Brief Review — ViT-YOLO:Transformer-Based YOLO for Object Detection
Incorporate Vision Transformer (ViT) into YOLOv4

ViT-YOLO:Transformer-Based YOLO for Object Detection
ViT-YOLO, by Xidian University
2021 ICCV Workshop, Over 130 Citations (Sik-Ho Tsang @ Medium)Object Detection
2014 … 2022 [Pix2Seq] [MViTv2] [SF-YOLOv5] [GLIP] [TPH-YOLOv5++] [YOLOv6] 2023 [YOLOv7] [YOLOv8] 2024 [YOLOv9]
==== My Other Paper Readings Are Also Over Here ====
- ViT-YOLO is proposed where an improved backbone MHSA-Darknet is designed to retain sufficient global context information and extract more differentiated features for object detection via multi-head self-attention.
- Regarding the path-aggregation neck, a simple yet highly effective weighted bi-directional feature pyramid network (BiFPN) is used for effectively cross-scale feature fusion.
- In addition, other techniques including test-time augmentation (TTA) and weighted boxes fusion (WBF) are also utilized.
Outline
- ViT-YOLO
- Results
1. ViT-YOLO
1.1. Overall Framework

- YOLOv4-P7 is used as baseline for ViT-YOLO, in which ViT-YOLO is divided into 3 parts.
For the first part, MHSA-Darknet is used as the backbone which integrates multi-head self-attention into original CSP-Darknet to extract more differentiated features.
The second processing component BiFPN in substitution for PANet aims to aggregate features from different backbone levels for different detector levels.
For the third part, the general YOLO detection heads are employed for predicting boxes at 5 different scales.
1.2. MHSA-Darknet

- [22] indicated that vision transformers are much more highly robust to severe occlusions, perturbations and domain shifts, compared to CNNs.
The Transformer layer is only applied on the P7, rather than P3,P4,P5, and P6 due to large memory consumption and large computation by self-attention.
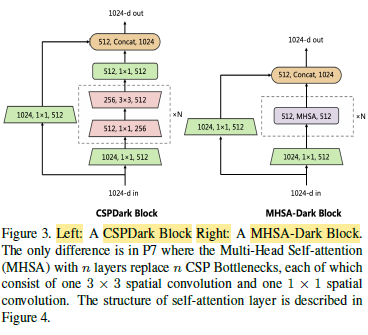
The P7 stack in the Darknet backbone typically uses 7 CSP bottleneck blocks with one spatial 1×1 convolution and one spatial 3×3 convolution in each. Replacing them with MHSA layers forms the basis of the MHSA-Darknet architecture.
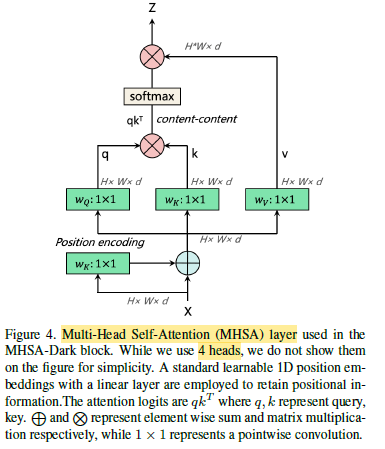
In ViT-YOLO MHSA layer, only 4 heads are used.
1.3. Weighted Bi-directional Feature Pyramid Network (BiFPN)
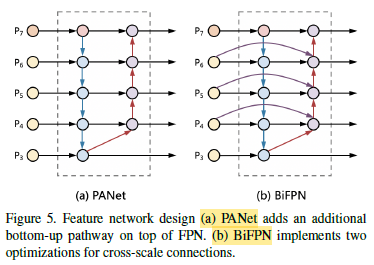
- The conventional PANet aggregates multi-scale features in a simple summing manner:
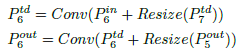
The proposed BiFPN integrates both the bidirectional cross-scale connections and the fast normalized fusion with learnable weights:
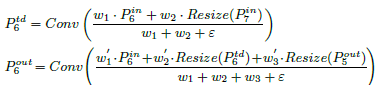
1.4. Test-Time Augmentation (TTA) and Multi-Model Fusion
- With TTA, multiple augmented copies of each image (such as zooms, flips, shifts, and more) in the test set are used.
- Weighted Boxes Fusion (WBF) is used as the multi-model fusion. WBF utilizes confidence scores of all proposed bounding boxes to construct the averaged boxes. Several models are trained on visdrone dataset, including the YOLOv5 models, YOLOv4 models and our ViT-YOLO model to predict boxes then ensemble.
2. Results
2.1. Ablation Studies


After integrating multi-head self-attention into the original CSP-Darknet, the total mAP of results is significantly boosted from 35.43 To 37.56, which explains the reason why the Transformer-based model which focuses on global context information is helpful for accurately detecting small objects.
2.2. SOTA Comparisons
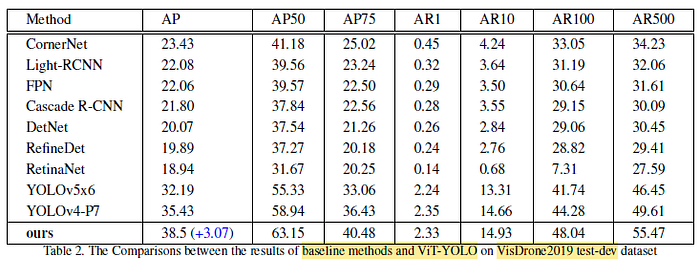
ViT-YOLO outperforms SOTA comparisons such as CornerNet, FPN, Cascade R-CNN, RefineNet, YOLOv4 and YOLOv5.
