Brief Review — LaMDA: Language Models for Dialog Applications
LaMDA, Improves Safety and Factual Grounding by Fine-Tuning

LaMDA: Language Models for Dialog Applications,
LaMDA, by Google
2022 arXiv v3, Over 270 Citations (Sik-Ho Tsang @ Medium)Language Model
1991 … 2022 [GPT-NeoX-20B] [GPT-3.5, InstructGPT] [GLM] [MT-NLG 530B] [Chinchilla] [PaLM] [AlexaTM] [BLOOM] [AlexaTM 20B] [OPT] [Switch Transformers] 2023 [GPT-4]

- Language Models for Dialog Applications (LaMDA), is proposed by Google, which is a family of decoder-based Transformer, having up to 137B parameters, concerning about two key challenges: safety and factual grounding.
- By fine-tuning with annotated data and enabling the model to consult external knowledge sources can lead to significant improvements towards these two key challenges, as shown above.
Outline
- LaMDA: Pretraining Dataset & Model Architecture
- Quality, Safety, Groundedness Metrics
- Role-Specific Metrics
- LaMDA Fine-Tuning for Above Metrics
- Results
- Limitations
1. LaMDA: Pretraining Dataset & Model Architecture

1.1. Pretraining Dataset
- LaMDA was pre-trained to predict the next token in a text corpus.
- The pretraining dataset was created from public dialog data and other public web documents.
- The dataset consists of 2.97B documents, 1.12B dialogs, and 13.39B dialog utterances, for a total of 1.56T words.
- Over 90% is in English.
- SentencePiece is used to tokenize the dataset into 2.81T byte pair encoding (BPE) tokens, with a vocabulary of 32K tokens.
- The largest LaMDA model has 137B non-embedding parameters, which is ~50x more parameters than Meena [17].
1.2. Model Architecture
- Decoder-only Transformer language model is used.
- The Transformer has 64 layers, dmodel=8192, dff=65536, h=128, dk=dv=128, relative attention as described in T5, and gated-GELU activation as described in Raffel et al.
- LaMDA was trained on 1024 TPU-v3 chips for a total of about 57.7 days, and 256K tokens per batch, with sharding.
- Smaller 2B-parameter and 8B-parameter models were also trained.
2. Quality, Safety, Groundedness Metrics
2.1. Quality: Sensibleness, Specificity, Interestingness (SSI) Metrics
The overall quality score is an average of sensibleness, specificity, and interestingness (SSI).
- The first score context and do not contradict anything that was said earlier.
- The second score, specificity, is used to measure whether a response is specific to a given context.
- These 2 scores are proposed to measure the quality of Meena [17].
- As the model’s performance increases, however, it is found that sensibleness and specificity are not sufficient to measure the quality of a dialog model.
- The third score, Interestingness, is proposed and measured as a 0/1 label by crowdworkers.
- Crowdworkers are asked to label a response as interesting if they judge that it is likely to “catch someone’s attention” or “arouse their curiosity”, or if it is unexpected, witty, or insightful.
2.2. Safety
- A dialog model can achieve high quality (SSI) scores but can be unsafe for users.
- This metric follows objectives derived from Google’s AI Principles (https://ai.google/principles/), to avoid unintended results that create risks of harm, and to avoid creating or reinforcing unfair bias.
2.3. Groundedness
- Groundedness is defined as the percentage of responses containing claims about the external world that can be supported by authoritative external sources.
- ‘Informativeness’ is defined as the percentage of responses that carry information about the external world that can be supported by known sources as a share of all responses.
- ‘Citation accuracy’ is defined as the percentage of model responses that cite the URLs of their sources as a share of all responses with explicit claims about the external world, excluding claims with well-known facts.
3. Role-Specific Metrics
3.1. Helpfulness
- The model’s responses are marked helpful if they contain correct information based on the user’s independent research with an information retrieval system, and the user considers them helpful.
3.2. Role Consistency
- The model’s responses are marked role consistent if they look like something an agent performing the target role would say.
4. LaMDA Fine-Tuning for Above Metrics
4.1. Quality (Sensibleness, Specificity, Interestingness)
- For each response, authors ask other crowdworkers to rate whether the response given the context is sensible, specific, and/or interesting, and to and mark each with ‘yes’, ‘no’, or ‘maybe’ labels.
- The models are evaluated based on the model’s generated responses to the Mini-Turing Benchmark (MTB) dataset [17], which consists of 1477 dialogs with up to 3 dialog turns.
- These dialogs are fed to the model to generate the next response. Similar to above, every response is labeled sensible, specific or interesting if at least 3 out of 5 crowdworkers mark it ‘yes’.
4.2. Safety
- Similar to SSI, 8K dialogs are collected with 48K turns by asking crowdworkers to interact with the model.
4.3. Groundedness
- Similar to SSI and safety, 4K dialogs are collected with 40K turns by asking crowdworkers to interact with the model.
4.4. Discriminative and Generative Fine-Tuning
- (Please feel free to read the paper directly for more details.)
- Several fine-tunings are performed, which includes using one model for both generation and discrimination enables an efficient combined generate-and-discriminate procedure.
- Thus the model can generate response given contexts:
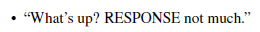
- And discriminative tasks that evaluate quality and safety of a response in context:

