Review — DeFINE: Deep Factorized Input Token Embeddings for Neural Sequence Modeling
DeFINE, Parameter Reduction for Input Token Embedding

DeFINE: Deep Factorized Input Token Embeddings for Neural Sequence Modeling,
DeFINE, by University of Washington, and Allen Institute for AI
2020 ICLR, Over 10 Citations (Sik-Ho Tsang @ Medium)
Natural Language Processing, NLP, Language Model, LM, Neural Machine Translation, NMT, Transformer, Transformer-XL
- A hierarchical structure with novel skip-connections are proposed, which allows for the use of low dimensional input and output layers, reducing total parameters and training time while delivering similar or better performance versus existing methods.
- DeFINE can be incorporated easily in new or existing sequence models.
Outline
- Hierarchical Group Transformation (HGT)
- DeFINE Unit
- Results
1. Hierarchical Group Transformation (HGT)

1.1. Motivations & Overall Idea
- Most NLP researches uses shallow network to learn a good approximation for token embedding.
- DeFINE, an effective way of learning deep token representations in high-dimensional space with a minimum of additional parameters.
- The proposed method is based on a Map-Expand-Reduce (MER) principle, first maps an input token to a low dimensional embedding vector, then transforms it to a high-dimensional space using a computationally efficient hierarchical group transformation (HGT).
- The resultant vector is then transformed to a low-dimensional space.
- By making use of a new connectivity pattern that establishes a direct link between the input and output layers, promoting feature reuse, and improving gradient flow.
1.2. Map-Expand-Reduce (MER)
- The first step in MER, Map, is similar to standard sequence models. Every input token in the vocabulary V is mapped to a fixed dimensional vector ei of size n×1. However, in this paper, the value of n is small (say 64 or 128, compared to typical dimensions of 400 or more).
- The next step, Expand, takes ei as an input and applies a hierarchical group transformation (HGT) to produce a very high-dimensional vector ^ei of size k×1, where k>>n.
- The last step, Reduce, projects the vector ^ei to a lower dimensional space to produce the final embedding vector eo of size m×1 for a given input token.
- The dimensions of eo can be matched to contextual representation models, such as LSTMs or Transformers, allowing DeFINE to serve as an input layer for these models.
1.3. Hierarchical Group Transformation (HGT)
- HGT comprises of a stack of N layers.
- HGT starts with gmax groups at the first layer and then subsequently decreases the number of groups by a factor of 2 at each level.
- (Group linear transformations (GLT), originally introduced to improve the efficiency of the LSTM, also sparsify the connections in fully connected layer, as shown above. However, the outputs of a certain group are only derived from a small fraction of the input, thus learning weak representations.)
- Formally, in HGT, the transformation from ei to ^ei at l-th layer is:
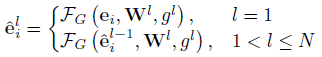
- where:
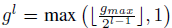
- And Wl are the weights learned at l-th layer, and FG is a group transformation function.
- Group transformation splits the input into g groups, each of which is processed independently using a linear transformation. The output of these groups are then concatenated to produce final output.
2. DeFINE Unit

- The DeFINE unit is composed of HGT transformations.
- A simple new skip-connection is used that establishes a direct link between any layer in HGT with the input ei, as above.
- The input and the output are chunked into gl groups using a split layer. The chunked input and output vectors are then mixed.
This mechanism promotes input feature reuse efficiently. Additionally, it establishes a direct link with the input ei, allowing gradients to flow back to the input via multiple paths and resulting in improved performance.
- The mapping between the input token and the output of the DeFINE unit (eo), can be cached using look-up table, resulting in a mechanism that allows to skip the computations of the DeFINE unit at inference time.
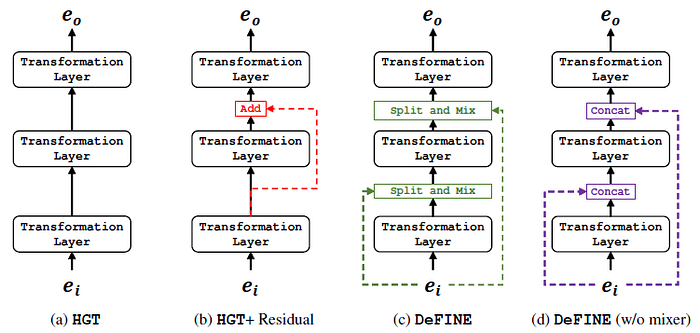
- This figure summarizes different architectures with different settings.
3. Results
3.1. LSTM Models

