Review: Exploring the Limits of Language Modeling
CNN Input & CNN Softmax
In this story, Exploring the Limits of Language Modeling, by Google Brain, is briefly reviewed. There are two key challenges: corpora and vocabulary sizes, and complex, long term structure of language. In this paper:
- A Softmax loss is designed, which is based on character level CNNs, is efficient to train, and is as precise as a full Softmax which has orders of magnitude more parameters.
- An exhaustive study is done on techniques such as character Convolutional Neural Networks (CNN) or Long-Short Term Memory (LSTM), on the One Billion Word Benchmark.
This is a paper in 2016 arXiv with over 1000 citations. (Sik-Ho Tsang @ Medium)
Outline
- Full Softmax
- CNN Input & CNN Softmax
- Experimental Results
1. Full Softmax

- Standard LSTM Language Model (LM) uses full softmax to predict the word, it needs to estimate the the probability vector using the whole vocabulary V which takes a lot of time:

- where zw is the logit corresponding to a word w.
- Hierarchical softmax, NCE, or Important Sampling needs to be used to approximate full softmax.
2. CNN Input & CNN Softmax
- The character-level features allow for a smoother and compact parametrization of the word embeddings.
- For the Character-level LM that consume characters as inputs or as targets, each word is fed to the model as a sequence of character IDs.
- The total number of characters are very limited.
- The full Softmax computes a logit zw as:

- where h is a context vector and ew the word embedding.
2.1. Character CNN as Input and Output

- Instead of building a matrix of |V|×|h| (whose rows correspond to ew), CNN Softmax produces ew with a CNN over the characters of w as:
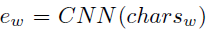
- Also, the input is also a CNN Input:

2.2. Character CNN as Input, Next character prediction LSTM as Output
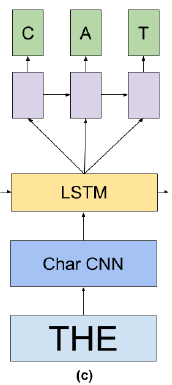
- In this LM, the word and character-level models are combined by feeding a word-level LSTM hidden state h into a small LSTM that predicts the target word one character at a time.
- The standard LSTM model is trained until convergence, then its weights, are frozen. And the standard word-level Softmax layer is replaced with the aforementioned character-level LSTM.
3. Experimental Results

- The 1B word benchmark dataset contains about 0.8B words with a vocabulary of 793471 words.
2-LAYER LSTM-8192–1024 (BIG LSTM) obtains 30.6 Test Perplexity. This is a word-level LSTM model, with 1.8B number of parameters.
BIG LSTM+CNN INPUTS obtains a little better of 30.0 Test Perplexity, with only 1.04B number of parameters only.
- BIG LSTM+CNN INPUTS+CNN SOFTMAX, adding CNN SOFTMAX does not help.
- Using Char LSTM Predictions as in 2.2, even worse performance.
- (Please feel free to read other results if interested.)
- Finally, 2-LAYER LSTM-8192–1024 (BIG LSTM) has been used or compared in many papers later on.
Reference
[2016 arXiv] [Jozefowicz arXiv’16]
Exploring the Limits of Language Modeling
Natural Language Processing (NLP)
Language/Sequence Model: 2007 [Bengio TNN’07] 2013 [Word2Vec] [NCE] [Negative Sampling] 2014 [GloVe] [GRU] [Doc2Vec] 2015 [Skip-Thought] 2016 [GCNN/GLU] [context2vec] [Jozefowicz arXiv’16] 2017 [TagLM]
Machine Translation: 2014 [Seq2Seq] [RNN Encoder-Decoder] 2015 [Attention Decoder/RNNSearch] 2016 [GNMT] [ByteNet] [Deep-ED & Deep-Att] 2017 [ConvS2S] [Transformer]
Image Captioning: 2015 [m-RNN] [R-CNN+BRNN] [Show and Tell/NIC] [Show, Attend and Tell]
