Review — ResNeSt: Split-Attention Networks
Outperforms EfficientNet

ResNeSt: Split-Attention Networks
ResNeSt, by Facebook, UC Davis, Snap, Amazon, ByteDance, and SenseTime
2020 arXiv v2, Over 500 Citations (Sik-Ho Tsang @ Medium)
Image Classification, Residual Network, ResNet, ResNeXt, Object Detection, Semantic Segmentation, Instance Segmentation
- ResNeSt is proposed, in which a modularized architecture is designed to apply the channel-wise attention on different network branches. to leverage their success in capturing cross-feature interactions and learning diverse representations.
Outline
- ResNeSt
- Experimental Results
1. ResNeSt
1.1. ResNeSt Block


- In prior ResNeXt blocks, the feature can be divided into several groups, and the number of featuremap groups is given by a cardinality hyperparameter K.
In this ResNeSt, a new radix hyperparameter R that indicates the number of splits within a cardinal group, so the total number of feature groups is G=KR.
- (Setting radix R=2, the Split-Attention block applies SKNet-like attention to each cardinal group.)
- Thus, there is a series of transformations {F1, F2, …, FG} to each individual group, then the intermediate representation of each group is Ui=Fi(X), for i ∈{1, 2, …, G}.
- Global contextual information with embedded channel-wise statistics can be gathered with global average pooling across spatial dimensions. The c-th component is calculated as:

- This attention idea is similar to the one in SENet.
- And a weighted fusion of the cardinal group representation Vk has a size of H×W×C/K is aggregated using channel-wise soft attention, where each featuremap channel is produced using a weighted combination over splits. Then the c-th channel is calculated as:

- where aki(c) denotes a (soft) assignment weight given by:
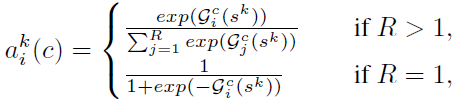
- and mapping Gci determines the weight of each split for the c-th channel based on the global context representation sk.
- The final output Y of the proposed Split-Attention block is produced using a shortcut connection: Y=V+X.
- Practically, the group transformation Fi is a 1×1 convolution followed by a 3×3 convolution.
- And the attention weight function G is parameterized using two fully connected layers with ReLU activation.
- Though the cardinality-major implementation is straightforward and intuitive, but is difficult to modularize and accelerate using standard CNN operators. A radix-major implementation of ResNeSt block is proposed as follows.
1.2. Radix-Major Implementation of ResNeSt Block
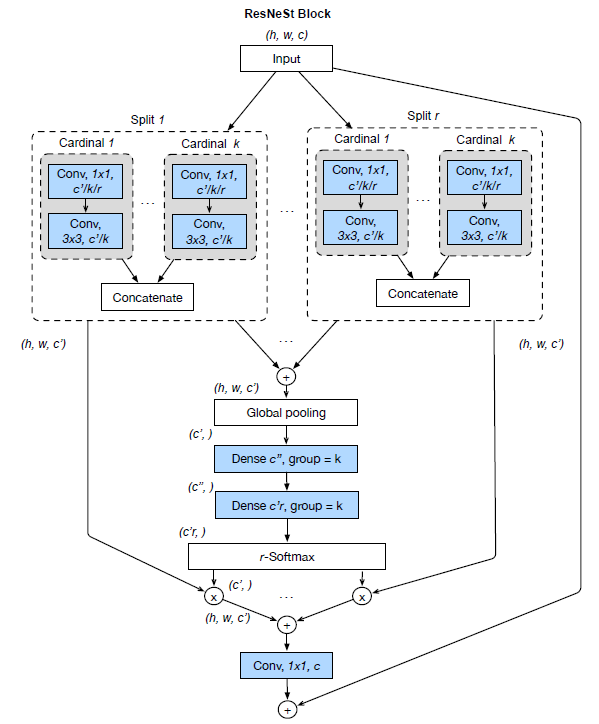
- The featuremap groups with same radix index but different cardinality are next to each other physically. A summation across different splits is conducted, so that the featuremap groups with the same cardinality-index but different radixindex are fused together.
- A global pooling layer aggregates over the spatial dimension.
- Then two consecutive fully connected (FC or dense) layers with number of groups equal to cardinality are added after pooling layer to predict the attention weights for each splits.
With this implementation, the first 1×1 convolutional layers can be unified into one layer and the 3×3 convolutional layers can be implemented using a single grouped convolution with the number of groups of RK. Therefore, the Split-Attention block is modularized using standard CNN operators.
2. Experimental Results
2.1. Image Classification

