Review: Character-Aware Neural Language Models
Character-Level Language Model Using CNN and Highway

In this story, Character-Aware Neural Language Models, (LSTM-Char-CNN), by Harvard University, and New York University, is reviewed. In this paper:
- Instead of word-level language model, a CNN and a highway network are used over characters, whose output is given to a LSTM recurrent neural network language model (RNN-LM).
- 60% fewer parameters is achieved.
This is a paper in 2016 AAAI with over 1700 citations. (Sik-Ho Tsang @ Medium)
Outline
- Notations Related to Language Model
- Proposed Model Architecture
- Experimental Results
1. Notations Related to Language Model
- (I think this paper gives a very clear notations related to language model.)
- Let V be the fixed size vocabulary of words.
A language model specifies a distribution over wt+1 (whose support is V) given the historical sequence w1:t = [w1, …, wt].
1.1. Output
- A recurrent neural network language model (RNN-LM) is used by applying an affine transformation to the hidden layer (ht) followed by a softmax:

- where pj is the j-th column of P, which is referred to as the output embedding.
1.2. Input
- For a conventional RNN-LM which usually takes words as inputs, if wt=k, then the input to the RNN-LM at t is the input embedding xk, the k-th column of the embedding matrix X.
1.3. Negative Log-Likelihood (NLL)
- If we denote w1:T = [w1, …, wT] to be the sequence of words in the training corpus, training involves minimizing the negative log-likelihood (NLL) of the sequence:

1.4. Perplexity (PPL)
- Perplexity (PPL) is used to evaluate the performance of our models. Perplexity of a model over a sequence [w1, …, wT] is given by:

The proposed model here simply replaces the input embeddings X with the output from a character-level CNN, to be described below.
2. Proposed Model Architecture

2.1. Input & CharCNN
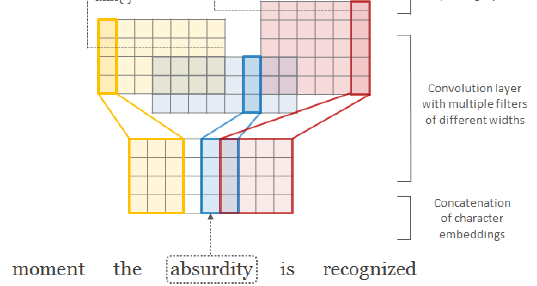
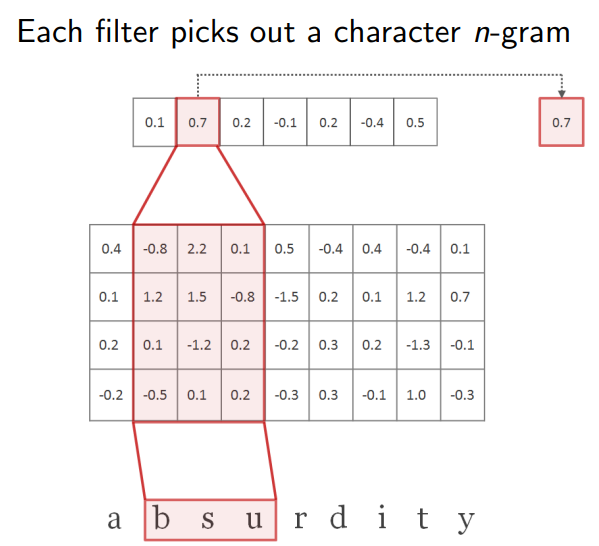
- The input at time t is an output from a character-level convolutional neural network (CharCNN).
- Let C be the vocabulary of characters, d be the dimensionality of character embeddings.
- Suppose that word k is made up of a sequence of characters [c1, …, cl], where l is the length of word k. Then the character-level representation of k is given by the matrix Ck.
- CharCNN:

