Review — FAIRSEQ: A Fast, Extensible Toolkit for Sequence Modeling
FAIRSEQ for Language Model & Machine Translation, etc.
FAIRSEQ: A Fast, Extensible Toolkit for Sequence Modeling
FAIRSEQ, by Facebook AI Research, and Google Brain
2019 NAACL, Over 1400 Citations (Sik-Ho Tsang @ Medium)
Natural Language Processing, NLP, Language Model, Machine Translation, Transformer
- FAIRSEQ is proposed, which is a PyTorch-based open-source sequence modeling toolkit that allows researchers and developers to train custom models for translation, summarization, language modeling, and other text generation tasks.
- GitHub: https://github.com/pytorch/fairseq.
Outline
- FAIRSEQ Design
- FAIRSEQ Implementation
- Applications
1. FAIRSEQ Design
- Extensibility: FAIRSEQ can be extended through five types of user-supplied plug-ins, which enable experimenting with new ideas while reusing existing components as much as possible.
- Models: Models extend the BaseFairseqModel class, which in turn extends torch.nn.Module.
- Criterions: It can compute the loss given the model and a batch of data, roughly: loss=criterion(model, batch), which can be calculated on-the-fly.
- Tasks: store dictionaries, provide helpers for loading and batching data and define the training loop.
- Optimizer: provide wrappers around most PyTorch optimizers.
- Learning Rate Schedulers: provide several popular schedulers.
- Reproducibility and forward compatibility: For example, checkpoints contain the full state of the model, optimizer and dataloader. FAIRSEQ also provides forward compatibility, i.e., models trained using old versions of the toolkit.
2. FAIRSEQ Implementation
2.1. Batching
- FAIRSEQ minimizes padding within a minibatch by grouping source and target sequences of similar length.

2.2. Multi-GPU Training
- FAIRSEQ uses the NCCL2 library and torch.distributed for inter-GPU communication.
- (a): In multi-GPU or multimachine setups, this results in idle time for most GPUs while slower workers are finishing their work.
- (b): Overlapping gradient synchronization starts to synchronize gradients of parts of the network when they are computed. When the size of the buffer reaches a predefined threshold, the gradients are synchronized in a background thread while back-propagation continues as usual.
- (c): Gradients are accumulated for multiple sub-batches on each GPU which reduces the variance in processing time between workers since there is no need to wait for stragglers after each sub-batch.
2.3. Mixed Precision
- All forward-backward computations as well as the all-reduce for gradient synchronization between workers are performed in FP16. However, the parameter updates remain in FP32.
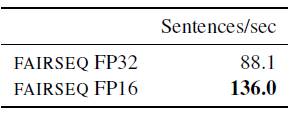
2.4. Inference
- FAIRSEQ provides fast inference for non-recurrent models through incremental decoding, where the model states of previously generated tokens are cached in each active beam and re-used.
- FAIRSEQ also supports inference in FP16 which increases decoding speed by 54% compared to FP32 with no loss in accuracy, as shown above.
3. Applications
3.1. Machine Translation

- A “big” Transformer encoder-decoder model is evaluated on two language pairs, WMT English to German (En–De) and WMT English to French (En–Fr). All results use beam search with a beam width of 4 and length penalty of 0.6.
FAIRSEQ results in improved BLEU scores over the original Transformer by training with a bigger batch size and an increased learning rate.
3.2. Language Model
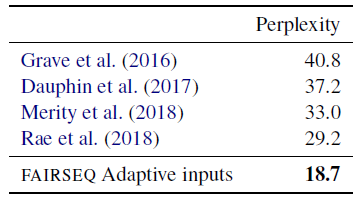
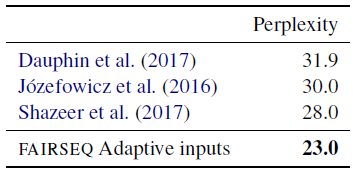
- Two Transformer language models are evaluated, which use only a decoder network and adaptive input embeddings, following Baevski and Auli (2019).
- The first model has 16 blocks, inner dimension 4K and embedding dimension 1K; results on WikiText-103.
- The second model has 24 blocks, inner dimension 8K and embedding dimension 1.5K; results on the One Billion Word benchmark.
3.3. Abstractive Document Summarization
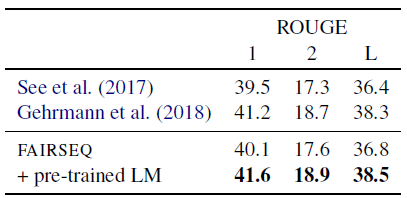
- A base Transformer, which encodes the input document and then generate a summary with a decoder network, is evaluated on the CNN-Dailymail dataset.
Reference
[2019 NAACL] [FAIRSEQ]
FAIRSEQ: A Fast, Extensible Toolkit for Sequence Modeling
Language/Sequence Model
2007 … 2019 [T64] [Transformer-XL] [BERT] [RoBERTa] [GPT-2] [DistilBERT] [MT-DNN] [Sparse Transformer] [SuperGLUE] [FAIRSEQ] 2020 [ALBERT] [GPT-3] [T5] [Pre-LN Transformer]
Machine Translation
2014 … 2018 [Shaw NAACL’18] 2019 [AdaNorm] [GPT-2] [Pre-Norm Transformer] [FAIRSEQ] 2020 [Batch Augment, BA] [GPT-3] [T5] [Pre-LN Transformer] 2021 [ResMLP]
