Brief Review — OpenCLIP: Reproducible scaling laws for contrastive language-image learning
OpenCLIP, Open-Sourced CLIP With Scaling Law Study
3 min readMar 19, 2024

Reproducible scaling laws for contrastive language-image learning
OpenCLIP, by LAION; UC Berkeley; HuggingFace; University of Washington; Research Center Juelich (FZJ)
2023 CVPR, Over 190 Citations (Sik-Ho Tsang @ Medium)Visual/Vision/Video Language Model (VLM)
2017 … 2022 [FILIP] [Wukong] [LiT] [Flamingo] [FLAVA] [SimVLM] [VLMo] [BEiT-3] [GLIP] 2023 [GPT-4] [GPT-4V(ision)] [MultiModal-CoT] [CoCa]
==== My Other Paper Readings Are Also Over Here ====
- Similar to scaling law investigated in LLM by Gopher, in this paper, scaling laws for OpenAI contrastive language-image pre-training (CLIP) are investigated with the public LAION dataset and it is open-sourced.
Outline
- LAION-400M/2B Dataset & OpenCLIP
- Results
1. LAION-400M/2B Dataset & OpenCLIP

With both data and model scaling, OpenCLIP outperforms CLIP.
1.1. LAION Dataset
- LAION-400M [66] and LAION-5B [65] datasets are used, which are open, public image-text datasets.
- LAION-5B contains an English image-text subset of 2.32 billion samples, which is referred in this paper as LAION-2B in this work.
- LAION-80M, which is the subset of LAION-400M, is also used.
1.2. OpenCLIP Training
- CLIP is trained with different sizes of Transformer & ViT.
- Global batch sizes are in the range of 86–88K samples.
- InfoNCE loss is used.
- Same as OpenAI CLIP, given a dataset {(xi, yi)}ni =1, each image is classified as the class that has the largest cosine similarity with the (L2-normalized) image embedding.
2. OpenCLIP

2.1. Zero-Shot Transfer and Robustness
Figure 1a: Accuracy follows power laws, such that larger models benefit from larger data and samples seen scale.
- The strongest ImageNet accuracy (78%) is obtained with the largest total pre-training compute, using ViT-H/14 pre-trained on LAION-2B data scale and 34B samples seen.
- Fitting power-law (E=βC^α) on the Pareto frontier of the available models, we measure scaling coefficients αopenCLIP = -0.11 and αCLIP = -0.16 for zero-shot top-1 ImageNet and αopenCLIP = -0.13 and αCLIP = -0.24 for ImageNet robustness datasets performance.
2.2. Retrieval
(Figure 1b): Again it is observed that performance consistently improves when increasing scale following power law trends.
2.3. Others
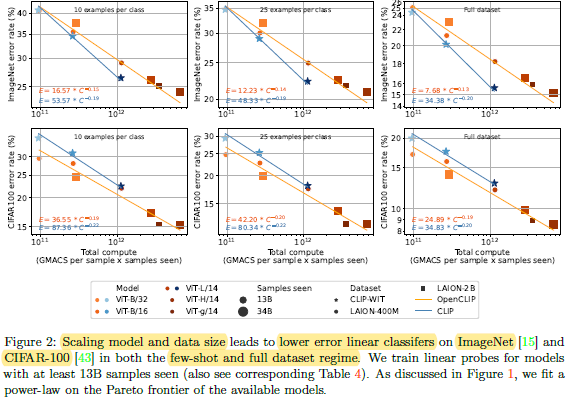
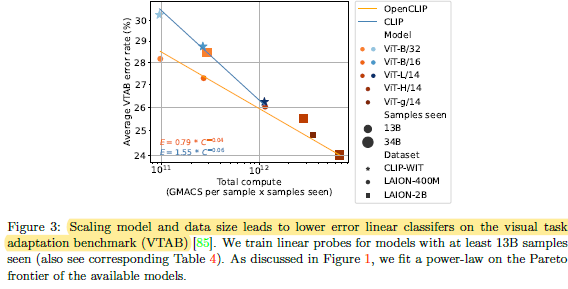
- Similar observations for other tasks/datasets.
