Review — Character-Level Language Modeling with Deeper Self-Attention
T64: Very Deep 64-Layer Character-Level Transformer
Character-Level Language Modeling with Deeper Self-Attention
T64, 64-Layer Transformer, by Google AI
2019 AAAI, Over 200 Citations (Sik-Ho Tsang @ Medium)
Natural Language Processing (NLP), Language Model, Self-Attention, Transformer
- it is difficult to train a very deep model. In this paper, a deep character (64-layer) Transformer model is proposed.
- Three auxiliary losses are proposed for the ease of training.
Outline
- Character Transformer Model
- Auxiliary losses
- Positional Embeddings
- Experimental Results
1. Character Transformer Model
- Language models assign a probability distribution over token sequences t0:L by factoring out the joint probability as follows, where L is the sequence length:

- To model the conditional probability Pr(ti|t0:i-1), a Transformer network is trained to process the character sequence t0:i-1.

- The above figure illustrates an example: A character Transformer network of two layers processing a four character sequence to predict t4.
- The proposed character-level Transformer architecture has 64 Transformer layers (T64).
- Each Transformer layer has a hidden size of 512 and a filter size of 2048. The model is fed with input sequences of length 512.
- The model has approximately 235 million parameters.
- A batch of 16 randomly selected sequences is used.
- The model’s prediction is at the final position of the final layer, which computes the probability of a character given a context of 512 characters.
- For each character predicted it has to process the context from scratch.
- The best model (T64) is achieved after around 2.5 million steps of training, which takes 175 hours on a single Google Cloud TPU v2.
Following Transformer, by “Transformer layer”, a block is meant by containing a multi-head self-attention sub-layer followed by a feed-forward network of two fully connected sub-layers.
- To ensure that the model’s predictions are only conditioned on past characters, the attention layers are masked with a causal attention, so each position can only attend leftward.
2. Auxiliary losses
- Since the 64-layer transformer is very deep model, auxiliary losses are used to help the convergence during training.
2.1. Multiple Positions

- The above illustrates the task of predicting across all sequence positions. These losses are added during training without decaying their weights.
2.2. Intermediate Layer Losses

- Predictions for all intermediate positions in the sequence are added (see the above figure).
- Lower layers are weighted to contribute less and less to the loss as training progresses. If there are n layers total, then the lth intermediate layer stops contributing any loss after finishing l/2n of the training.
- This schedule drops all intermediate losses after half of the training is done.
2.3. Multiple Targets
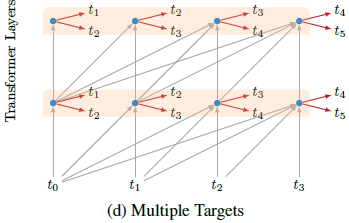
- At each position in the sequence, the model makes two (or more) predictions of future characters.
- For each new target, a separate classifier is introduced.
- The losses of the extra targets get weighted by a multiplier of 0.5 before being added to their corresponding layer loss.
3. Positional Embeddings
- In the basic Transformer network, a sinusoidal timing signal is added to the input sequence prior to the first Transformer layer.
- However, as the network is deeper (64 layers), it is hypothesized that the timing information may get lost during the propagation through the layers.
- To address this, the timing signal is replaced with a learned per-layer positional embedding added to the input sequence before each Transformer layer.
- Specifically, the model learns a unique 512-dimensional embedding vector for each of the L context positions within each of N layers, giving a total of L×N×512 additional parameters.
4. Experimental Results
4.1. Datasets
- text8 (Mahoney 2009): This dataset consists of English Wikipedia articles, with superfluous content removed (tables, links to foreign language versions, citations, footnotes, markup, punctuation).
- The remaining text is processed to use a minimal character vocabulary
of 27 unique characters — lowercase letters a through
z, and space. Digits: e.g.: “20” becomes “two zero”. - The size of the corpus is 100M characters. 90M characters for train,
5M characters for dev, and 5M characters for test. - enwik8 (Mahoney 2009): which is 100M bytes of unprocessed Wikipedia text, including markup and non-Latin characters.
- There are 205 unique bytes in the dataset. 90M, 5M and 5M for training,
dev and test respectively.
4.2. SOTA Comparison

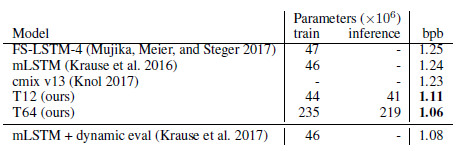
- T64 achieves a new state of the art, 1.13 bpc. This model is 5× larger than previous models.
- A smaller model (T12) with 41M parameters is trained. This model consists of 12 layers, and trained for 8M steps. This smaller model still outperforms previous models, achieving 1.18 bpc on the test dataset.
- Increasing the depth of the network from 12 layers to 64 improved the results significantly,
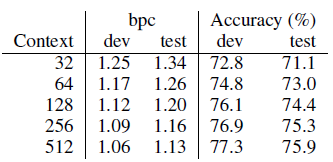
- State-of-the-art results are achieved once the context increases beyond 128 characters, with the best performance of 1.06 bpc at 512 characters. As expected, the model performs better when it is given more context.
- However this trend levels off after 512 characters, we do not see better results using a context of 1024.
4.3. Ablation Experiments
- On enwik8, without retuning for this dataset, the proposed models still achieve state-of-the-art performance.

- The biggest win comes from adding multiple positions and intermediate layers losses.
4.3. Comparison with Word-Level Models
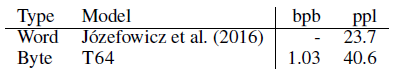
- Compared with Jozefowicz arXiv’16, there is a gap in performance between the two classes of language models. This comparison can serve as a starting point for researching possible ways to bridge the gap.
4.4. Qualitative Analysis

Reference
[2019 AAAI] [T64]
Character-Level Language Modeling with Deeper Self-Attention
Natural Language Processing (NLP)
Language/Sequence Model: 2007 [Bengio TNN’07] 2013 [Word2Vec] [NCE] [Negative Sampling] 2014 [GloVe] [GRU] [Doc2Vec] 2015 [Skip-Thought] 2016 [GCNN/GLU] [context2vec] [Jozefowicz arXiv’16] [LSTM-Char-CNN] 2017 [TagLM] [CoVe] [MoE] 2018 [GLUE] [T-DMCA] [GPT] [ELMo] 2019 [T64] [BERT]
Machine Translation: 2014 [Seq2Seq] [RNN Encoder-Decoder] 2015 [Attention Decoder/RNNSearch] 2016 [GNMT] [ByteNet] [Deep-ED & Deep-Att] 2017 [ConvS2S] [Transformer] [MoE]
Image Captioning: 2015 [m-RNN] [R-CNN+BRNN] [Show and Tell/NIC] [Show, Attend and Tell]
