Review — NFNet: Normalizer-Free Networks
Networks Without Normalization Layers

High-Performance Large-Scale Image Recognition Without Normalization
NFNet, by DeepMind
2021 ICML, Over 100 Citations (Sik-Ho Tsang @ Medium)
Image Classification, Object Detection, Residual Network, ResNet
Outline
- Adaptive Gradient Clipping (AGC)
- Normalizer-Free Architectures
- Experimental Results
1. Adaptive Gradient Clipping (AGC)
1.1. Standard Gradient Clipping
- Gradient clipping is typically performed by constraining the norm of the gradient.
- Specifically, for gradient vector G=δL=δθ, where L denotes the loss and θ denotes a vector with all model parameters, the standard clipping algorithm clips the gradient before updating θ as:

- However, it is found that while this clipping algorithm enabled us to train at higher batch sizes than before, training stability was extremely sensitive to the choice of the clipping threshold λ.
- Extensive hyperparameter tuning is needed to tune λ.
1.2. Proposed Adaptive Gradient Clipping (AGC)
The AGC algorithm is motivated by the observation that the ratio of the norm of the gradients Gl to the norm of the weights Wl of layer l:

provides a simple measure of how much a single gradient descent step will change the original weights Wl.
- where ||.||F is the Frobenius norm, i.e.:

- If the model is trained using gradient descent without momentum, the relationship of weight and gradient is:

- Intuitively, training becomes unstable when the ratio of the left hand side, ||ΔWl||/||Wl||, is large which motivates a clipping strategy based on the ratio from the right hand side, ||ΔGl||F/||Wl||F.
In the proposed AGC algorithm, each unit i of the gradient of the l-th layer Gli (defined as the ith row of matrix Gl) is clipped as:

- The clipping threshold λ is a scalar hyperparameter.
Using AGC, NF-ResNets can be trained stably with larger batch sizes (up to 4096), as well as with very strong data augmentations like RandAugment.

- Pre-Activation NF-ResNet-50 and NF-ResNet-200 on ImageNet is trained, consider a range of λ values [0.01, 0.02, 0.04, 0.08, 0.16].
- (a): AGC helps scale NF-ResNets to large batch sizes while maintaining performance comparable or better than batch-normalized networks on both ResNet50 and ResNet200.
- (b): Smaller (stronger) clipping thresholds are necessary for stability at higher batch sizes.
2. Normalizer-Free Architectures
- After proposing AGC, authors seek to design a normalizer-free architectures.
- A model of SE-ResNeXt-D model with GELU activations is used. (SE means SE block in SENet. D means the Bag of Tricks or ResNet-D proposed in Zhang CVPR’19.)
2.1. Group Width
- First, the group width in 3×3 convs is set o 128. On TPUv3 for example, an SE-ResNeXt-50 with a group width of 8 trains at the same speed as an SE-ResNeXt-50 with a group width of 128.
2.2. Backbone
- Then, there are two changes in the backbone.
- First, a simple scaling rule is used for constructing deeper variants. The smallest model variant, named, F0, is designed on the simple pattern [1, 2, 6, 3] for 4 stages where the number is the number of bottleneck blocks within each stage.
- Deeper variants are constructed by multiplying the depth of each stage by a scalar N, so that, for example, variant F1 has a depth pattern [2, 4, 12, 6], and variant F4 has a depth pattern [5, 10, 30, 15].
- Second, the width pattern [256, 512, 1536, 1536] is found to be better than the default [256, 512, 1024, 2048]: This width pattern is designed to increase capacity in the third stage while slightly reducing capacity in the fourth stage. Width scaling is not used as it is ineffective.
2.3. Bottleneck Residual Block
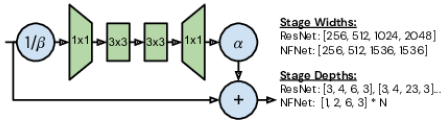
- An additional 3×3 grouped conv is added.
2.4. Training
- According to FixRes, NFNet evaluate images at inference at a slightly higher resolution than train at, chosen for each variant as approximately 33% larger than the train resolution. No fine-tune at this higher resolution.
- Drop rate of Dropout is scaled.
2.5. Summary

- So, F0 to F6 for NFNet are designed as above.
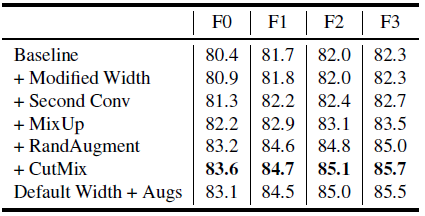
- From the first three rows, we can see that the two changes we make to the model each result in slight improvements to performance with only minor changes in training latency.
- Data augmentations using mixup, RandAugment, and CutMix. substantially improve performance.
- Finally, the last row shows that, with the default ResNet, as ablation study, the proposed slightly modified pattern in the third and fourth stages does yield improvements under direct comparison.
3. Experimental Results
3.1. ImageNet

NFNet-F5 model attains a top-1 validation accuracy of 86.0%, improving over the previous state of the art, EfficientNet-B8 with MaxUp by a small margin.
NFNet-F1 model matches the 84.7% of EfficientNet-B7 with RA, while being 8.7× times faster to train.
- The proposed models also benefit from the recently proposed Sharpness-Aware Minimization (SAM, (Foret et al., 2021)).
3.2. Transfer Learning
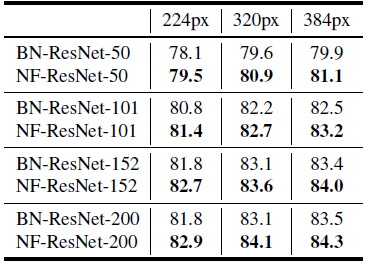
- It is hypothesized that unnormalized networks do not share the implicit regularization effect of batch normalization, which may make Normalizer- Free networks naturally better suited to transfer learning after large-scale pre-training.
- Pre-training is done on a large dataset of 300 million labeled images.
- NFNet-F4+ (NF-ResNet-200): A slightly wider variant of NFNet-F4.
NFNet-F4+ (NF-ResNet-200) attains an ImageNet top-1 accuracy of 89.2%. This is the second highest validation accuracy achieved to date with extra training data, second only to a strong recent semi-supervised learning baseline (Pham et al., 2020), and the highest accuracy achieved using transfer learning, on ImageNet.
3.3. Object Detection
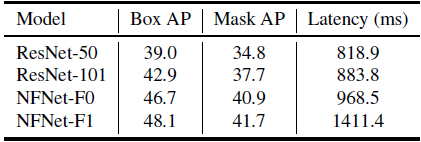
- Mask R-CNN and FPN are used on COCO.
NFNets, without any modification, can be successfully substituted into this downstream task in place of batch-normalized ResNet backbones.
Reference
[2021 ICML] [NFNet]
High-Performance Large-Scale Image Recognition Without Normalization
Image Classification
1989–2019 … 2020: [Random Erasing (RE)] [SAOL] [AdderNet] [FixEfficientNet] [BiT] [RandAugment] [ImageNet-ReaL] [ciFAIR] [ResNeSt] [Batch Augment, BA]
2021: [Learned Resizer] [Vision Transformer, ViT] [ResNet Strikes Back] [DeiT] [EfficientNetV2] [MLP-Mixer] [T2T-ViT] [Swin Transformer] [CaiT] [ResMLP] [ResNet-RS] [NFNet]
