Review — VL-BERT: Pre-training of Generic Visual-Linguistic Representations
VL-BERT, A Generic Representation for Visual-Linguistic Tasks
VL-BERT: Pre-training of Generic Visual-Linguistic Representations
VL-BERT, by University of Science and Technology of China, and Microsoft Research Asia
2020 ICLR, Over 800 Citations (Sik-Ho Tsang @ Medium)
Vision Language Model (VLM), BERT, Transformer
- VL-BERT adopts the simple yet powerful Transformer model as the backbone, and extends it to take both visual and linguistic embedded features as input.
- Each element of the input is either of a word from the input sentence, or a region-of-interest (RoI) from the input image.
- VL-BERT is pretrained on the massive-scale Conceptual Captions dataset, together with text-only corpus.
Outline
- Visual-Linguistic BERT (VL-BERT)
- Pretraining VL-BERT
- Results
1. Visual-Linguistic BERT (VL-BERT)

- The input formats vary for different visual-linguistic tasks (e.g., <Caption, Image> for image captioning, and <Question, Answer, Image> for VQA and VCR.
- Three types of input elements are involved, namely, visual, linguistic, and special elements for disambiguating different input formats.
- The input sequence always starts with [CLS], then goes on with linguistic elements, then follows up with visual elements, and ends with [END]. [SEP] is used to separate sentences.
- For each input element, its embedding feature is the summation of four types of embedding, namely, token embedding, visual feature embedding, segment embedding, and sequence position embedding.
1.1. Token Embedding
- The linguistic words are embedded with WordPiece embeddings.
- For the visual elements, a special [IMG] token is assigned.
1.2. Visual Feature Embedding
- Visual appearance feature and visual geometry embedding are combined them to form the visual feature embedding.
1.2.1. Visual Appearance Feature
- The visual appearance feature is extracted by applying a Fast R-CNN where the 2048d-feature vector prior to the output layer of each RoI.
- For the non-visual elements, the corresponding visual appearance features are of features extracted on the whole input image, by Faster R-CNN.
1.2.2. Visual Geometry Embedding
- The visual geometry embedding is designed to inform VL-BERT the geometry location of each input visual element in image.
- Each RoI is characterized by a 4-d vector, as (xLT/W, yLT/H, xRB/W, hRB/H), where (xLT, yLT) and (xRB, yRB) denote the coordinate of the top-left and bottom-right corner respectively.
- This 4-d vector is embedded into a high-dimensional representation (of 2048-d in paper) by computing sine and cosine functions of different wavelengths, as similar as in Transformer.
1.3. Segment Embedding
- Three types of segment, A, B, C, are defined to separate input elements from different sources, namely, A and B for the words from the first and second input sentence respectively, and C for the RoIs from the input image.
- For <Caption, Image>, only A and C are used. A denotes Caption, and C denotes Image.
1.4. Sequence Position Embedding
- A learnable sequence position embedding is added to every input element indicating its order in the input sequence, same as BERT.
2. Pretraining Strategy
2.1. Visual-Linguistic Corpus & Text-Only Corpus
- The Conceptual Captions dataset is used as the visual-linguistic corpus. Yet, the captions are mainly simple clauses, which are too short and simple for many downstream tasks.
- VL-BERT is also pretrained on text-only corpus with long and complex sentences. BooksCorpus and the English Wikipedia datasets, are utilized, same in pre-training BERT.
- In each mini-batch, ratio of 1:1 for visual-linguistic corpus and text-only corpus is used.
2.2. Task #1: Masked Language Modeling (MLM) with Visual Clues
- Similar to BERT, each word in the input sentence(s) is randomly masked at a probability of 15%, replaced with a special token of [MASK].
- In the above figure, “kitten drinking from [MASK]”, it could be any containers, such as “bowl”, “spoon” and “bottle”. But with visual clues, the network should predict the masked word as “bottle”.
- During pre-training, the final output feature corresponding to the masked word is fed into a classifier over the whole vocabulary, driven by Softmax cross-entropy loss.
2.3. Task #2: Masked RoI Classification with Linguistic Clues
- Each RoI in image is randomly masked out (with 15% probability), and the pre-training task is to predict the category label of the masked RoI from the other clues.
- To avoid any visual clue leakage from the visual feature embedding of other elements, the pixels laid in the masked RoI are set as zeros before applying Fast R-CNN.
- In the above figure, the RoI corresponding to cat in image is masked out, and the corresponding category cannot be predicted from any visual clues. But with the input caption of “kitten drinking from bottle”, the model can infer the category such as “a cat” by exploiting the linguistic clues.
- During pre-training, the final output feature corresponding to the masked RoI is fed into a classifier with Softmax cross-entropy loss for object category classification.
2.4. Text-Only Corpus Pretraining
- The input format to VL-BERT degenerates to be <Text, ∅>, where no visual information is involved.
- The “visual feature embedding” term in the above figure is a learnable embedding shared for all words.
- The training loss is from the standard task of Masked Language Modeling (MLM) as in BERT.
3. Results
3.1. Visual Commonsense Reasoning (VCR)

- The model should pick the right answer to the question and provide the rationale explanation. For each question, there are 4 candidate answers and 4 candidate rationales.
- The above figure illustrates the input format, which is <Question, Answer, Image>.
- During fine-tuning, two losses are adopted, the classification over the correctness of the answers and the RoI classification with linguistic clues.

