Review — RoBERTa: A Robustly Optimized BERT Pretraining Approach
RoBERTa, Better Hyperparameters to pretrain BERT
RoBERTa: A Robustly Optimized BERT Pretraining Approach
RoBERTa, by University of Washington, and Facebook AI
2019 arXiv, Over 2700 Citations (Sik-Ho Tsang @ Medium)
Natural Language Processing, NLP, Language Model, BERT
Outline
- RoBERTa Modification Summary
- Robustly optimized BERT approach (RoBERTa)
- Experimental Results
1. RoBERTa Modification Summary
- The modifications are simple, they include:
- Training the model longer, with bigger batches, over more data.
- Removing the next sentence prediction objective.
- Training on longer sequences.
- Dynamically changing the masking pattern for the training data.
- A large new dataset (CC-NEWS) of comparable size to other privately used datasets is collected, to better control for training set size effects.
2. Robustly optimized BERT approach (RoBERTa)
2.1. Static vs. Dynamic Masking
- The original BERT implementation performed masking once during data preprocessing, resulting in a single static mask.
- For dynamic masking, the masking pattern is changed every time when a sequence is fed to the model.

- The reimplementation with static masking performs similar to the original BERT model, and dynamic masking is comparable or slightly better than static masking.
2.2. Model Input Format and Next Sentence Prediction
- In the original BERT pretraining procedure, the model observes two concatenated document segments, which are either sampled contiguously from the same document (with p = 0.5) or from distinct documents.
- The model is trained to predict whether the observed document segments come from the same or distinct documents via an auxiliary Next Sentence Prediction (NSP) loss.
- In RoBERTa (DOC-SENTENCES), each input is packed with full sentences sampled contiguously from one document. The NSP loss is removed.

- DOC-SENTENCES obtains better performance.
2.3. Training with Large Batches

- Originally, BERTBASE is trained for 1M steps with a batch size of 256 sequences.
- Training with large batches improves perplexity for the masked language modeling objective, as well as end-task accuracy.
- Large batches are also easier to parallelize via distributed data parallel training, and RoBERTa trains with batches of 8K sequences.
2.4. Text Encoding
- The original BERT uses a character-level BPE vocabulary of size 30K.
- RoBERTa instead considers training BERT with a larger byte-level BPE vocabulary containing 50K subword units.
2.5. CC-NEWS
- CC-NEWS is collected from the English portion of the CommonCrawl News dataset (Nagel, 2016). The data contains 63 million English news articles crawled between September 2016 and February 2019. (76GB after filtering).
3. Experimental Results

RoBERTa provides a large improvement over the originally reported BERTLARGE results.
- Further improvements are observed in performance across all downstream tasks, validating the importance of data size and diversity in pretraining.
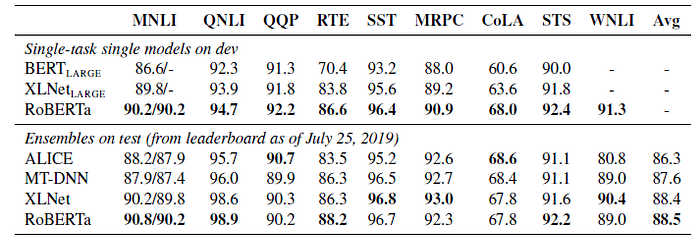
- In the first setting (single-task, dev), RoBERTa achieves state-of-the-art results on all 9 of the GLUE task development sets.
- In the second setting (ensembles, test), RoBERTa is submitted to the GLUE leaderboard and achieve state-of-the-art results on 4 out of 9 tasks and the highest average score to date (at that moment). This is especially exciting because RoBERTa does not depend on multi-task finetuning.
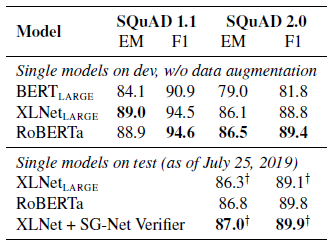
- On the SQuAD v1.1 development set, RoBERTa matches the state-of-the-art set by XLNet.
- On the SQuAD v2.0 development set, RoBERTa sets a new state-of-the-art, improving over XLNet by 0.4 points (EM) and 0.6 points (F1).
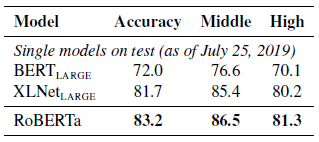
- RoBERTa achieves state-of-the-art results on both middle-school and high-school settings.
Though RoBERTa improves BERT with SOTA results, it is unfortunate that RoBERTa is rejected in 2020 ICLR since the reviewers think that most of the findings are obvious (careful tuning helps, more data helps). And the novelty and technical contributions are rather limited. (From OpenReview)
Reference
[2019 arXiv] [RoBERTa]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Natural Language Processing (NLP)
Language/Sequence Model: 2007 [Bengio TNN’07] 2013 [Word2Vec] [NCE] [Negative Sampling] 2014 [GloVe] [GRU] [Doc2Vec] 2015 [Skip-Thought] 2016 [GCNN/GLU] [context2vec] [Jozefowicz arXiv’16] [LSTM-Char-CNN] 2017 [TagLM] [CoVe] [MoE] 2018 [GLUE] [T-DMCA] [GPT] [ELMo] 2019 [T64] [Transformer-XL] [BERT] [RoBERTa]
Machine Translation: 2014 [Seq2Seq] [RNN Encoder-Decoder] 2015 [Attention Decoder/RNNSearch] 2016 [GNMT] [ByteNet] [Deep-ED & Deep-Att] 2017 [ConvS2S] [Transformer] [MoE] [GMNMT]
Image Captioning: 2015 [m-RNN] [R-CNN+BRNN] [Show and Tell/NIC] [Show, Attend and Tell]
