Review — Flamingo: A Visual Language Model for Few-Shot Learning
Flamingo, Bridging Pretrained Vision Model and Language Model
Flamingo: A Visual Language Model for Few-Shot Learning,
Flamingo, by DeepMind
2022 NeurIPS, Over 250 Citations (Sik-Ho Tsang @ Medium)
Image-Text Foundation Model, Vision Language Model, Visual Language Model, VLM3.1. Visual/Vision/Video Language Model (VLM)
2017 … 2021 [CLIP] [VinVL] [ALIGN] [VirTex] [ALBEF] [Conceptual 12M (CC12M) 2022 [FILIP] [Wukong] [LiT]
My Other Previous Paper Readings Are Also Over Here
- Flamingo, Visual Language Models (VLM) is proposed, which:
- bridge powerful pretrained vision-only and language-only models,
- handle sequences of arbitrarily interleaved visual and textual data,
- seamlessly ingest images or videos as inputs.
- (This paper has 54 pages in total. I can only summarize or review the part that I think it is important to mention. Please feel free to read the paper directly if interested.)
Outline
- Flamingo Example Use Cases
- Flamingo Model Architecture
- Flamingo Training
- Results
1. Flamingo Example Use Cases

- Top: By providing the prompts with some examples, and with a question that is asked at the end, Flamingo can give the answer.
- Bottom: Flamingo can answer the questions about the image.
2. Flamingo Model Architecture

- Flamingo models the likelihood of text 𝑦 conditioned on interleaved images and videos 𝑥 as follows:
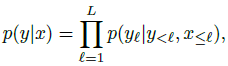
- where 𝑦ℓ is the ℓ-th language token of the input text, 𝑦<ℓ is the set of preceding tokens, 𝑥≤ℓ is the set of images/videos preceding token 𝑦ℓ in the interleaved sequence and 𝑝 is parametrized by a Flamingo model.
2.1. Visual Processing and the Perceiver Resampler
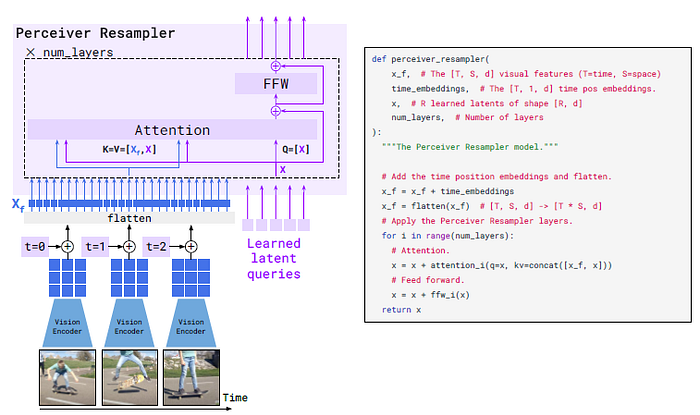
2.1.1. Vision Encoder
- A contrastive-learning-pretrained and frozen NFNet-F6 is used. The output of the final stage, a 2D spatial grid of features that is flattened to a 1D sequence.
- For video inputs, frames are sampled at 1 FPS and encoded independently to obtain a 3D spatio-temporal grid of features to which learned temporal embeddings are added.
- Features are then flattened to 1D before being fed to the Perceiver Resampler.
2.1.2. Perceiver Resampler
- Perceiver Resampler module maps a variable size grid of spatio-temporal visual features output by the Vision Encoder to a fixed number of output tokens (five in the figure), independently from the input image resolution or the number of input video frames.
- This Transformer has a set of learned latent vectors as queries, and the keys and values are a concatenation of the spatio-temporal visual features with the learned latent vectors.
2.2. Conditioning Frozen Language Models on Visual Representations
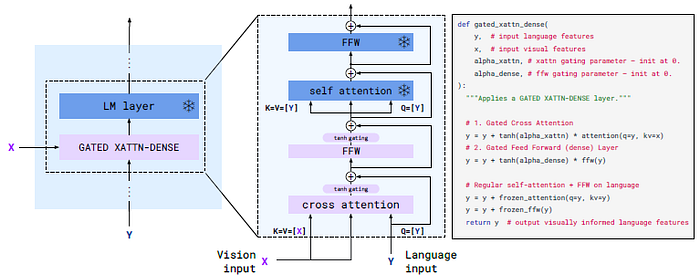
- The pretrained and frozen text-only LM blocks are interleave with blocks trained from scratch that cross-attend to the visual output from the Perceiver Resampler.
- To ensure that at initialization, the conditioned model yields the same results as the original language model, a tanh-gating mechanism is used.
2.3. Model Variants
- Three models sizes, building on the 1.4B, 7B, and 70B parameter Chinchilla models [42], called respectively Flamingo-3B, Flamingo-9B and Flamingo-80B. (Flamingo-80B is simply called as Flamingo later.)
2.4. Multi-Visual Input Support: Per-Image/Video Attention Masking
- The image-causal modelling introduced in the above equation is obtained by masking the full text-to-image cross-attention matrix.
- At a given text token, the model attends to the visual tokens of the image that appeared just before it in the interleaved sequence, rather than to all previous images.
- This single-image cross-attention scheme importantly allows the model to seamlessly generalise to any number of visual inputs.
- In particular, only up to 5 images per sequence are used when training on our interleaved datasets, yet the proposed model is able to benefit from sequences of up to 32 pairs (or “shots”) of images/videos and corresponding texts during evaluation.
3. Flamingo Training
3.1. Training on a mixture of vision and language datasets
- A mixture of three kinds of datasets, all scraped from the web: an interleaved image and text dataset derived from webpages, image-text pairs, and video-text pairs.
- 1) M3W: Interleaved image and text dataset. Both text and images are extracted from the HTML of approximately 43 million webpages.
- 2) Pairs of image and text: First leverage the ALIGN dataset, composed of 1.8 billion images paired with alt-text.
- To complement this dataset, authors collect their own dataset of image and text pairs targeting better quality and longer descriptions: LTIP (Long Text & Image Pairs) which consists of 312 million image and text pairs.
- 3) Pairs of video and text: A similar dataset but with videos instead of still images is also collected: VTP (Video & Text Pairs) consists of 27 million short videos (approximately 22 seconds on average) paired with sentence descriptions.
3.2. Multi-Objective Training and Optimisation Strategy
- The model is trained by minimizing a weighted sum of per-dataset expected negative log-likelihoods of text, given the visual inputs:
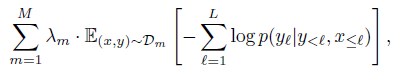
- where 𝒟𝑚 and 𝜆𝑚 are the 𝑚-th dataset and its weighting, respectively.
3.3. Task Adaptation With Few-Shot In-Context Learning
- The ability of the proposed models is evaluated to rapidly adapt to new tasks using in-context learning, analogously to GPT-3, by interleaving support example pairs in the form of (𝑖𝑚𝑎𝑔𝑒, 𝑡𝑒𝑥𝑡) or (𝑣𝑖𝑑𝑒𝑜, 𝑡𝑒𝑥𝑡), followed by the query visual input, to build a prompt.
- Open-ended evaluations are performed using beam search for decoding.
- Close-ended evaluations using model’s log-likelihood to score each possible answer.
- Zero-shot generalization is explored by prompting the model with two text-only examples from the task, with no corresponding images.
4. Results
4.1. SOTA Comparisons


