Brief Review — ResT V2: Simpler, Faster and Stronger
ResTv2, Enhanced ResTv1 by Efficient Multi-Head Self-Attention v2 (EMSAv2)

ResT V2: Simpler, Faster and Stronger
ResTv2, by Nanjing University,
2022 NeurIPS (To Be Published) (Sik-Ho Tsang @ Medium)
Image Classification, Vision Transformer, ViT, Transformer
- ResTv2 simplifies the EMSA structure in ResTv1.
- An upsample operation is introduced to reconstruct the lost medium- and high-frequency information caused by the downsampling operation.
Outline
- Efficient Multi-Head Self-Attention v2 (EMSAv2)
- Results
1. Efficient Multi-Head Self-Attention v2 (EMSAv2)

1.1. EMSA in ResTv1
- To compress memory, x is reshaped to its 2D size and then are downsampled by a depth-wise convolution to reduce the height and width:

1.2. EMSAv2
- An upsampling operation is introduced on the values directly. There are many upsampling strategies, such as “nearest”, “bilinear”, “pixel-shuffle”, etc.
- All of them can improve the model’s performance, but “pixel-shuffle” works better.

- Surprisingly, this “downsample-upsample” combination in EMSAv2 happens to build an independent convolution branch, which can efficiently reconstruct the lost information with fewer extra parameters and computation costs.
- And the multi-head interaction module of the self-attention branch in EMSAv2 will decrease the actual inference speed of EMSAv2, although it can increase the final performance.
- Therefore, it is removed for faster speed under default settings. However, if the head dimension is small (e.g., dk=64 or smaller), the multi-head interaction module will make a difference.
1.3. ResTv2 Model Variants
- Different ResTv2 (T/S/B/L) variants are built based on EMSAv2.
- ResTv2-T/B/L, to be of similar complexities to Swin-T/S/B:


2. Results
2.1. ImageNet

ResTv2 competes favorably with them in terms of a speed-accuracy trade-off. Specifically, ResTv2 outperforms ResTv1 of similar complexities across the board, sometimes with a substantial margin.
2.2. Ablation Study
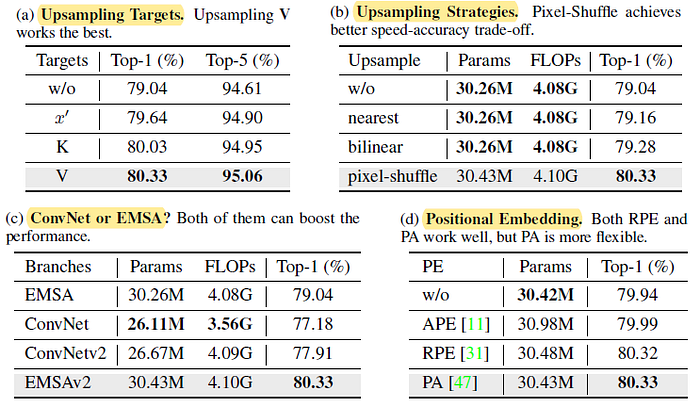
- (a) Upsampling Targets: Upsampling V works best.
- (b) Upsampling Strategies: Pixel-shuffle operation obtains much stronger feature extraction capabilities with a few parameters and FLOPs increase.
- (c) ConvNet or EMSA?: The “downsampling-upsampling” pipeline in EMSAv2 can constitute a complete ConvNet block for extracting features.
- (d) Positional Embedding: PE can still improve the performance, but not that obvious as ResTv1.
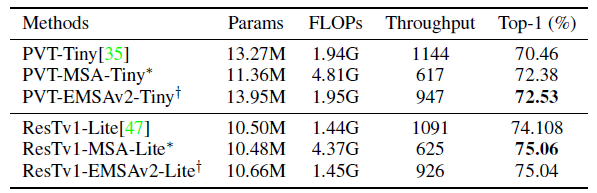
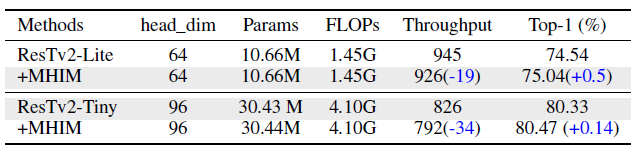
Removing MHIM obtains higher throughput.
2.3. Downstream
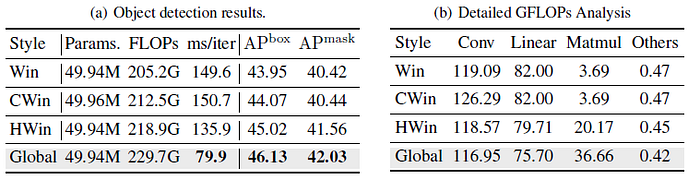
- Win: The recent popular one is window-style, which constrained part or all MSA modules of ViTs into a fixed window to save computation overhead. However, performing all MSA into a limited-sized window will lose the MSA’s long-range dependency ability.
- CWin: To alleviate this issue, we add a 7×7 depth-wise convolution layer after the last block in each stage to enable information to communicate across windows.
- HWin: In addition, MViTv2 [20] provides a hybrid approach to integrate window information, i.e., computes MSA within a window in all but the last blocks in each stage that feed into FPN.
- Window sizes in Win, CWin, and HWin are set as [64, 32, 16, 8] for the four stages.
(a) Global fine-tuning strategy as default in downstream tasks to get better accuracy and inference speed.
(b) Window-based fine-tune methods can effectively reduce the “Matmul” (short of matrix multiply) FLOPs with the cost of introducing extra “Linear” FLOPs.
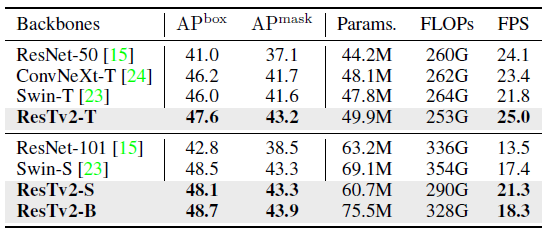
ResTv2 outperforms Swin Transformer and ConvNeXt with higher mAP and inference FPS (frames per second), particularly for tiny models.
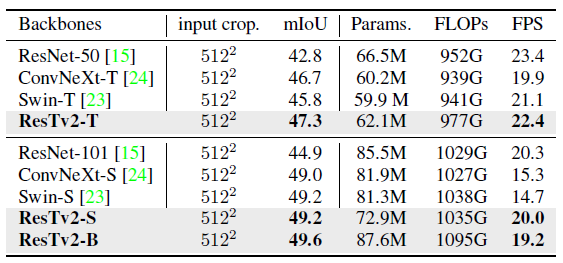
ResTv2 models can achieve competitive performance across different model capacities, further validating the effectiveness of our architecture design.
Reference
[2022 NeurIPS] [ResTv2]
ResT V2: Simpler, Faster and Stronger
1.1. Image Classification
1989 … 2022 [ConvNeXt] [PVTv2] [ViT-G] [AS-MLP] [ResTv2]
