Review — PoolFormer: MetaFormer is Actually What You Need for Vision
PoolFormer is Designed Based on General Architecture MetaFormer

MetaFormer is Actually What You Need for Vision,
MetaFormer, by AI Lab, and National University of Singapore
2022 CVPR, Over 170 Citations (Sik-Ho Tsang @ Medium)Image Classification
1989 … 2022 [ConvNeXt] [PVTv2] [ViT-G] [AS-MLP] [ResTv2] [CSWin Transformer] [Pale Transformer] [Sparse MLP] [MViTv2] [S²-MLP] [CycleMLP] [MobileOne] [GC ViT] [VAN] [ACMix] [CVNets] [MobileViT] [RepMLP] [RepLKNet] [ParNet] 2023 [Vision Permutator (ViP)]
==== My Other Paper Readings Are Also Over Here ====
- General architecture MetaFormer is designed.
- Pooling is used to replace in the attention module.
Outline
- MetaFormer
- PoolFormer
1. MetaFormer

1.1. Prior Methods
- (a) Transformer: such as DeiT, consists of two components. One is the attention module for mixing information among tokens and it is termed as token mixer. The other component contains the remaining modules, such as channel MLPs and residual connections.
- (b) MLP-like model: such as ResMLP, use MLP to replace the attention module.
1.2. MetaFormer
- (Leftmost) Metaformer: When we further abstract the overall Transformer into a general architecture where the token mixer is not specified, it is called MetaFormer.
- The input I is first processed by input embedding, such as patch embedding for ViTs:

- where X is the embedding tokens with sequence length N and embedding dimension C. The embedding tokens are fed to repeated MetaFormer blocks, each of which includes two residual sub-blocks.
- The first sub-block mainly contains a token mixer to communicate information among tokens:

- where Norm(·) denotes the normalization such as Layer Norm and Batch Norm.
- The main function of the token mixer is to propagate token information although some token mixers can also mix channels, like attention.
- The second sub-block primarily consists of a two-layered MLP with non-linear activation:

- where W1 has size of C×rC and W2 has size of rC×C with r is the MLP expansion ratio. σ(·) is a non-linear activation function, such as GELU or ReLU.
- If the token mixer is specified as attention or spatial MLP, MetaFormer then becomes a Transformer or MLP-like model respectively.
2. PoolFormer
2.1. Token Mixer
- Simple operator, pooling, is proposed as the token mixer. This operator has no learnable parameters and it just makes each token averagely aggregate its nearby token features:
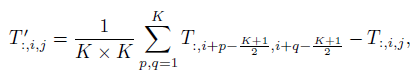
- where T is the input in channel-first data format, and K is the pooling size.

- The pseudo codes are simple as above.
- Layer Norm is modified to compute the mean and variance along token and channel dimensions compared to only channel dimension in vanilla Layer Norm.
2.2. Overall Architecture
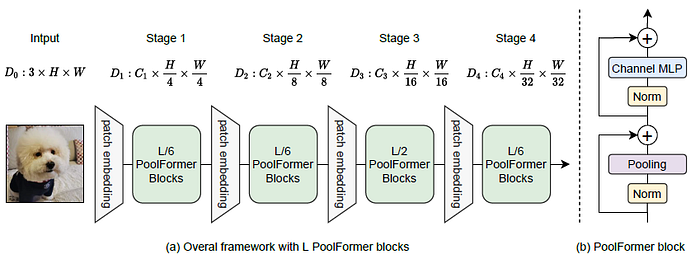
- PoolFormer adopts hierarchical architecture with 4 stages.
- For a model with L PoolFormer blocks, stage [1, 2, 3, 4] have [L/6, L/6, L/2, L/6] blocks, respectively. The feature dimension Di of stage i is shown in the figure.
2.3. PoolFormer Variants
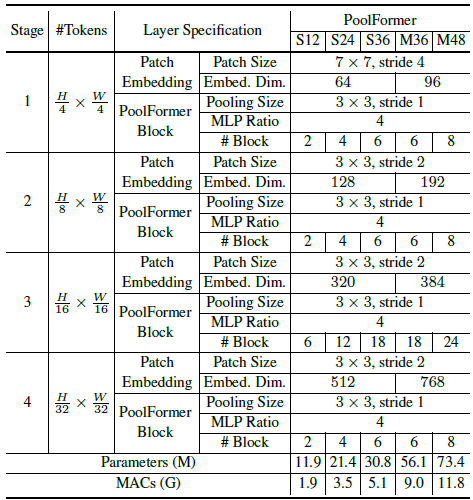
- There are two groups of embedding size: 1) small-sized models with embedding dimensions of 64, 128, 320, and 512 responding to the four stages; 2) medium-sized models with embedding dimensions 96, 192, 384, and 768.
- Finally, 5 different model sizes are obtained as above.
3. Results
3.1. Image Classification

