Brief Review — YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications
YOLOv6, Formed by Adopting Recent Object Detection Advancements from Industry and Academy, Outperforms YOLOv5, YOLOX, YOLOv7

YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications
YOLOv6, by Meituan Inc.
2022 arXiv v1, Over 1000 Citations (Sik-Ho Tsang @ Medium)Object Detection
2014 … 2021 [Scaled-YOLOv4] [PVT, PVTv1] [Deformable DETR] [HRNetV2, HRNetV2p] [MDETR] [TPH-YOLOv5] 2022 [Pix2Seq] [MViTv2] [SF-YOLOv5] [GLIP] [TPH-YOLOv5++] 2023 [YOLOv7]
==== My Other Paper Readings Are Also Over Here ====
- In this paper, object detection advancements either from industry or academy are heavily assimilated from recent network design, training strategies, testing techniques, quantization and optimization methods.
Outline
- YOLOv6
- Results
1. YOLOv6
- There are bunched of techniques applied to YOLOv6.

1.1. Network Design

Backbone: RepBlock in RepVGG is used as the building block of the small networks. For large models, a more efficient CSP block in CSPNet is revised, as CSPStackRep Block.
Neck: The neck of YOLOv6 adopts PAN topology following YOLOv4 and YOLOv5. The neck is enhanced with RepBlocks or CSPStackRep Blocks to have RepPAN.
Head: The decoupled head, from the idea in YOLOX, is simplified to make it more efficient, called Efficient Decoupled Head.
1.2. Label Assignment
- Label assignment is responsible for assigning labels to predefined anchors during the training stage.
Task Alignment Learning (TAL) was first proposed in TOOD, in which a unified metric of classification score and predicted box quality is designed. The IoU is replaced by this metric to assign object labels.
- TAL is used as the default label assignment strategy in YOLOv6.
1.3. Loss Functions

- The loss function is composed of a classification loss, a box regression loss and an optional object loss.
1.3.1. Classification Loss
- VariFocal Loss (VFL) in VariFocalNet, which is based on Focal Loss, is used for the classification loss.
1.3.2. Box Regression Loss
- SIoU [8] is applied to YOLOv6-N and YOLOv6-T, while others use GIoU.
- Distribution Focal Loss (DFL) [20] is used in YOLOv6-M/L.
1.3.3. Object Loss
- Object loss was first proposed in FCOS. It does not bring any improvements unfortunately.
1.4. Industry-handy Improvements
- The training duration: is extended from 300 epochs to 400 epochs.
- Self-distillation: is used by minimizing the KL-divergence between the prediction of the teacher and the student. The knowledge distillation loss is:
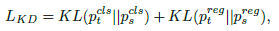
- The overall loss function is now formulated as:
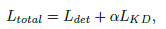
- Mosaic augmentations (in YOLOv4): are turned off during last epochs.
1.5. Quantization and Deployment
- Post-training quantization (PTQ) directly quantizes the model with only a small calibration set.
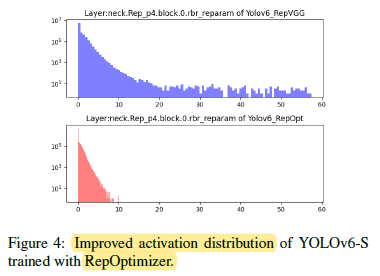
- RepOptimizer [2] is used to have gradient re-parameterization at each optimization step. The re-parameterization blocks of YOLOv6 are reconstructed in this fashion and trained with RepOptimizer to obtain PTQ-friendly weights.
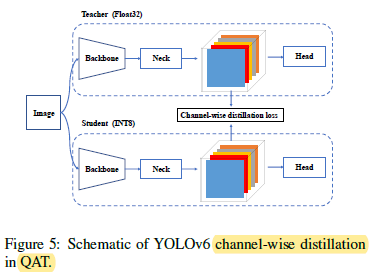
- Besides, channel-wise distillation [36] (later as CW Distill) is adapted within the YOLOv6 framework. This is also a self-distillation approach where the teacher network is the student itself in FP32-precision.


