[Paper] MixConv: Mixed Depthwise Convolutional Kernels (Image Classification)
MixConv, Composes MixNets, Similar Performance With MobileNetV3; Outperforms ProxylessNAS, FBNet, DARTS, MnasNet, NASNet, MobileNetV2, ShuffleNet V2, ShuffleNet V1 & MobileNetV1

In this story, MixConv: Mixed Depthwise Convolutional Kernels (MixConv), by Google Brain, is presented. In this paper:
- A new mixed depthwise convolution (MixConv), which naturally mixes up multiple kernel sizes in a single convolution.
- By integrating MixConv into AutoML search space, a new family of models is developed, named as MixNets.
This is a paper in 2019 BMCV with over 60 citations. (Sik-Ho Tsang @ Medium)
Outline
- MixConv
- MixConv Performance on MobileNets
- Ablation Study
- MixNet
- MixNet Performance on ImageNet
- Transfer Learning Performance
1. MixConv

- Unlike vanilla depthwise convolution, MixConv partitions channels into groups and applies different kernel sizes to each group.

- More concretely, the input tensor is partitioned into g groups of virtual tensors.
- The convolutional kernel is also partitioned into g groups of virtual kernels.
- The final output tensor is a concatenation of all virtual output tensors.
1.1. Group Size
- In the extreme case of g = 1, a MixConv becomes equivalent to a vanilla depthwise convolution.
- In our experiments, we find g = 4 is generally a safe choice for MobileNets.
- But with the help of neural architecture search, we find it can further benefit the model efficiency and accuracy with a variety of group sizes from 1 to 5.
1.2. Kernel Size Per Group
- Each group is restricted to have different kernel sizes.
- And kernel size is always restricted to be started from 3×3, and monotonically increases by 2 per group.
- For example, a 4-group MixConv always uses kernel sizes {3×3, 5×5, 7×7, 9×9}.
1.3. Channel Size Per Group
- Two partition methods.
- For example, given a 4-group MixConv with total filter size 32, The equal partition will divide the 32 channels into (8, 8, 8, 8), while the exponential partition will divide the channels into (16, 8, 4, 4).
1.4. Dilated Convolution
- Dilated convolution can increase receptive field without extra parameters and computations. However, dilated convolutions usually have inferior accuracy than large kernel sizes.
2. MixConv Performance on MobileNets

- MixConv always starts with 3×3 kernel size and then monotonically increases by 2 per group, so the rightmost point for MixConv in the figure has six groups of filters with kernel size {3×3, 5×5, 7×7, 9×9, 11×11, 13×13}.
- In this figure, we can see that MixConv generally uses much less parameters and FLOPS, but its accuracy is similar or better than vanilla depthwise convolution, suggesting mixing different kernels can improve both efficiency and accuracy.
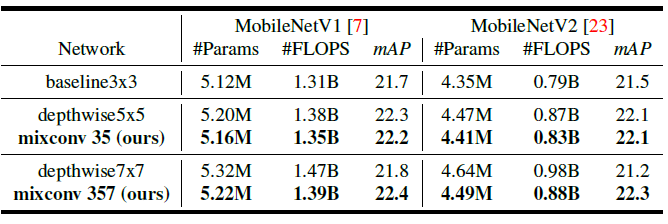
- MixConv357 (with 3 groups of kernels {3×3, 5×5, 7×7}) achieves 0.6% higher mAP on MobileNetV1 and 1.1% higher mAP on MobileNetV2 using fewer parameters and FLOPS.
3. Ablation Study
3.1. MixConv for Single Layer