- (a): The proposed method further improves performance by about 3 points while learning only 1.25% (or 0.4 million) more parameters.
(b): The depth of DeFINE is scaled from 3 to 11 layers. The performance improves by a further 6 points, delivering competitive performance to existing RNN-based methods with fewer parameters (e.g., 1/3 as many parameters as Merity et al. (2018a)).
- (c): The proposed method improves the performance of AWD-LSTM by 4 points while simultaneously reducing the number of parameters by 4 million.
3.2. Transformer Models
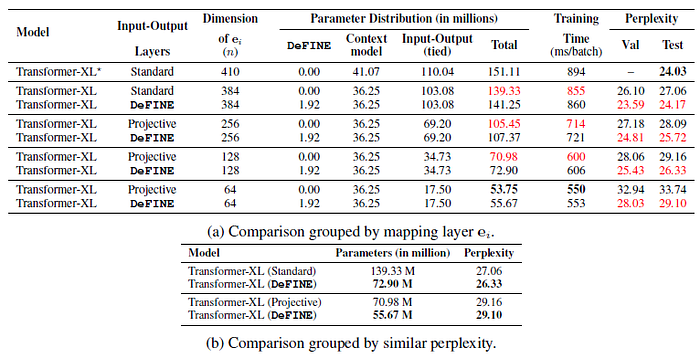
- The proposed method is able to attain similar performance to Dai et al. (2019) while learning 10M fewer parameters.
Transformer-XL with DeFINE is able to achieve comparable perplexity to a standard Transformer-XL with projective embeddings while using significantly fewer parameters.
3.3. Machine Translation
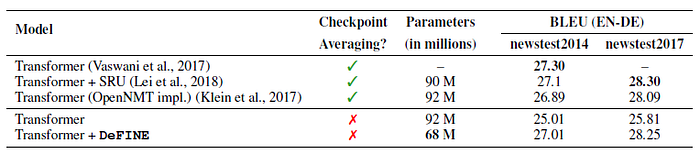

- OpenNMT is used for Transformer model training.
DeFINE improves the performance of the Transformer model without checkpoint averaging by 2% while simultaneously reducing the total number of parameters by 26%, suggesting that DeFINE is effective.
3.4. Further Analyses & Ablations
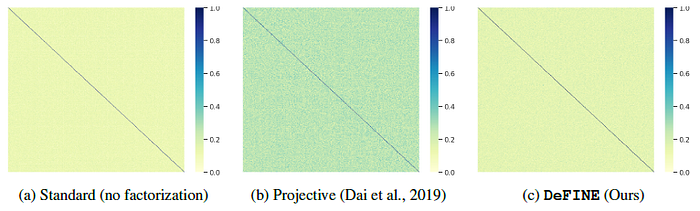
DeFINE is able to approximate the standard embedding matrix efficiently.
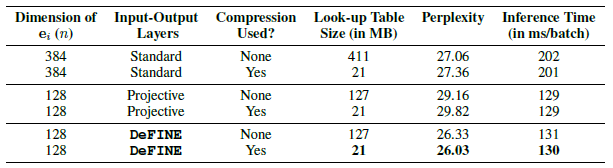
DeFINE embeddings can be compressed similarly to standard embeddings without loss of performance.
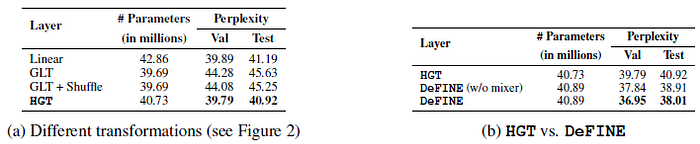
Left: HGT improves perplexity by about 5 points while learning a similar number of parameters as GLT.
Right: Furthermore, when a direct connection is used, the performance further improves by 2.9 points.
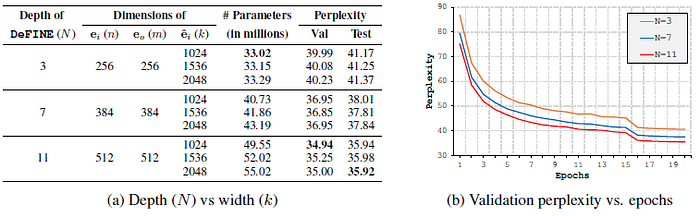
For the same value of k, the performance of the language model improves with the increase in the depth N. However, when we scale the width k for a fixed value of depth N, the performance does not improve.

Left: The proposed skip-connections are more effective.
Right: The performance with and without this reduction step is similar, however, a model without the reduction step, learns more parameters.
Reference
[2020 ICLR] [DeFINE]
DeFINE: Deep Factorized Input Token Embeddings for Neural Sequence Modeling
2.1. Language Model / Sequence Model
1991 … 2020 … [DeFINE] 2021 [Performer] [gMLP] [Roformer] [PPBERT] [DeBERTa] 2022 [GPT-NeoX-20B] [InstructGPT]
2.2. Machine Translation
2013 … 2020 [Batch Augment, BA] [GPT-3] [T5] [Pre-LN Transformer] [OpenNMT] [DeFINE] 2021 [ResMLP] [GPKD] [Roformer]
