Brief Review — PPBERT: A Robustly Optimized BERT Pre-training Approach with Post-training
PPBERT: Pretraining+Post-Training+Fine-Tuning for BERT
A Robustly Optimized BERT Pre-training Approach with Post-training,
PPBERT, by Dongbei University of Finance and Economics, University of Southern California, Union Mobile Financial Technology, IBM Research,
2021 CCL, Over 50 Citations (Sik-Ho Tsang @ Medium)
Natural Language Processing, NLP, Language Model, LM, BERT
- Compared with original BERT architecture that is based on the standard two-stage paradigm, PPBERT does not fine-tune pre-trained model directly, but rather post-train it on the domain or task related dataset first
- This helps to better incorporate task-awareness knowledge and domain-awareness knowledge within pre-trained model, also from the training dataset reduce bias.
Outline
- PPBERT
- Results
1. PPBERT

1.1. Pretraining (1st Stage)
- The pre-training processing follows that of the BERT model.
1.2. Proposed Post-Training (2nd Stage)
- PPBERT does not fine-tune pre-trained model, but rather first post-train the model on the task or domain related training dataset directly.
- A second training stage is added, that is ‘post-training’ stage, on an intermediate task before target-task fine-tuning.
- During post-training, each task is allocated K training iterations.
- (Please feel free to read the paper directly for more details.)
1.3. Fine-Tuning (3rd Stage)
- A supervised dataset from specific task is used to further fine-tune.
2. Results
2.1. GLUE

PPBERTBASE achieves an average score of 81.53, and outperforms standard BERTBASE on all of the 8 tasks.
PPBERTLARGE outperform BERTLARGE on all of the 8 tasks and achieves an average score of 85.03.
- Similar results are observed in the dev set column, achieving an average score of 87.02 on the dev set, a 2.97 improvement over BERTLARGE.
- PPBERTLARGE matched or even outperformed human level.
2.2. SuperGLUE

PPBERT outperforms BERT on 8 tasks significantly.
- There is a huge gap between human performance (89.79) and the performance of PPBERT (74.55).
2.3. SQuAD

- ALBERT is also post-trained as PPALBERT. Also, it is further post-train ed with one additional QA dataset (SearchQA), becoming PPALBERTLARGE-QA.
Compared with BERT baseline, adding post-training stage improves the EM by 1.1 points (84.1 > 85.2). and F1 1.2 points (90.9 > 92.1).
Similarly, PPALBERTLARGE also outperforms ALBERTLARGE baseline, by 0.3 EM and 0.2 F1.
- Especially, PPALBERTLARGE-QA using further post-training relatively improves 0.1 EM and 0.1 F1 over PPALBERTLARGE, respectively.
2.3. 6 QA and NLI Tasks
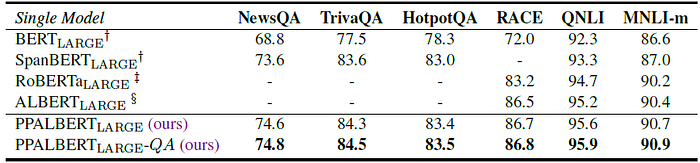
PPALBERTLARGE outperforms ALBERTLARGE baseline, by 0.3 EM and 0.2 F1. Especially, PPALBERTLARGE-QA using further post-training relatively improves 0.1 EM and 0.1 F1 over PPALBERTLARGE, respectively.
- Similar results are observed on SQuAD v2.0 development set.
Reference
[2021 CCL] [PPBERT]
A Robustly Optimized BERT Pre-training Approach with Post-training,
PPBERT
2.1. Language Model / Sequence Model
(Some are not related to NLP, but I just group them here)
1991 … 2020 [ALBERT] [GPT-3] [T5] [Pre-LN Transformer] [MobileBERT] [TinyBERT] [BART] [Longformer] [ELECTRA] [Megatron-LM] [SpanBERT] [UniLMv2] 2021 [PPBERT]