- where <Ck, H> is the convolution with kernel H.
- Then a bias is added and a nonlinearity tanh is applied to obtain a feature map fk.
- CharCNN uses multiple filters of varying widths to obtain the feature vector for k..
2.2. Max Over Time
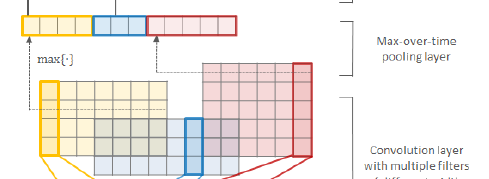
- Finally, the max-over-time is used:
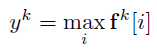
- This is the feature corresponding to the filter H (when applied to word k). The idea is to capture the most important feature, which is the one with the highest value for a given filter.
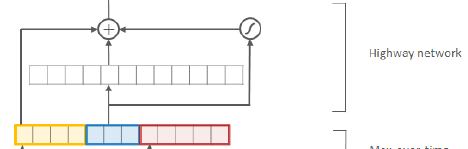
2.3. Highway
- In convention, one layer of an MLP can be applied:
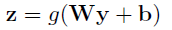
- where g is a nonlinearity.
- In this paper, one layer of highway network is used:
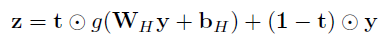
- where t is:
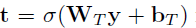
- where t is transform gate, and (1-t) is carry gate.
Similar to the memory cells in LSTM networks, highway layers allow for training of deep networks by adaptively carrying some dimensions of the input directly to the output.
- (Please read Highway if interested.)
2.5. LSTM
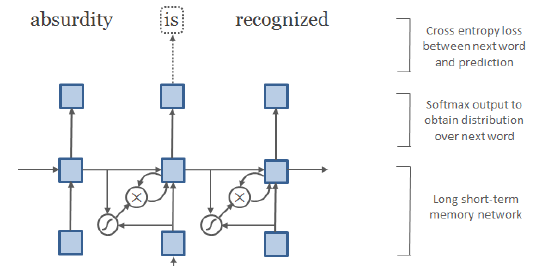
- Finally, LSTM is used with z as input, and output the next word.
2.4. Two Networks (LSTM-Char-Small and LSTM-Char-Large)
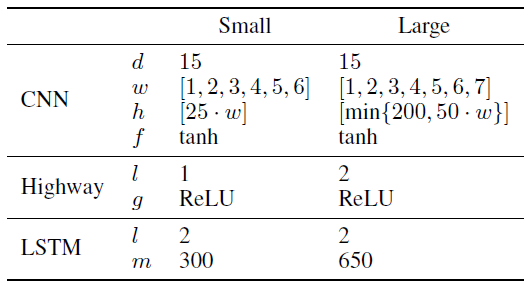
- One small model and one large model are designed, which are called LSTM-Char-Small and LSTM-Char-Large models respectively.
- d = dimensionality of character embeddings; w = filter widths;
- h = number of filter matrices, as a function of filter width (so the large model has filters of width [1; 2; 3; 4; 5; 6; 7] of size [50; 100; 150; 200; 200; 200; 200] for a total of 1100 filters);
- f; g = nonlinearity functions; l = number of layers; m = number of hidden units.
- Two datasets are used for training. Small one is DATA-L, big one is DATA-S.
- Hierarchical Softmax is used for DATA-L, which is a common strategy for large dataset:
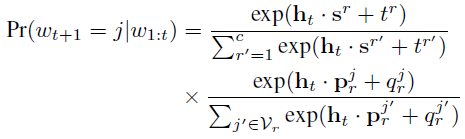
- where V is randomly split into mutually exclusive and collectively exhaustive subsets V1, …, Vc. r is the cluster index.
- The first term is simply the probability of picking cluster r, and the second term is the probability of picking word j given that cluster r is picked.
3. Experimental Results
3.1. English Penn Treebank

The proposed large model is on par with the existing state-of-the-art (Zaremba et al. 2014), despite having approximately 60% fewer parameters.
- The proposed small model significantly outperforms other NLMs of similar size.
3.2. Other Languages
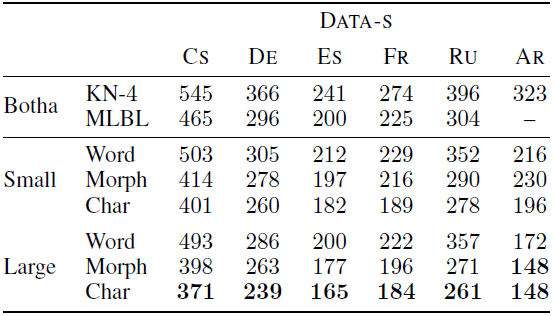
The character-level models outperform their word-level counterparts.
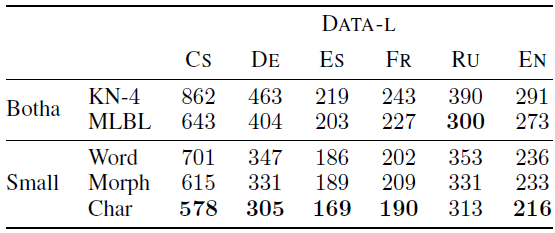
- Due to memory constraints, only the small models on DATA-L are trained.
- Interestingly, no significant differences are observed going from word to morpheme LSTMs on Spanish, French, and English.
The character models again outperform the word/morpheme models.
- (Please feel free to read paper if interested in the ablation studies.)
References
[2016 AAAI] [LSTM-Char-CNN]
Character-Aware Neural Language Models
Their Slides: https://people.csail.mit.edu/dsontag/papers/kim_etal_AAAI16_slides.pdf
Natural Language Processing (NLP)
Language/Sequence Model: 2007 [Bengio TNN’07] 2013 [Word2Vec] [NCE] [Negative Sampling] 2014 [GloVe] [GRU] [Doc2Vec] 2015 [Skip-Thought] 2016 [GCNN/GLU] [context2vec] [Jozefowicz arXiv’16] [LSTM-Char-CNN] 2017 [TagLM]
Machine Translation: 2014 [Seq2Seq] [RNN Encoder-Decoder] 2015 [Attention Decoder/RNNSearch] 2016 [GNMT] [ByteNet] [Deep-ED & Deep-Att] 2017 [ConvS2S] [Transformer]
Image Captioning: 2015 [m-RNN] [R-CNN+BRNN] [Show and Tell/NIC] [Show, Attend and Tell]
