Review: Semi-Supervised Sequence Tagging with Bidirectional Language Models (TagLM)
Sequence Tagging Using Bidirectional LSTM and Pretrained Language Model
In this story, Semi-Supervised Sequence Tagging with Bidirectional Language Models, (TagLM), by Allen Institute for Artificial Intelligence, is briefly reviewed. It is found that in many NLP tasks, models are trained on relatively little labeled data. In this paper:
- Sequence tagging aims to predict a linguistic tag for each word such as the part-of-speech (POS) tagging, text chunking, and named entity recognition (NER). Besides language problem, it can also be used in DNA sequence tagging for A, C, G, T.
- Language-Model Augmented Sequence Tagger (TagLM) is proposed where pretrained context embeddings from bidirectional language models are added to NLP systems and particularly applied to sequence labeling tasks.
This is a paper in 2017 ACL with over 500 citations. (Sik-Ho Tsang @ Medium) This paper builds a fundamental for ELMo, which is a 2018 NAACL paper with over 8000 citations.
Outline
- TagLM Overview
- TagLM: Network Architecture
- Experimental Results
1. TagLM Overview

- After pre-training word embeddings and a neural LM on large, unlabeled corpora (Step 1), the word and LM embeddings are extracted for every token in a given input sequence (Step 2) and use them in the supervised sequence tagging model (Step 3).
The unsupervised pre-trained word embedding model (grey) is to boost the performance of the supervised recurrent language model (orange).
2. TagLM: Network Architecture

2.1. Token Representation (Bottom-Left)
- Given a sentence of tokens (t1; t2, …, tN) it first forms a representation, xk, for each token by concatenating a character based representation ck with a token embedding wk:

- The character representation ck captures morphological information and is either by a CNN or RNN.
- The token embeddings, wk, are obtained as a lookup E(.), initialized using pre-trained word embeddings, and fine tuned during training.
2.2. Sequence Representation (Top-Left)
- To learn a context sensitive representation, multiple layers of bidirectional RNNs are used.
- For each token position, k, the hidden state hk,i of RNN layer i is formed by concatenating the hidden states from the forward and backward RNNs. As a result, the bidirectional RNN is able to use both past and future information to make a prediction at token k.
- In this paper, L = 2 layers of RNNs are used, either GRU or LSTM.
- More formally, for the first RNN layer that operates on xk to output hk,1:
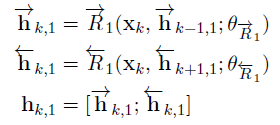
- The second RNN layer is similar and uses hk,1 to output hk,2.
- Finally, the output of the final RNN layer hk,L is used to predict a score for each possible tag using a single dense layer.
- Conditional Random Field (CRF) is used to train since there are dependencies between successive tags.
2.3. Bidirectional LM (Right)
- There is the forward LM embedding of the token at position k and is the output of the top LSTM layer in the language model. The language model predicts the probability of token tk+1 using a softmax layer over words in the vocabulary.
- Similarly for backward LM embedding, to capture the future context.
- These two LMs are pretrained using large corpus.
- After pre-training the forward and backward LMs separately, the top layer softmax is removed and the forward and backward LM embeddings are concatenated.
2.4. Combining LM with Sequence Model (Middle)
- TagLM uses the LM embeddings as additional inputs to the sequence tagging model.
- In particular, the LM embeddings hLM is concatenated with the output from one of the bidirectional RNN layers in the sequence model.
3. Experimental Results
3.1. SOTA Comparison Without Additional Data


- In both tasks, TagLM establishes a new state of the art using bidirectional LMs.
3.2. SOTA Comparison With Additional Data


- The proposed TagLM does not use any external data, compare to those using external data.
- TagLM outperforms previous state of the art results in both tasks when external resources (labeled data or task specific gazetteers).
By using pretrained language model, performance is improved for sequence model.
Reference
[2017 ACL] [TagLM]
Semi-Supervised Sequence Tagging with Bidirectional Language Models
Natural Language Processing (NLP)
Language/Sequence Model: 2007 [Bengio TNN’07] 2013 [Word2Vec] [NCE] [Negative Sampling] 2014 [GloVe] [GRU] [Doc2Vec] 2015 [Skip-Thought] 2016 [GCNN/GLU] [context2vec] 2017 [TagLM]
Machine Translation: 2014 [Seq2Seq] [RNN Encoder-Decoder] 2015 [Attention Decoder/RNNSearch] 2016 [GNMT] [ByteNet] [Deep-ED & Deep-Att] 2017 [ConvS2S] [Transformer]
Image Captioning: 2015 [m-RNN] [R-CNN+BRNN] [Show and Tell/NIC] [Show, Attend and Tell]
