Review — OSCAR: Object-Semantics Aligned Pre-training for Vision-Language Tasks
OSCAR, Pretrained on 6.5M Text-Image Pairs

OSCAR: Object-Semantics Aligned Pre-training for Vision-Language Tasks,
OSCAR, by Microsoft Corporation, and University of Washington,
2020 ECCV, Over 600 Citations (Sik-Ho Tsang @ Medium)
Vision Language Model, VLM, BERT
- A new learning method Object-Semantics Aligned Pre-training (OSCAR) is proposed, which uses object tags detected in images as anchor points to significantly ease the learning of alignments.
- An OSCAR model is pretrained on the public corpus of 6.5 million text-image pairs.
Outline
- Object-Semantics Aligned Pre-training (OSCAR)
- Results
1. Object-Semantics Aligned Pre-training (OSCAR)

1.1. Motivations
- (a): The training data for many V+L tasks consists of image-text pairs. A dataset of size N is denoted by D={(Ii, wi)}, with image I and text sequence w.
- Existing VLP methods take visual region features v={v1, …, vK} of an image and word embeddings w={w1, …, wT}, suffers from 2 issues:
- Ambiguity: The visual region features are usually extracted from over-sampled regions via Faster R-CNN object detectors.
- Lack of Grounding: VLP is naturally a weakly-supervised learning problem because there is no explicitly labeled alignments between regions or objects in an image and words or phrases in text.
(b): However, we can see that salient objects such as dog and couch are presented in both image and its paired text, and can be used as anchor points for learning semantic alignments between image regions and textual units.
- (c): The process can also be interpreted as learning to ground the image objects, which might be ambiguously represented in the vision space such as dog and couch in (a), in distinctive entities represented in the language space, as illustrated in (c).
1.2. OSCAR Pretraining

- Existing VLP methods represent each input pair as (w, v). OSCAR introduces q as anchor points to ease the learning of image-text alignment.
- The image-text pair as a triple [word tokens , object tags , region features], where the object tags (e.g.: “\dog” or \couch”) are proposed to align the cross-domain semantics. When removed, Oscar reduces to previous VLP methods.
- The input triple can be understood from two perspectives: a modality view and a dictionary view.

- where x is the modality view to distinguish the representations between a text and an image; while x’ is the dictionary view to distinguish the two different semantic spaces.
1.3. Dictionary View: Masked Token Loss (MTL)
- The discrete token sequence is defined as h=[w, q].
- At each iteration, each input token in h is randomly masked with probability 15%, and replaced with a special token [MASK].
- The goal of training is to predict these masked tokens based on their surrounding tokens h\i and all image features v by minimizing the negative log-likelihood:
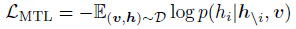
- This is similar to masked language model used by BERT, but with additional image information attended.
1.4. Modality View: Contrastive Loss
- For each input triple, h’=[q, v] is used to represent the image modality, and consider w as the language modality.
- A set of “polluted” image representations is sampled by replacing q with probability 50% with a different tag sequence randomly sampled from the dataset D.
- A fully-connected (FC) layer f() is on the top of the fused representation, to predict whether the pair contains the original image representation (y=1) or any polluted ones (y=0).
- The contrastive loss is defined as:
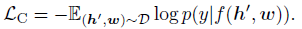
- The full pre-training objective of OSCAR is:
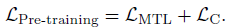
- where each loss provides a representative learning signal from its own perspective.
1.5. Datasets
- The pre-training corpus is based on the existing V+L datasets, including COCO, Conceptual Captions (CC), SBU captions, Ficker30k, GQA, etc.. In total, the unique image set is 4.1 million, and the corpus consists of 6.5 million text-tag-image triples.
- Based on the downstream tasks, different input and output formats are defined and trained.
- (Please feel free to read the paper directly if interested.)
2. Results

- The proposed Oscar is highly parameter-efficient, partially because the use of object tags as anchor points significantly eases the learning of semantic alignments between images and texts.
The proposed base model outperforms previous large models on most tasks, often by a significantly large margin.

Intra-class: With the aid of object tags, the distance of the same object between two modalities is substantially reduced.
Inter-class. Object classes of related semantics are getting closer (but still distinguishable) after adding object tags.

OSCAR generates more detailed descriptions of images than the baseline, due to the use of the accurate and diverse object tags detected by Faster R-CNN.

The learning curves for fine-tuning with object tags converges significantly faster and better than the VLP method without tags on all tasks.

Visual Genome (VG) tags performs slightly better than Open Images (OI).
VinVL uses OSCAR later in 2021.
Reference
[2020 ECCV] [OSCAR]
OSCAR: Object-Semantics Aligned Pre-training for Vision-Language Tasks
5.1. Visual/Vision/Video Language Model (VLM)
2018 [Conceptual Captions] 2019 [VideoBERT] [VisualBERT] [LXMERT] [ViLBERT] 2020 [ConVIRT] [VL-BERT] [OSCAR]