- mixup is used. AutoAugment is used.
- For example 2s2x40d denotes radix=2, cardinality=2 and width=40.
Increasing the radix from 0 to 4 continuously improves the top-1 accuracy, while also increasing latency and memory usage.
- Split-Attention with the 2s1x64d setting is used in the following experiments.
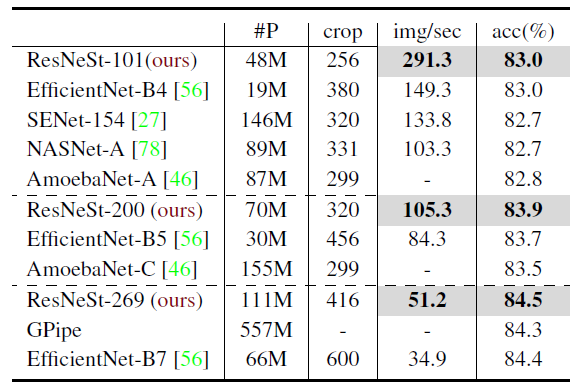
ResNeSt model displays the best tradeoff.
2.2. Object Detection
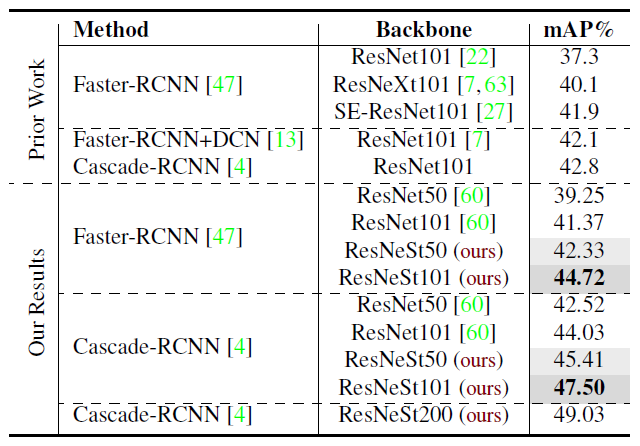
Compared to the baselines using standard ResNet, ResNeSt is able to boost mean average precision by around 3% on both Faster R-CNNs and Cascade R-CNNs.
2.3. Instance Segmentation
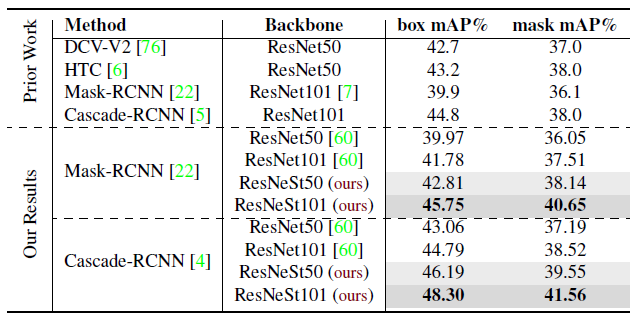
- For Mask R-CNN, ResNeSt50 outperforms the baseline with a gain of 2.85%/2.09% for box/mask performance, and ResNeSt101 exhibits even better improvement of 4.03%/3.14%.
- For Cascade R-CNN, the gains produced by switching to ResNeSt50 or ResNeSt101 are 3.13%/2.36% or 3.51%/3.04%, respectively.
2.4. Semantic Segmentation
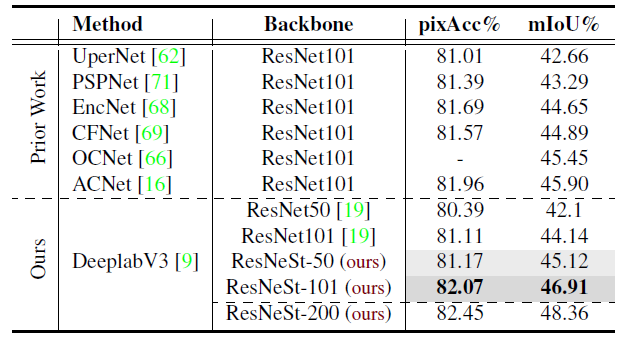
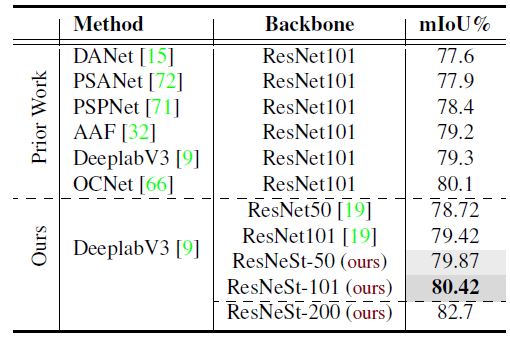
- DeepLabv3 model using ResNeSt-50 backbone already achieves better performance than DeepLabv3 with a much larger ResNet-101 backbone.
2.5. More Detailed Results in Appendix of the Paper
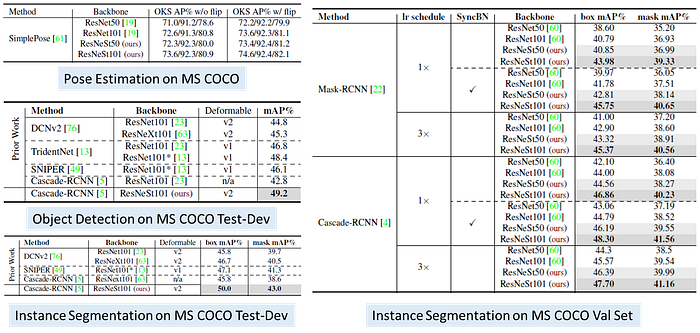
- More results are shown in appendix of the paper. Please feel free to read the paper directly.
Reference
[2020 arXiv] [ResNeSt]
ResNeSt: Split-Attention Networks
Image Classification
1989–2019 … 2020: [Random Erasing (RE)] [SAOL] [AdderNet] [FixEfficientNet] [BiT] [RandAugment] [ImageNet-ReaL] [ciFAIR] [ResNeSt]
2021: [Learned Resizer] [Vision Transformer, ViT] [ResNet Strikes Back] [DeiT] [EfficientNetV2] [MLP-Mixer] [T2T-ViT] [Swin Transformer]