PoolFormers can still achieve highly competitive performance compared with CNNs and other MetaFormer-like models.
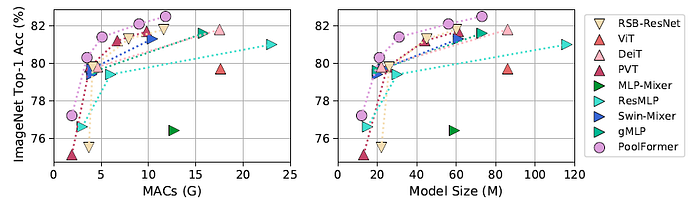
PoolFormer surpasses other models with fewer MACs and parameters.
3.2. Object Detection
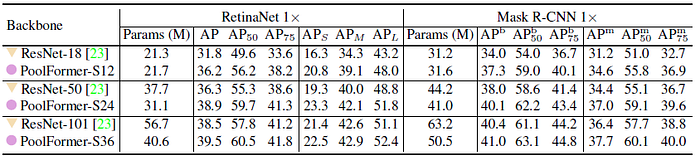
Equipped with RetinaNet and Mask R-CNN for object detection, PoolFormer-based models consistently outperform their comparable ResNet counterparts.
3.3. Semantic Segmentation
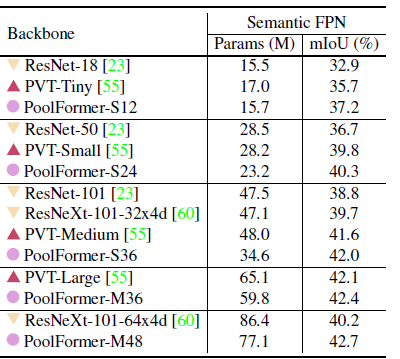
Using Panoptic FPN as backbone, PoolFormer-based models consistently outperform the models with backbones of CNN-based ResNet and ResNeXt as well as Transformer-based PVT.
3.4. Ablation Study
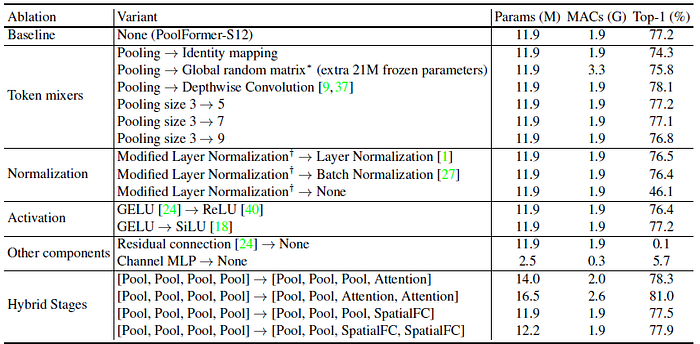
- Baseline: S12 obtains 77.2%.
- Token Mixer: Using Depthwise convolution improves to 78.1%. Or using other pooling sizes obtain the same or lower performance.
- Normalization: The modified Layer Norm has better performance.
- Activation: GELU or SiLU has the same performance.
- Other components: Removing residual connection or channel MLP obtains very low accuracy.
- Hybrid Stages: Different stages use pooling and attention modules. [Pool, Pool, Attention, Attention] obtains higher accuracy of 81.0%.
MetaFormer is actually what you need for vision!
