Review — Stylized-ImageNet: ImageNet-Trained CNNs are Biased Towards Texture; Increasing Shape Bias Improves Accuracy and Robustness
CNN Trained on Stylized-ImageNet, Increases Shape Bias, Improves Accuracy

ImageNet-Trained CNNs are Biased Towards Texture; Increasing Shape Bias Improves Accuracy and Robustness
Stylized-ImageNet, by University of Tübingen, IMPRS-IS, and University of Edinburgh
2019 ICLR, over 1000 citations (Sik-Ho Tsang @ Medium)
Image Classification
- ImageNet-trained CNNs are strongly biased towards recognising textures rather than shapes, which is in stark contrast to human behavioural evidence.
- ResNet-50 that learns a shape-based representation when trained on ‘Stylized-ImageNet’, gains benefits such as improved object detection performance and previously unseen robustness towards a wide range of image distortions.
Outline
- Images for Psychophysical Experiments
- Stylized-ImageNet (SIN) Dataset
- Experimental Results
1. Images for Psychophysical Experiments

- Nine comprehensive and careful psychophysical experiments are performed by comparing humans against CNNs on exactly the same images, totaling 48,560 psychophysical trials across 97 observers.
- Participants had to choose one of 16 entry-level categories in “16-Classs ImageNet”.
- The same images were fed to four CNNs pre-trained on standard ImageNet, namely AlexNet, GoogLeNet, VGG-16, and ResNet-50.
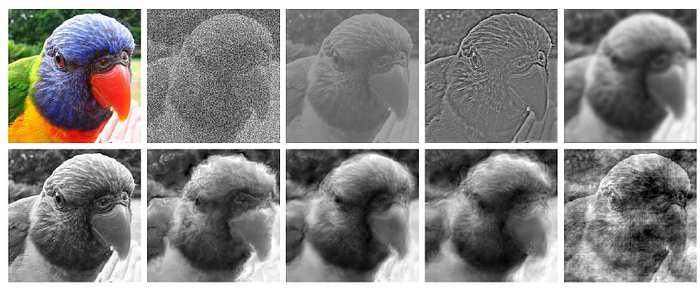
- 6 types of images are tested as shown above.
- Original: 160 natural color images of objects (10 per category) with white background.
- Greyscale: Images from Original data set converted to greyscale. (For CNNs, greyscale images were stacked along the color channel.)
- Silhouette: Images from Original data set converted to silhouette images showing an entirely black object on a white background.
- Edges: Images from Original data set converted to an edge-based representation using Canny edge extractor.
- Texture: 48 natural color images of textures (3 per category). Typically the textures consist of full-width patches of an animal (e.g. skin or fur) or, in particular for man-made objects, of images with many repetitions of the same objects (e.g. many bottles next to each other).
- Cue conflict: Images generated using iterative Image Style Transfer between an image of the Texture data set (as style) and an image from the Original data set (as content). A total of 1280 cue conflict images (80 per category) are generated. (Please read Image Style Transfer if interested.)
2. Stylized-ImageNet (SIN) Dataset

- Starting from ImageNet, a new data set (termed Stylized-ImageNet or SIN) is constructed by stripping every single image of its original texture and replacing it with the style of a randomly selected painting through AdaIN style transfer.
- AdaIN fast style transfer is used rather than iterative stylization (e.g. Gatys et al., 2016) for two reasons:
- Firstly, to ensure that training on SIN and testing on cue conflict stimuli is done using different stylization techniques, such that the results do not rely on a single stylization method.
- Secondly, to enable stylizing entire ImageNet, which would take prohibitively long with an iterative approach.
3. Experimental Results
3.1. Texture and Shape Bias in Human and ImageNet-Trained CNNs