- Replace one of the 15 layers with either (1) vanilla DepthwiseConv9×9 with kernel size 9×9; or (2) MixConv3579 with 4 groups of kernels: {3×3, 5×5, 7×7, 9×9}.
- For most of layers, the accuracy doesn’t change much, but for certain layers with stride 2, a larger kernel can significantly improve the accuracy.
- Although MixConv3579 uses only half parameters and FLOPS than the vanilla DepthwiseConv9×9, MixConv achieves similar or slightly better performance for most of the layers.
3.2. Channel Partition Methods
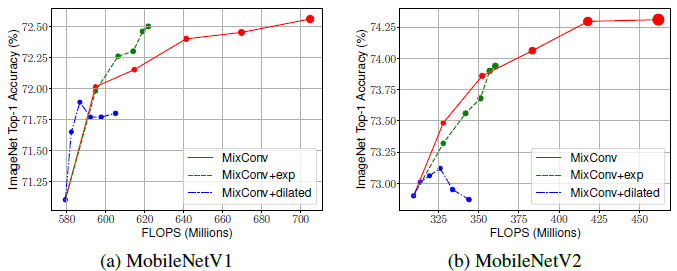
- Exponential channel partition only performs slightly better than equal partition on MobileNetV1, but there is no clear winner if considering both MobileNetV1 and MobileNetV2.
3.3. Dilated Convolution
- As shown above, dilated convolution has reasonable performance for small kernels, but the accuracy drops quickly for large kernels.
- The hypothesis is that when dilation rate is big for large kernels, a dilated convolution will skip a lot of local information, which would hurt the accuracy.
4. MixNet
- The neural architecture search (NAS) settings are similar to recent MnasNet and FBNet, which use MobileNetV2 as the baseline network structure.
- The search space also includes swish activation, squeeze-and-excitation module, and grouped convolutions with group size 1 or 2 for 1×1 convolutions.
- MixConv is also as the search options. Five MixConv candidates with group size g = 1, …, 5, from 3×3, …, to 3×3, 5×5, 7×7, 9×9, 11×11.
- Exponential channel partition or dilated convolutions is not included.
- The NAS directly search on ImageNet train set, and then pick a few top-performing models from search to verify their accuracy on ImageNet validation set and transfer learning datasets.

- It is observed that the bigger MixNet-M tends to use more large kernels and more layers to pursuing higher accuracy.
- MixNets are capable of utilizing very large kernels such as 9×9 and 11×11 to capture high-resolution patterns from input images, without hurting model accuracy and efficiency.
5. MixNet Performance on ImageNet


- MixNets improve top-1 accuracy by 4.2% than MobileNetV2 and 3.5% than ShuffleNet V2, under the same FLOPS constraint.
- Compared to the latest automated models, MixNets achieve better accuracy than MnasNet (+1.3%), FBNets (+2.0%), ProxylessNAS (+2.2%) under similar FLOPS constraint.
- MixNets also achieve similar performance as the latest MobileNetV3.
- MixNet-L achieves a new state-of-the-art 78.9% top-1 accuracy under typical mobile FLOPS (<600M) constraint.
6. Transfer Learning Performance


- For each model, it is first trained from scratch on ImageNet and than finetune all the weights on the target dataset.
- MixNets significantly outperform previous models on all these datasets.
Reference
[2019 BMCV] [MixConv]
MixConv: Mixed Depthwise Convolutional Kernels
Image Classification
1989–1998: [LeNet]
2012–2014: [AlexNet & CaffeNet] [Maxout] [Dropout] [NIN] [ZFNet] [SPPNet]
2015: [VGGNet] [Highway] [PReLU-Net] [STN] [DeepImage] [GoogLeNet / Inception-v1] [BN-Inception / Inception-v2]
2016: [SqueezeNet] [Inception-v3] [ResNet] [Pre-Activation ResNet] [RiR] [Stochastic Depth] [WRN] [Trimps-Soushen]
2017: [Inception-v4] [Xception] [MobileNetV1] [Shake-Shake] [Cutout] [FractalNet] [PolyNet] [ResNeXt] [DenseNet] [PyramidNet] [DRN] [DPN] [Residual Attention Network] [IGCNet / IGCV1] [Deep Roots]
2018: [RoR] [DMRNet / DFN-MR] [MSDNet] [ShuffleNet V1] [SENet] [NASNet] [MobileNetV2] [CondenseNet] [IGCV2] [IGCV3] [FishNet] [SqueezeNext] [ENAS] [PNASNet] [ShuffleNet V2] [BAM] [CBAM] [MorphNet] [NetAdapt] [mixup] [DropBlock]
2019: [ResNet-38] [AmoebaNet] [ESPNetv2] [MnasNet] [Single-Path NAS] [DARTS] [ProxylessNAS] [MobileNetV3] [FBNet] [ShakeDrop] [CutMix] [MixConv]
2020: [Random Erasing (RE)]
