Brief Review — TOOD: Task-aligned One-stage Object Detection

TOOD: Task-aligned One-stage Object Detection
TOOD, by Intellifusion Inc., Meituan Inc., ByteDance Inc., Malong LLC, and Alibaba Group
2021 ICCV, Over 460 Citations (Sik-Ho Tsang @ Medium)Object Detection
2014 … 2021 [Scaled-YOLOv4] [PVT, PVTv1] [Deformable DETR] [HRNetV2, HRNetV2p] [MDETR] [TPH-YOLOv5] 2022 [Pix2Seq] [MViTv2] [SF-YOLOv5] [GLIP] [TPH-YOLOv5++] 2023 [YOLOv7]
==== My Other Paper Readings Are Also Over Here ====
- Task-aligned One-stage Object Detection (TOOD) designs a novel Task-aligned Head (T-Head) which offers a better balance between learning task-interactive and task-specific features, as well as a greater flexibility to learn the alignment via a task-aligned predictor.
- Task Alignment Learning (TAL) is proposed to explicitly pull closer (or even unify) the optimal anchors for the two tasks during training via a designed sample assignment scheme and a task-aligned loss.
Outline
- Task-aligned One-stage Object Detection (TOOD)
- Results
1. Task-aligned One-stage Object Detection (TOOD)
1.1. Overall Framework

- T-head and TAL work collaboratively to improve the alignment of classification and localization tasks.
- Specifically, T-head first makes predictions for the classification and localization on the FPN features.
- Then TAL computes task alignment signals based on a new task alignment metric which measures the degree of alignment between the two predictions.
- Lastly, T-head automatically adjusts its classification probabilities and localization predictions using learning signals computed from TAL during back propagation.
1.2. T-Head
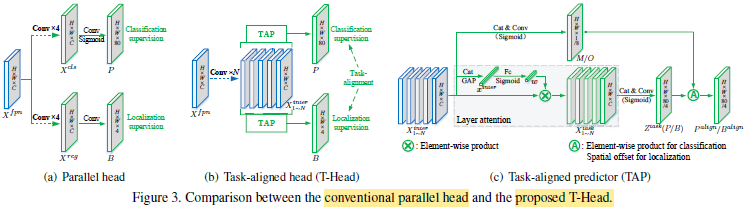
- TOOD has an overall pipeline of ‘backbone-FPN-head’.
- Existing one-stage detectors have limitations of task misalignment between classification and localization, due to the divergence of two tasks as parallel heads are used.
- T-head uses a simple feature extractor with two Task-Aligned Predictors (TAP) where there is task aligment in TAP.
- TAP converts feature maps into dense classification scores P, or object bounding boxes B.
- A probability map M which is computed from the interactive features, is used to adjust the classification prediction P to P^align:

- A spatial offset maps O is also further learned. The alignment maps M and O are learned automatically from the stack of interactive features:
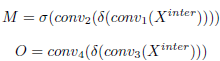
1.3. Task Alignment Learning (TAL)
- A metric is designed to compute anchor-level alignment for each instance:
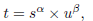
- where s and u denote a classification score and an IoU value, respectively.
- Notably, t plays a critical role in the joint optimization of the two tasks towards the goal of task-alignment.
- For training sample assignment, for each instance, m anchors are assigned having the largest t values as positive samples, while the remaining anchors are used as negative ones. Again, the training is performed by computing new loss functions.
- Binary Cross Entropy (BCE) is computed on the positive anchors for the classification task:
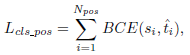
- The focal loss computed on the positive anchors can be obtained by reformulating the above equation, and the final loss function for the classification task:

- The loss of bounding box regression computed for each anchor based on ^t is re-weighted, and a GIoU loss (LGIoU) can be reformulated as follows:
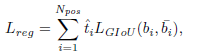
- The total training loss for TAL is the sum of Lcls and Lreg.