- Pre-training VL-BERT improves the performance by 1.0% in the final Q→ AR task.
- Despite the same input, output and experimental protocol as R2C, VL-BERT outperforms R2C by large margins, indicating the power of the proposed simple cross-modal architecture.
Compared with other concurrent works, i.e., ViLBERT, VisualBERT and B2T2, VL-BERT achieves the state-of-the-art performance.
3.2. Visual Question Answering (VQA)
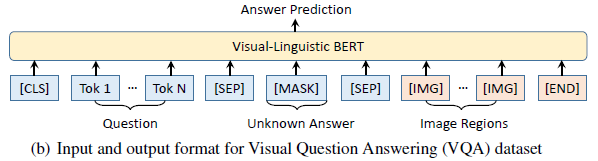
- In the VQA task, given a natural image, a question at the perceptual level is asked, and the algorithm should generate / choose the correct answer.
- The input format for the VQA task is <Question, Answer, Image>.
- During fine-tuning, the network training is driven by the multi-class cross-entropy loss over the possible answers.
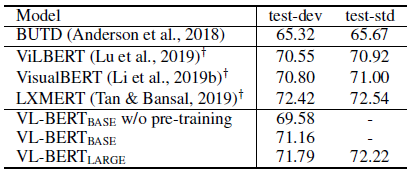
- Pre-training VL-BERT improves the performance by 1.6%, which validates the importance of pre-training.
VL-BERT surpasses BUTD by over 5% in accuracy. Except for LXMERT, VL-BERT achieves better performance than the other concurrent works.
- This is because LXMERT is pre-trained on massive visual question answering data (aggregating almost all the VQA datasets based on COCO and Visual Genome), while VL-BERT is only pre-trained on captioning and text-only dataset.
3.3. Referring Expression Comprehension (RefCOCO+)
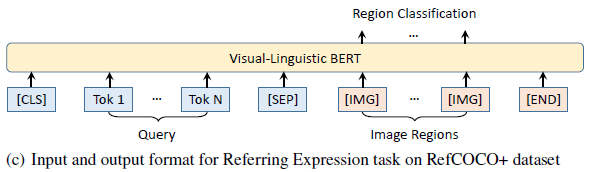
- A referring expression is a natural language phrase that refers to an object in an image. The referring expression comprehension task is to localize the object in an image with the given referring expression.
- The input format is of <Query, Image>.
- During training, the classification scores are computed for all the input RoIs. For each RoI, a binary classification loss is applied.
- During inference, the RoI with the highest classification score is directly chosen as the referred object of the input referring expression.
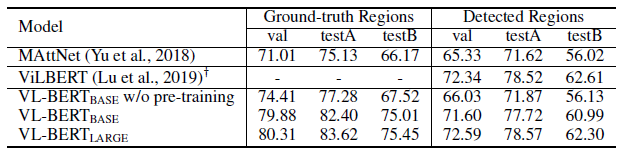
- Pre-trained VL-BERT significantly improves the performance.
Compared with MAttNet, VL-BERT is much simpler without task-specific architecture designs, yet much better. VL-BERT achieves comparable performance with the concurrent work of ViLBERT.
3.4. Ablation Study
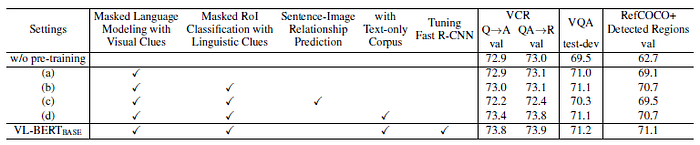
- By comparing setting (a) to that of “w/o pre-training”, we see the benefits of Task #1, Masked Language Modeling with Visual Clues.
- By further incorporating Task #2, Masked RoI Classification with Linguistic Clues, the accuracy further improves on RefCOCO+, but gets stuck at VCR and VQA.
- Setting (c) incorporates the task of Sentence-Image Relationship Prediction as in ViLBERT and LXMERT. It would hurt accuracy on all the three downstream tasks.
- Setting (d) adds text-only corpus during pre-training. Compared with setting (b), it improves the performance over all three down-stream tasks, and is most significant on VCR. This is because the task of VCR involves more complex and longer sentences than those in VQA and RefCOCO+.
Recent years, papers start to propose a generic representation for visual-linguistic tasks, instead of using ad-hoc task-specific modules.
Reference
[2020 ICLR] [VL-BERT]
VL-BERT: Pre-training of Generic Visual-Linguistic Representations
5.1. Visual/Vision/Video Language Model (VLM)
2019 [VideoBERT] [VisualBERT] [LXMERT] [ViLBERT] 2020 [ConVIRT] [VL-BERT]