- First, LaMDA is fine-tuned to predict the SSI and safety ratings of the generated candidate responses.
- Then, candidate responses for which the model’s safety prediction falls below a threshold during generation are filtered out.
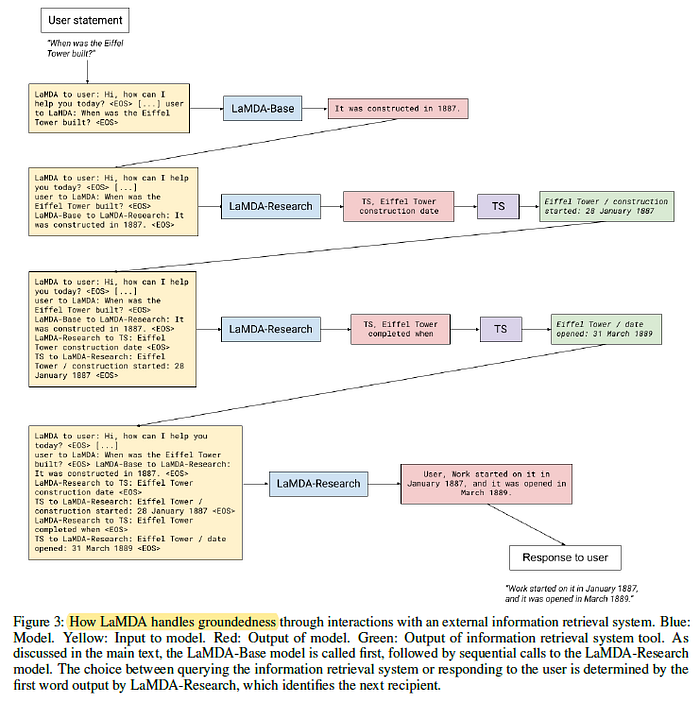
- The first task takes the multiturn dialog context to date and the response generated by the base model.
- The second task takes the snippet returned by a tool, and a dialog statement (e.g., “He is 31 years old right now” + “Rafael Nadal / Age / 35”). It then predicts the grounded version: context + base + query + snippet → “User, He is 35 years old right now”.
- Thus, LaMDA SSI and safety discriminators are also used to score and filter 2.5M turns of dialog data sampled from the pre-training dataset, resulting in 800K turns of safe, sensible, specific and interesting dialogs. LaMDA model is then fine-tuned over this dataset to generate the response in a given context.
5. Results

The figure shows that fine-tuning (in particular LaMDA) produces a significant improvement in quality, safety and groundedness across all model sizes.
Moreover, quality metrics (sensibleness, specificity, and interestingness) generally improve with model size with or without fine-tuning, but they are consistently better with fine-tuning.

- FT means Fine-Tune and PT means Pretrain.
- The above figure breaks down the contributions of FT quality-safety fine-tuning and FT groundedness fine-tuning to the final results using the largest model.
There is a notable increase in performance across all metrics between PT and FT quality-safety. Groundedness further improves from FT quality-safety to FT groundedness (LaMDA), which is meant to ground the model-generated statements about the external world on an information retrieval system.
6. Limitations
- Authors also mentioned that there are limitations:
e.g.: Collecting fine-tuning datasets brings the benefits of learning from nuanced human judgements, but it is an expensive, time consuming, and complex process.
