Review — What Makes Instance Discrimination Good for Transfer Learning?
Exemplar-v1 & Exemplar-v2, Supervised Contrastive Learning
What Makes Instance Discrimination Good for Transfer Learning?
Exemplar-v1, Exemplar-v2, by City University of Hong Kong, and Microsoft Research Asia
2021 ICLR, Over 70 Citations (Sik-Ho Tsang @ Medium)
Image Classification, Supervised Learning, Self-Supervised Learning, Contrastive Learning, Instance Discrimination, MoCo v2
- What makes Instance Discrimination pretraining good for transfer learning? What knowledge is actually learned and transferred from these models?
- By answering the above questions based on analysis, it is found that what truly matters for the transfer is low-level and mid-level representations, not high-level representations.
- Traditional supervised model weakens transferability when there is task misalignment.
- Finally, supervised pretraining can be strengthened by following an exemplar-based approach.
Outline
- Analysis of Visual Transfer Learning
- A Better Supervised Pretraining Method
- Experimental Results
1. Analysis of Visual Transfer Learning
1.1. Networks & Frameworks on Different Datasets
- The transfer performance of pretrained models for a set of downstream tasks is studied: object detection on PASCAL VOC07, object detection and instance segmentation on MSCOCO, and semantic segmentation on Cityscapes.
- Given a pretrained network, the network architecture is re-purposed, and all layers in the network are finetuned with synchronized batch normalization.
- For object detection on PASCAL VOC07, ResNet50-C4 in Faster R-CNN framework is used.
- For object detection and instance segmentation on MSCOCO, ResNet50-C4 in Mask R-CNN framework is used.
- For semantic segmentation on Cityscapes, DeepLabv3 is used.
- Each pretrained model is also evaluated by ImageNet classification of linear readoff on the last layer features.
1.2. Effect of Data Augmentation on Pretraining

- MoCo v2 is used for unsupervised contrastive pretraining and the traditional cross entropy loss is used for supervised pretraining with the ResNet50 architecture.
1. First, unsupervised contrastive models consistently benefit much more from image augmentations than supervised models for ImageNet classification and all the transfer tasks.
- Supervised models trained merely with horizontal flipping may perform well.
2. Second, supervised pretraining is found to also benefit from image augmentations such as color jittering and random grayscaling.
- But it is negatively affected by Gaussian blurring to a small degree.
3. Third, unsupervised models outperform the supervised counterparts on PASCAL VOC, but underperform the supervised models on COCO and Cityscapes when proper image augmentations are applied on supervised models.
- This suggests that object detection on COCO and semantic segmentation on Cityscapes may benefit more from high-level information than PASCAL VOC.
1.3. Effect of Dataset Semantics on Pretraining

- The transfer of contrastive models now pretrained on images with little or no semantic overlap with the target dataset is studied.
- These image datasets include faces, scenes, and synthetic street-view images, as shown above.
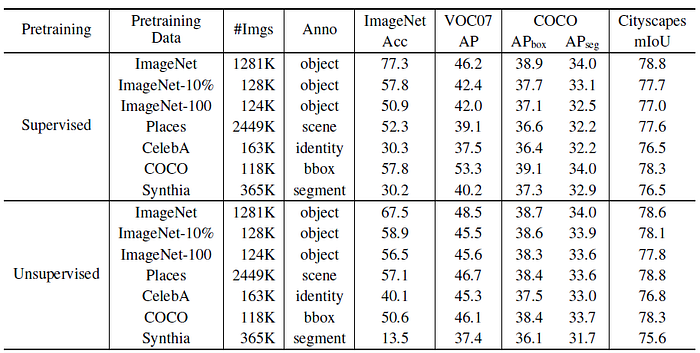
1. First, it can be seen that, except for the results on the synthetic dataset Synthia, the transfer learning performance of contrastive pretraining is relatively unaffected by the pretraining image data.
- Yet, supervised pretraining depends on the supervised semantics.
- 2. Second, all the supervised networks are negatively impacted by the change of pretraining data except when the pretraining data has the same form of supervision as the target task, such as the Synthia and the Cityscapes datasets both sharing pixel-level annotations for semantic segmentation.
3. Third, with the smaller amounts of pretraining data in ImageNet-10% and ImageNet-100, the advantage of unsupervised pretraining becomes more pronounced in relation to supervised models, which suggests stronger ability for generalization with less data for contrastive models.
- It is concluded that Instance Discrimination pretraining mainly transfers low-level and mid-level representations.
1.4. Task Misalignment and Information Loss
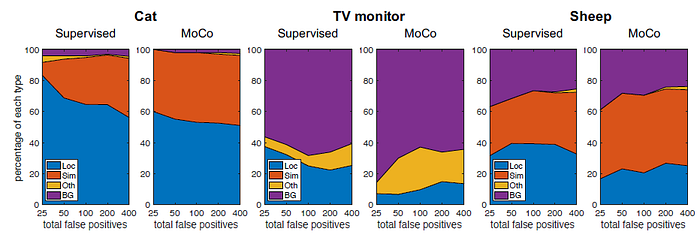
- The error distributions of the transfer results on three example categories.
- It is found that the detection errors of supervised pretraining models are more frequently the result of poor localization, where low IoU bounding boxes are mistakenly taken as true positives.

