the other modality’s multi-headed attention block.
The attention block produces attention-pooled features for each modality conditioned on the other — in effect performing image-conditioned language attention in the visual stream and language-conditioned image attention in the linguistic stream.
2. Training Tasks and Objectives

- Two pretraining tasks are considered: masked multi-modal modelling and multi-modal alignment prediction.
2.1. Masked Multi-Model Modelling
- Masking approximately 15% of both words and image region inputs and tasking the model with reconstructing them given the remaining inputs.
- Masked image regions have their image features zeroed out 90% of the time and are unaltered 10%.
- Masked text inputs are handled as in BERT.
- Rather than directly regressing the masked feature values, the model instead predicts a distribution over semantic classes for the corresponding image region. To supervise this, the output distribution for the region is taken from the same pretrained detection model used in feature extraction. The model is trained to minimize the KL divergence between these two distributions.
2.2. Multi-Modal Alignment Prediction
- The model is presented an image-text pair as:
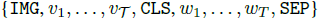
- and must predict whether the image and text are aligned, i.e. whether the text describes the image.
- The outputs hIMG and hCLS are taken as holistic representations of the visual and linguistic inputs. The overall representation is taken as an element-wise product between hIMG and hCLS and a linear layer is learnt to make the binary prediction whether the image and text are aligned.
- However, the Conceptual Captions dataset only includes aligned image-caption pairs. To generate negatives for an image-caption pair, either the image or caption is randomly replaced with another.
2.3. Training VILBERT
- Conceptual Captions dataset is used for training.
- For linguistic stream, BERTBASE model is used, which has 12 layers of Transformer blocks with each block having a hidden state size of 762 and 12 attention heads.
- It is pretrained on the BookCorpus and English Wikipedia.
- For visual stream, Faster R-CNN (with ResNet-101 backbone) is used, which pretrained on the Visual Genome dataset to extract region features.
- Regions are selected where class detection probability exceeds a confidence threshold and keep between 10 to 36 high-scoring boxes.
- For each selected region i, vi is defined as the mean-pooled convolutional feature from that region.
- Transformer and co-attentional Transformer blocks in the visual stream have hidden state size of 1024 and 8 attention heads.
- 8 TitanX GPUs with a total batch size of 512 are used for training 10 epochs.
3. Experimental Results
3.1. SOTA Comparisons

- Single-Stream consisting of a single BERT architecture that processes both modality inputs through the same set of transformer blocks — sharing parameters and processing stacks for both visual and linguistic inputs.
VILBERT improves performance over a single-stream model.
- The proposed models further improve by between 2% and 13% across tasks when using a ViLBERT model that has been pretrained under our proxy tasks (ViLBERT vs ViLBERT+).
Pretraining tasks result in improved visiolinguistic representations.
3.1. Effect of Visual Stream Depth

VQA and Image Retrieval tasks benefit from greater depth — performance increases monotonically until a layer depth of 6.
3.2. Benefits of Large Training Sets

Accuracy grows monotonically as the amount of data increases from 0% to 100%.
VILBERT, a task-agnostic BERT-style pretraining architecture, extracting features in visual and linguistic streams, and attending to each other, is designed.
Reference
[2019 NeurIPS] [ViLBERT]
ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
5.1. Visual/Vision/Video Language Model (VLM)
2019 [VideoBERT] [VisualBERT] [LXMERT] [ViLBERT] 2020 [ConVIRT]
