Review — Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet
T2T-ViT: ViT That Can Be Trained From Scratched

Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet, TiT-ViT, by National University of Singapore, and YITU Technology
2021 ICCV, Over 270 Citations (Sik-Ho Tsang @ Medium)
Image Classification, Vision Transformer, ViT, Transformer
- ViT trained from scratched, has inferior performance. And DeiT also needs to have teacher student training.
- A new Tokens-To-Token Vision Transformer (T2T-ViT) is proposed to progressively structurize the image to tokens by recursively aggregating neighboring Tokens into one Token (Tokens-to-Token), such that local structure represented by surrounding tokens can be modeled and tokens length can be reduced.
Outline
- Feature Visualization
- Tokens-to-Token ViT (T2T-ViT)
- Experimental Results
1. Feature Visualization

- Green boxes: highlight learned low-level structure features such as edges and lines.
- Red boxes: highlight invalid feature maps with zero or too large values.
It is found that many channels in ViT have zero value, implying the backbone of ViT is not efficient as ResNets and offers limited feature richness when training samples are not enough.
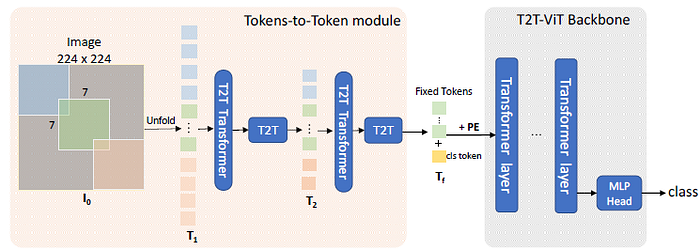
2. Tokens-to-Token ViT (T2T-ViT)

- Each T2T process has two steps: Restructurization and Soft Split (SS).
2.1. Restructurization
- Given a sequence of tokens T from the preceding Transformer layer, it will be transformed by the self-attention block:

- where MSA denotes the multihead self-attention operation with layer normalization and “MLP” is the multilayer perceptron with layer normalization in the standard Transformer.
- Then, the tokens T’ will be reshaped as an image in the spatial dimension:
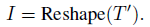
- Here “Reshape” re-organizes tokens T (l×c) to I (h×w×c), l=h×w.
2.2. Soft Split
- Soft split is applied to model local structure information and reduce length of tokens.

- Soft Split splits it into patches with overlapping, as shown above.
2.3. T2T Module
- By conducting the above Restructurization and Soft Split iteratively, the T2T module can progressively reduce the length of tokens and transform the spatial structure of the image.
- The iterative process in T2T module can be formulated as:
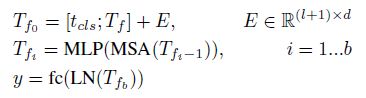
After the final iteration, the output tokens Tf of the T2T module has fixed length, so the backbone of T2T-ViT can model the global relation on Tf.
- As the length of tokens in the T2T module is larger than the normal case (16×16) in ViT, the MACs and memory usage are huge. To address the limitations, in the T2T module, the channel dimension of the T2T layer can be set to small (32 or 64) value to reduce MACs, and optionally adopt an efficient Transformer such as Performer [7] layer to reduce memory usage at limited GPU memory.
2.4. T2T-ViT Backbone
- For tokens with fixed length Tf from the last layer of T2T module, a class token is concatenated to it and then Sinusoidal Position Embedding (PE) is added to it, which is the same as ViT to do the classification:
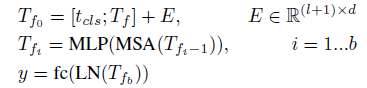
- where E is Sinusoidal Position Embedding, LN is layer normalization, fc is one fully-connected layer for classification and y is the output prediction.
2.5. T2T-ViT Architecture
- The T2T-ViT has two parts: the Tokens-to-Token (T2T) module and the T2T-ViT backbone.
- n=2 is used as shown in the above figure, which means there is n+1=3 soft split and n=2 re-structurization in T2T module.
- The patch size for the three soft splits is P = [7, 3, 3], and the overlapping is S = [3, 1, 1], which reduces size of the input image from 224×224 to 14×14.
- A deep-narrow architecture is used for T2T-ViT backbone. Specifically, it has a small channel number and a hidden dimension d but more layers b.
- Particularly, smaller hidden dimensions (256–512) and MLP size (512–1536) than ViT, are used.
- For example, T2T-ViT-14 has 14 Transformer layers in T2T-ViT backbone with 384 hidden dimensions, while ViT-B/16 has 12 Transformer layers and 768 hidden dimensions, which is 3× larger than T2T-ViT-14 in parameters and MACs.
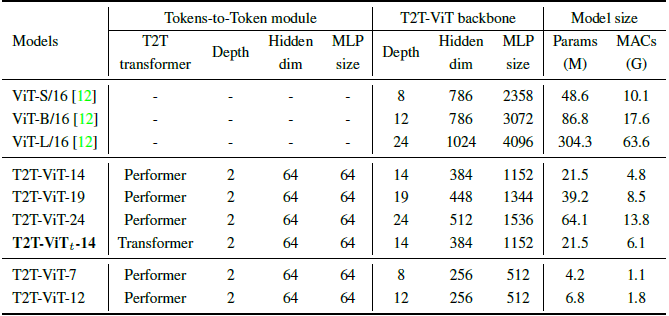
- T2T-ViT-14, T2T-ViT-19 and T2T-ViT-24 are designed of comparable parameters with ResNet50, ResNet101 and ResNet152 respectively.
- Two lite models are also designed: T2T-ViT-7, T2TViT-12 with comparable model size with MobileNetV1 and MobileNetV2.
3. Experimental Results
3.1. ImageNet