- Deep Image Prior network is used to reconstruct the image from embedding space for analysis.
- Contrastive models include InstDisc (Instance Discrimination), MoCo v2 and SimCLR are investigated.
1.4.1. Advantages of Contrastive Network
The contrastive network provides more complete reconstructions spatially. The images are reconstructed at the correct scale and location.
A possible explanation is that in order to make one instance unique from all other instances, the network strives to preserve as much information as possible.
- It is also noticed that the contrastive models find it difficult to reconstruct the hue color accurately. This is likely due to the broad space of colors and the intensive augmentations during pretraining.
1.4.2. Disadvantages of Supervised Network
The supervised network loses information over large regions in the images, likely because its features are mainly attuned to the most discriminative object parts, which are central to the classification task, rather than objects and images as a whole.
The resulting loss of information may prevent the supervised network from detecting the full envelope of the object.
2. A Better Supervised Pretraining Method
2.1. Traditional Supervised Learning
- Traditional supervised learning minimizes intra-class variation by optimizing the cross-entropy loss between predictions and labels. By doing so, it focuses on the discriminative regions within a category but at the cost of information loss in other regions.
2.2. Proposed Supervised Learning
- A better supervised pretraining method should instead pull away features of the true negatives for each instance without enforcing explicit constraints on the positives.
- This preserves the unique information of each positive instance while utilizing the label information in a weak manner.
- Concretely, the framework of momentum contrast in MoCo v2 is used as reference, where each training instance xi is augmented twice to form xqi and xki, which are fed into two encoders for embedding, qi=fq(xqi), ki=fk(xki).
- But instead of discriminating from all other instances, the loss function uses the labels yi to filter the true negatives:
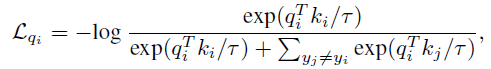
- where τ is the temperature parameter.
The baselines are MoCo v1 and MoCo v2, and their corresponding methods using the above proposed das Exemplar-v1 and Exemplar-v2.
3. Experimental Results
3.1. Downstream Tasks: VOC07, COCO & Cityscapes

- By filtering true negatives using semantic labels, the proposed method consistently improves classification performance on ImageNet and transfer performance for all downstream tasks.
- It is noted that the ImageNet classification performance of exemplar-based training, is 68.9%, which is still far from the traditional supervised learning result of 77.3%. This leaves room for future research on even better classification and transfer learning performance.
3.2. Few-Shot on Mini-ImageNet
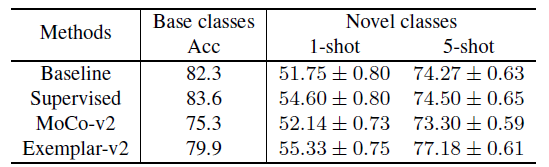
- The pretext task is image recognition on the base 64 classes, and the downstream task is image recognition on five novel classes with few labeled images per class, either 1-shot or 5-shot.
- The pretrained network learned from the base classes is fixed, and a linear classifier is finetuned for 100 rounds.
- The backbone used is ResNet-18.
- Three pretraining methods are evaluated: supervised cross entropy, unsupervised MoCo v2 and supervised Exemplar-v2.
- Due to different optimizers and number of training epochs, the supervised pretraining protocol is stronger than the baseline protocol, leading to better results.
- The unsupervised pretraining method MoCo v2 is weaker for both the base classes and the novel classes.
The exemplar-based approach obtains improvements over MoCo v2 on the base classes, while outperforming the supervised baselines on the novel classes.
3.3. Facial Landmark Prediction

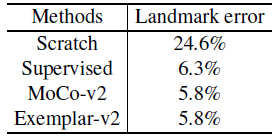
- The pretext task is face identification on CelebA, and the downstream task is to predict five facial landmarks on the MAFL dataset.
- ResNet-50 is used.
- For landmark transfer, a two-layer network is fine-tuned to map the spatial output of ResNet-50 features to landmark coordinates.
- Unsupervised pretraining by MoCo v2 outperforms the supervised counterpart for this transfer, suggesting that the task misalignment between face identification and landmark prediction is large.
The proposed exemplar-based pretraining approach weakens the influence of the pretraining semantics, leading to results that maintain the transfer performance of MoCo-v2.
The take away is that contrastive networks preserve as much information as possible, while the supervised networks focus on the most discriminative object parts rather than whole object.
(Though it is a supervised approach, it is closely related to self-supervised learning. So, I also put it into self-supervised learning category below.)
Reference
[2021 ICLR] [Exemplar-v1, Exemplar-v2]
What Makes Instance Discrimination Good for Transfer Learning?
Image Classification
1989 … 2021 [Learned Resizer] [Vision Transformer, ViT] [ResNet Strikes Back] [DeiT] [EfficientNetV2] [MLP-Mixer] [T2T-ViT] [Swin Transformer] [CaiT] [ResMLP] [ResNet-RS] [NFNet] [PVT, PVTv1] [CvT] [HaloNet] [TNT] [CoAtNet] [Focal Transformer] [TResNet] [CPVT] [Twins] [Exemplar-v1, Exemplar-v2] 2022 [ConvNeXt] [PVTv2]
Self-Supervised Learning
1993 … 2020 [CMC] [MoCo] [CPCv2] [PIRL] [SimCLR] [MoCo v2] [iGPT] [BoWNet] [BYOL] [SimCLRv2] 2021 [MoCo v3] [SimSiam] [DINO] [Exemplar-v1, Exemplar-v2]
