Brief Review — CAS-ViT: Convolutional Additive Self-attention Vision Transformers for Efficient Mobile Applications
Low Complexity Self-attention for Speeding Up ViT

CAS-ViT: Convolutional Additive Self-attention Vision Transformers for Efficient Mobile Applications
CAS-ViT, by SenseTime Research, Tsinghua University, University of Washington
2024 arXiv v1 (Sik-Ho Tsang @ Medium)Image Classification
1989 … 2023 [Vision Permutator (ViP)] [ConvMixer] [CrossFormer++] [FastViT] [EfficientFormerV2] [MobileViTv2] [ConvNeXt V2] [SwiftFormer] 2024 [FasterViT]
==== My Other Paper Readings Are Also Over Here ====
- Convolutional Additive Self-attention Vision Transformers (CAS-ViT) is proposed, wherein a novel additive similarity function, namely Convolutional Additive Token Mixer (CATM), is used to achieve a balance between efficiency and performance.
Outline
- Convolutional Additive Self-attention Vision Transformers (CAS-ViT)
- Results
1. Convolutional Additive Self-attention Vision Transformers (CAS-ViT)

1.1. Prior Arts
- (a) Conventional multi-head self-attention in ViT: has well-known issue of high complexity, which is:

- (b) Separable self-attention in MobileViTv2: reduces the matrix-based feature metric to a vector, achieving lightweight and efficient inference by decreasing the computational complexity:

- (c) Swift Self-Attetion SwiftFormer: reduces the keys of self-attention to two (Q & K), thereby achieving fast inference.

1.2. Proposed Convolutional Additive Self-attention
- Let’s define the similarity function as the sum of context scores of Q:

- where Query, Key, and Value are obtained by independent linear transformations.
Φ(·) is concretized as the Sigmoid-based channel attention C(·) and spatial attention S(·). The output of CATM is:

- Since the operations in CATM are represented by convolution, the complexity is O(N).
- In the concrete implementation, S(·) is designed as a combination of depthwise convolution and Sigmoid activation. C(·) is achieved by a simplified channel attention.
1.3. Model Architecture
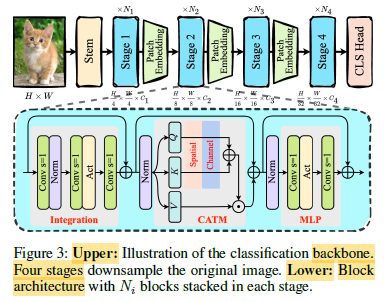
- There are 4 stage encoding layers, with Patch Embedding downsampling 2 times used between each stage.
- Each stage contains Ni stacked blocks.
- There are three parts using residual shortcuts: Integration subnet, CATM and MLP.
- Integration sub-network consists of three depthwise convolution layers activated by ReLU.
- Finally, a family of lightweight CAS-ViT is constructed by varying the number of channels Ci and blocks Ni, and the specific parameter settings.
- The model is trained from scratch for 300 epochs. The model is further fine-tuned for another 30 epochs with larger input resolution.
- 16 V100 GPUs are used.
2. Results
2.1. SOTA Comparisons

Compared to established benchmarks, the proposed approach significantly elevates the precision of classification while adeptly managing the trade-offs between model complexity and computational demand.
- Notably, the XS and S variants of the proposed model demonstrate an exceptional synergy between size.
2.2. Downstream Tasks
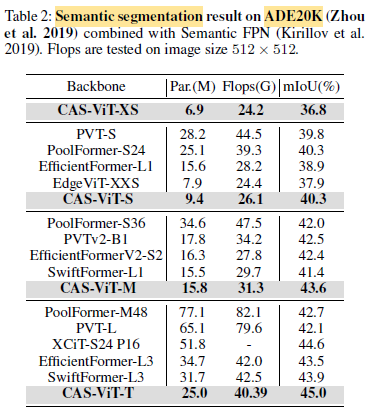
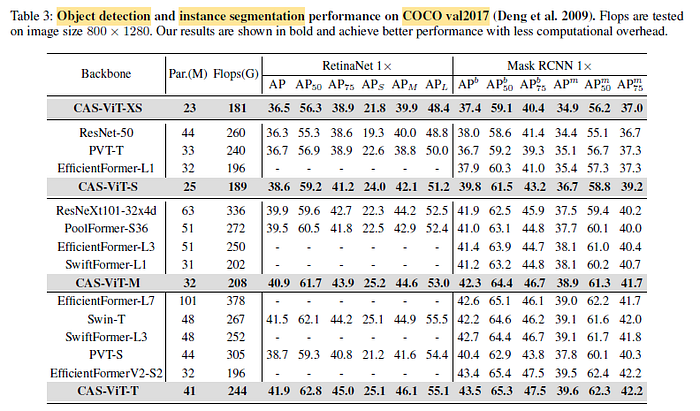
The above tables reveal the superior balance between computational efficiency and detection/segmentation accuracy achieved by the proposed models.
2.3. Visualization

The proposed method is able to accurately localize the region of interest to the critical part. Meanwhile in comparison, it can obtain a larger receptive field.
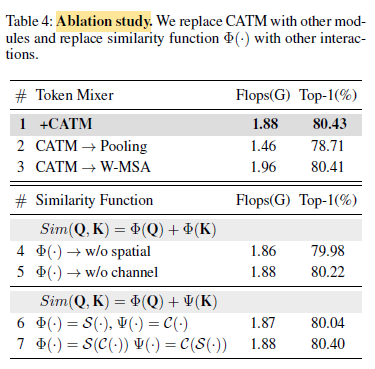
For each proposed component, when it is removed or replaced by other components, accuracy is dropped.