- Batch size 512 or 1024 with 8 NVIDIA GPUs are used for training. Default image size as 224×224 except for specific cases on 384×384. Some data augmentation such as Mixup and cutmix are used. 310 epochs are trained.
The small ViT model ViT-S/16 with 48.6M parameters and 10.1G MACs has 78.1% top-1 accuracy when trained from scratch on ImageNet, while T2T-ViT-14 with only 44.2% parameters and 51.5% MACs achieves more than 3.0% improvement (81.5%).
- Comparing T2T-ViT-14 with DeiT-small and DeiT-small-Distilled, T2T-ViT can achieve higher accuracy without large CNN models as teacher to enhance ViT.
- Higher image resolution are adopted as 384×384 and get 83.3% accuracy by our T2T-ViT-14↑384.

The proposed T2T-ViT achieves 1.4%-2.7% performance gain over ResNets with similar model size and MACs.
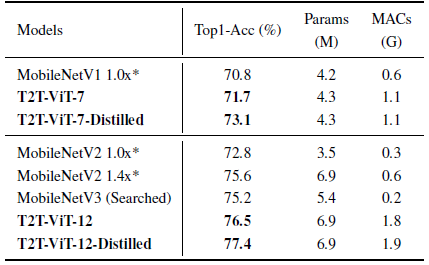
T2T-ViT-12 with 6.9M parameters achieves 76.5% top1 accuracy, which is higher than MobileNetsV2 1.4× by 0.9%. But the MACs of T2T-ViT are still larger than MobileNets.
3.2. CIFAR
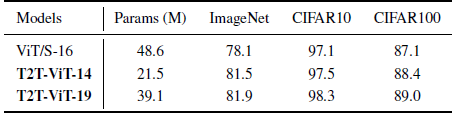
T2T-ViT can achieve higher performance than the original ViT with smaller model sizes on the downstream datasets: CIFAR10 and CIFAR100.
3.3. From CNN to ViT
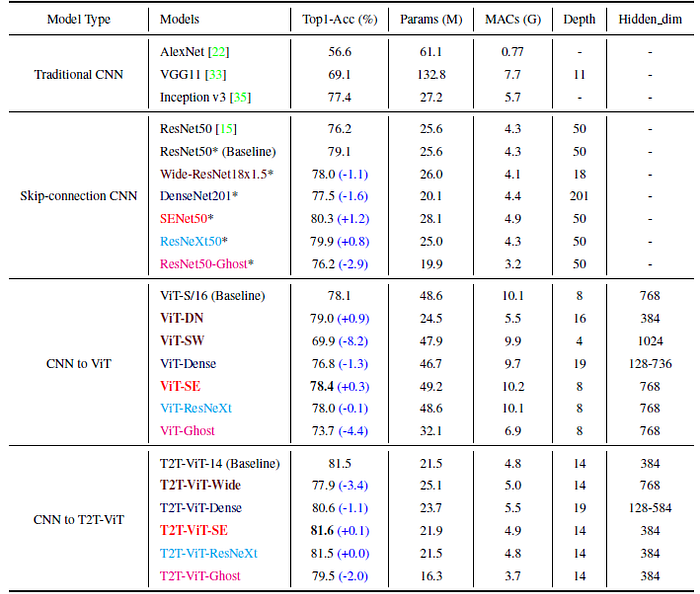
- Many SOTA approaches are applied to ViT such as dense connection in DenseNet, Wider residual structure in WRN.
It is found that both SE (ViT-SE) and Deep-Narrow structure (ViT-DN) benefit the ViT but the most effective structure is deep-narrow structure, which decreases model size and MACs nearly 2× and brings 0.9% improvement on the baseline model ViT-S/16.
Reference
[2021 ICCV] [T2T-ViT]
Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet
Image Classification
1989–2019 … 2020: [Random Erasing (RE)] [SAOL] [AdderNet] [FixEfficientNet] [BiT] [RandAugment] [ImageNet-ReaL]
2021: [Learned Resizer] [Vision Transformer, ViT] [ResNet Strikes Back] [DeiT] [EfficientNetV2] [MLP-Mixer] [T2T-ViT]