Left Figure & Table: A single Flamingo model reaches the state of the art on a wide array of image (I) and video (V) understanding tasks with few-shot learning, significantly outperforming previous best zero- and few-shot methods with as few as four examples.
- More importantly, using only 32 examples and without adapting any model weights, Flamingo outperforms the current best methods — fine-tuned on thousands of annotated examples — on seven tasks.
Right Figure: The larger the model, the better the few-shot performance, similar to GPT-3. The performance also improves with the number of shots.
4.2. Fine-Tuning Flamingo

By fine-tuning the model on a short schedule with a small learning rate by additionally unfreezing the vision backbone to accommodate a higher input resolution. Results are improved over the previously presented in-context few-shot learning results, setting a new state of the art on five additional tasks: VQAv2, VATEX, VizWiz, MSRVTTQA, and HatefulMemes.
4.3. Ablation Study
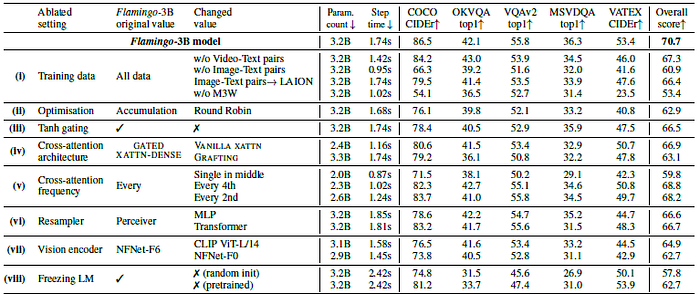
- (There are numerous ablation experimental results as shown above, there are also other results at paper appendix, please feel free to read the paper directly if interested.)