- Almost all object and texture images (Original and Texture data set) were recognised correctly by both CNNs and humans.
- When object outlines were filled in with black colour to generate a silhouette, CNN recognition accuracies were much lower than human accuracies.
- This means that human observers cope much better with images that have little to no texture information.
One confound in these experiments is that CNNs tend not to cope well with domain shifts, i.e. the large change in image statistics from natural images.
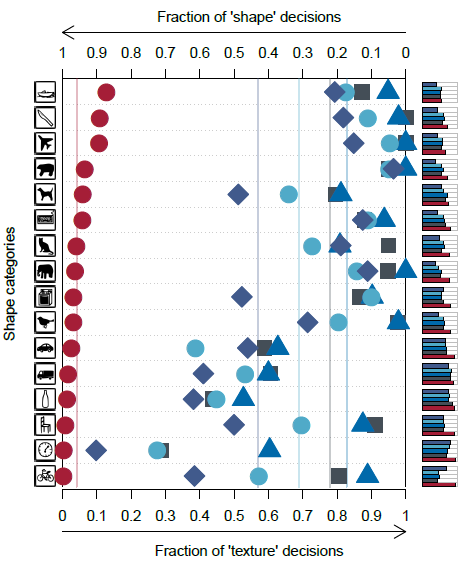
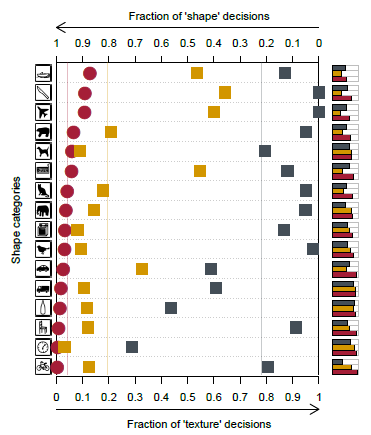
- For cue conflict experiments, Human observers show a striking bias towards responding with the shape category (95.9% of correct decisions).
- This pattern is reversed for CNNs, which show a clear bias towards responding with the texture category (VGG-16: 17.2% shape vs. 82.8% texture; GoogLeNet: 31.2% vs. 68.8%; AlexNet: 42.9% vs. 57.1%; ResNet-50: 22.1% vs. 77.9%).
3.2. Overcoming Texture Bias in CNN
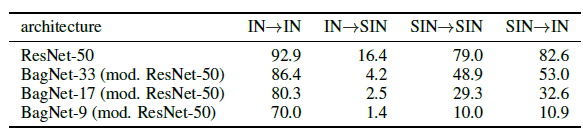
- SIN>SIN: A standard ResNet-50 trained and evaluated on Stylized-ImageNet (SIN) achieves 79.0% top-5 accuracy.
- IN>IN: In comparison, the same architecture trained and evaluated on ImageNet (IN) achieves 92.9% top-5 accuracy. This performance difference indicates that SIN is a much harder task than IN since textures are no longer predictive, but instead a nuisance factor (as desired).
- IN>SIN: Intriguingly, ImageNet features generalise poorly to SIN (only 16.4% top-5 accuracy).
SIN>IN: Yet features learned on SIN generalise very well to ImageNet (82.6% top-5 accuracy without any fine-tuning).
- In order to test whether local texture features are still sufficient to “solve” SIN, BagNets are used to evaluate the performance.
- BagNets have a ResNet-50 architecture but their maximum receptive field size is limited to 9×9, 17×17 or 33×33 pixels.
- While these restricted networks can reach high accuracies on ImageNet, they are unable to achieve the same on SIN.
This shows that the SIN data set does actually remove local texture cues, forcing a network to integrate long-range spatial information.
3.3. Robustness and Accuracy of Shape-Based Representations
- Does the increased shape bias, and thus the shifted representations, also affect the performance or robustness of CNNs?
- In addition to the IN- and SIN-trained ResNet-50 architecture, here additionally analyse two joint training schemes:
- Training jointly on SIN and IN.
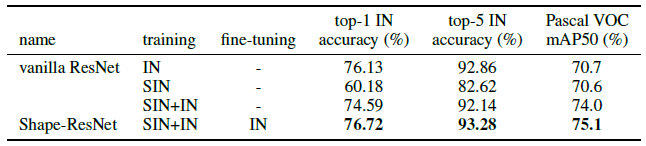
- Training jointly on SIN and IN with fine-tuning on IN, which referred as Shape-ResNet.
- Shape-ResNet obtains higher accuracy showing that SIN may be a useful data augmentation on ImageNet that can improve model performance without any architectural changes.
- While transferring backbone features for Faster R-CNN (Ren et al., 2017) on Pascal VOC 2007, incorporating SIN in the training data substantially improves object detection performance from 70.7 to 75.1 mAP50.
- A shape-based representation is more beneficial than a texture-based representation, since the ground truth rectangles encompassing an object are by design aligned with global object shape.
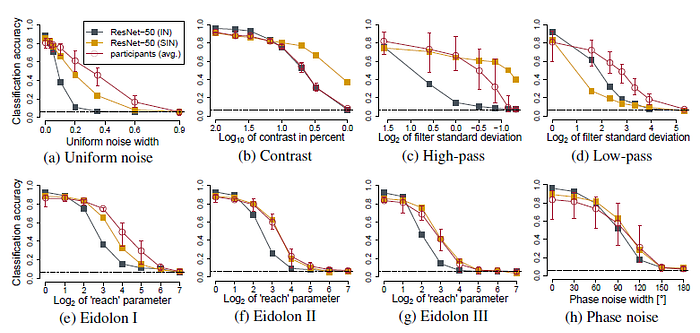
- How model accuracies degrade are also tested if images are distorted by uniform or phase noise, contrast changes, high- and low-pass filtering or eidolon perturbations.
- ResNet-50 trained on Stylized-ImageNet (SIN) is more robust towards distortions than the same network trained on ImageNet (IN).
The SIN-trained ResNet-50 approaches human-level distortion robustness — despite never seeing any of the distortions during training.
Reference
[2019 ICLR] [Stylized-ImageNet]
ImageNet-Trained CNNs are Biased Towards Texture; Increasing Shape Bias Improves Accuracy and Robustness
Image Classification
1989–2018: …
2019: [ResNet-38] [AmoebaNet] [ESPNetv2] [MnasNet] [Single-Path NAS] [DARTS] [ProxylessNAS] [MobileNetV3] [FBNet] [ShakeDrop] [CutMix] [MixConv] [EfficientNet] [ABN] [SKNet] [CB Loss] [AutoAugment, AA] [BagNet] [Stylized-ImageNet]
2020: [Random Erasing (RE)] [SAOL] [AdderNet]
2021: [Learned Resizer]
