Review —FixRes: Fixing the Train-Test Resolution Discrepancy
Larger Crop During Testing, Plus Fine-Tuning, Improves Accuracy

Fixing the Train-Test Resolution Discrepancy
FixRes, by Facebook AI Research
2019 NeurIPS, Over 200 Citations (Sik-Ho Tsang @ Medium)
Image Classification
- Existing augmentations induce a significant discrepancy between the size of the objects seen by the classifier at train and test time.
- Two techniques are proposed to solve this problem.
- Different train and test resolutions are employed.
- A computationally cheap fine-tuning is used.
Outline
- Train-Test Resolution Discrepancy
- Proposed techniques
- Experimental Results
1. Significant Discrepancy Between the Size of the Objects
- The training practice is to extract a rectangle with random coordinates from the image, which artificially increases the amount of training data. This region, is called the Region of Classification (RoC).
- At test time, the RoC is instead set to a square covering the central part of the image, which results in the extraction of a so called “center crop”.
While the crops extracted at training and test time have the same size, they arise from different RoCs, which skews the distribution of data seen by the CNN.
2. Proposed techniques
2.1. Larger Test Crops
- One way is to increase the test crop size. It reduces the train-test object size mismatch.
- However, this skews the activation statistics. Thus, fine-tuning is needed.
2.2. Resolution Adaptation by Fine-Tuning
- Fine-tuning is restricted to the very last layers of the network using test crop size using the same training set.
- Also, the batch normalization that precedes the global pooling is also fine-tuned.
3. Results
3.1. Single Resolution Testing

- Ktrain: the crop size during training; Ktest: crop size during testing.
- Right: With fine-tuning, the best results (79%) got with the classic ResNet-50 trained at Ktrain = 224.
- Compared to when there is no fine-tuning, the Ktest at which the maximal accuracy is obtained increases from Ktest = 288 to 384.
- If we prefer to reduce the training resolution, Ktrain = 128 and testing at Ktrain = 224 yields 77.1% accuracy, which is above the baseline trained at full test resolution without fine-tuning.
3.2. Multiple Resolution Testing
- To improve the accuracy, the image is classified at several resolutions and the classification scores are averaged.
- With Ktrain = 128 and Ktest = [256, 192], the accuracy is 78.0%.
- With Ktrain = 224 and Ktest = [384, 352], the results are improved from the single-crop result of 79.0% to 79.5%.
3.3. Larger Networks
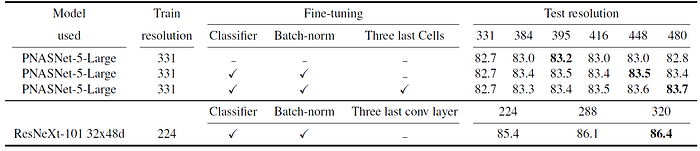
- For the PNASNet-5-Large, it is beneficial to fine-tune more than just the batch-normalization and the classifier. The three last cells are also fine-tuned. By increasing the resolution to Ktest = 480, the accuracy increases by 1 percentage point.
- By combining this with an ensemble of 10 crops at test time, we obtain 83.9% accuracy.
- With the ResNeXt-101 32x48d increasing the resolution to Ktest = 320, the accuracy increases by 1.0 percentage point. 86.4% top-1 accuracy is reached.
3.4. Speed-Accuracy Trade-Off
- In the low-resolution training regime (Ktrain = 128), the additional fine-tuning required by our method increases the training time from 111.8 h to 124.1 h (+11%). This is to obtain an accuracy of 77.1%, which outperforms the network trained at the native resolution of 224 in 133.9 h.
- A fine-tuned network with Ktest = 384 is produced that obtains a higher accuracy than the network trained natively at that resolution, and the training is 2.3× faster: 151.5 h instead of 348.5 h.
3.5. SOTA Comparison
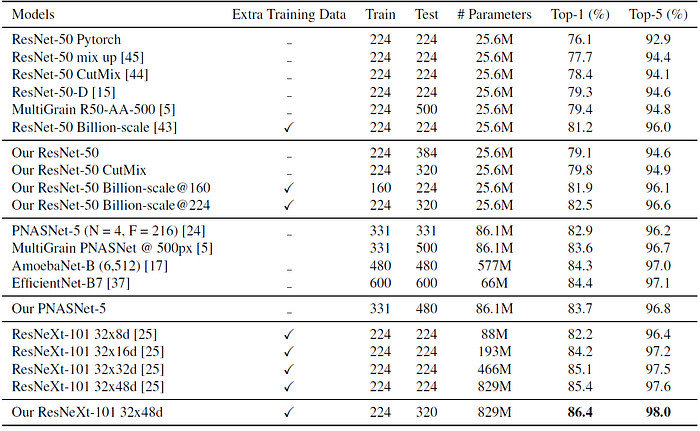
With 86.4% Top-1 accuracy and 98.0% Top-5 accuracy, it is the first model to exceed 86.0% in Top-1 accuracy and 98.0% in Top-5 accuracy on the ImageNet-2012 benchmark.
- It exceeds the previous state of the art by 1.0% absolute in Top-1 accuracy and 0.4% Top-5 accuracy.
3.6. Transfer Learning Tasks
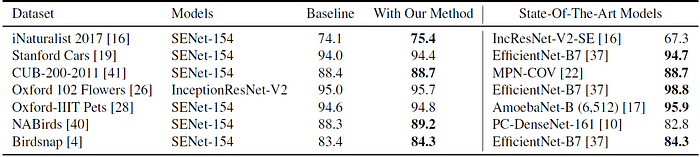
- SENet-154 and InceptionResNet-V2 are used.
- The network is initialized with the weights learned on ImageNet.
- train it entirely for several epochs at a certain resolution.
- fine-tune with a higher resolution the last batch norm and the fully connected layer.
In all cases, the proposed method improves the performance of the baseline.
- It is called FixRes because authors later on published FixEfficientNet mentioning this paper as FixRes.
Reference
[2019 NeurIPS] [FixRes]
Fixing the Train-Test Resolution Discrepancy
Image Classification
1989–2018: …
2019: [ResNet-38] [AmoebaNet] [ESPNetv2] [MnasNet] [Single-Path NAS] [DARTS] [ProxylessNAS] [MobileNetV3] [FBNet] [ShakeDrop] [CutMix] [MixConv] [EfficientNet] [ABN] [SKNet] [CB Loss] [AutoAugment, AA] [BagNet] [Stylized-ImageNet] [FixRes]
2020: [Random Erasing (RE)] [SAOL] [AdderNet]
2021: [Learned Resizer]
