Review — CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows
CSWin Transformer, Cross-Shaped Window for Self Attention
CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows,
CSWin Transformer, by University of Science and Technology of China, Microsoft Research Asia, and Microsoft Cloud + AI
2022 CVPR, Over 180 Citations (Sik-Ho Tsang @ Medium)
Image Classification, Vision Transformer, ViT, Transformer
- Cross-Shaped Window (CSWin) self-attention mechanism is proposed for computing self-attention in the horizontal and vertical stripes in parallel that form a cross-shaped window.
- Locally-enhanced Positional Encoding (LePE) is proposed, which handles the local positional information better than existing encoding schemes.
Outline
- CSWin Transformer
- Locally-enhanced Positional Encoding (LePE)
- Model Variants
- Experimental Results
- Ablation Study
1. CSWin Transformer
1.1. Framework

- For an input image with size of H×W×3, authors follow CvT and leverage the overlapped convolutional token embedding (7 × 7 convolution layer with stride 4) to obtain H/4×W/4 patch tokens, and the dimension of each token is C.
- To produce a hierarchical representation, the whole network consists of four stages. A convolution layer (3 × 3, stride 2) is used between two adjacent stages to reduce the number of tokens and double the channel dimension.
- Each stage consists of Ni sequential CSWin Transformer Blocks and maintains the number of tokens. CSWin Transformer Block has the overall similar topology as the vanilla multi-head self-attention Transformer block with two differences:
- It replaces the self-attention mechanism with the proposed Cross-Shaped Window Self-Attention.
- In order to introduce the local inductive bias, LePE is added as a parallel module to the self-attention branch.
1.2. Cross-Shaped Window (CSWin) Self-Attention

- To alleviate this issue, existing works suggest to perform self-attention in a local attention window and apply halo or shifted window to enlarge the receptive filed. However, there is only limited attention area. This requires stacking more blocks to achieve global receptive field.
- Figure Left: The input feature X is first linearly projected to K heads, and then each head will perform local self-attention within either the horizontal or vertical stripes.
- For horizontal stripes self-attention, X is evenly partitioned into non-overlapping horizontal stripes [X1, .., XM] of equal width sw, and each of them contains sw×W tokens.

- where M=H/sw, dimension dk=C/K.
- The vertical stripes self-attention can be similarly derived, and its output for k-th head is denoted as V-Attentionk(X).
- Assuming natural images do not have directional bias, the K heads are equally split into two parallel groups (each has K/2 heads).
- The first group of heads perform horizontal stripes self-attention while the second group of heads perform vertical stripes self-attention.
- Finally the output of these two parallel groups will be concatenated back together:
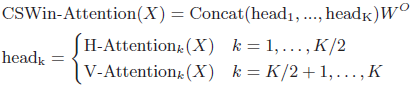
Therefore, the attention area of each token within one Transformer block is enlarged via multi-head grouping.
1.3. Computational Complexity
- The computation complexity of CSWin self-attention is:
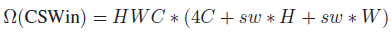
- For high-resolution inputs, considering H, W will be larger than C in the early stages and smaller than C in the later stages. Small sw is chosen for early stages and larger sw is chosen for later stages.
- sw is set to 1, 2, 7, 7 for four stages by default.
In other words, adjusting sw provides the flexibility to enlarge the attention area of each token in later stages in an efficient way.
2. Locally-enhanced Positional Encoding (LePE)

- The self-attention computation could be formulated as:
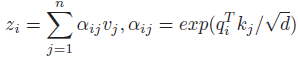
- where the input sequence as x=(x1, …, xn) of n elements, and the output of the attention z=(z1, …, zn) of the same length.
- Then the proposed Locally-Enhanced position encoding performs as a learnable per-element bias:
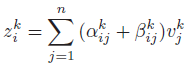
- To make the LePE suitable to varying input size, a distance threshold is set to the LePE and set it to 0 if the Chebyshev distance of token i and j is greater than a threshold τ (τ=3 in the default setting).
3. Model Variants
- Finally, CSWin Transformer Block becomes:

- 4 variants are defined:
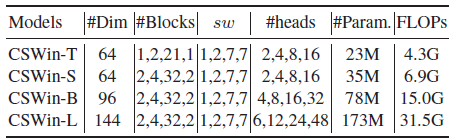
4. Experimental Results
4.1. ImageNet

CSWin Transformers outperform previous state-of-the-art Vision Transformers by large margins.
- For example, CSWin-T achieves 82.7% Top-1 accuracy with only 4.3G FLOPs, surpassing CvT-13, Swin-T and DeiT-S by 1.1%, 1.4% and 2.9% respectively.
- And for the small and base model setting, our CSWin-S and CSWin-B also achieve the best performance.
- When finetuned on the 384×384 input, a similar trend is observed.

- When pre-training CSWin Transformer on ImageNet-21K dataset, for CSWin-B, the large-scale data of ImageNet-21K brings a 1.6%∼1.7% gain. CSWin-B and CSWin-L achieve 87.0% and 87.5% top-1 accuracy, surpassing previous methods.
4.2. COCO

CSWin Transformer variants clearly outperforms all the CNN and Transformer counterparts.
- CSWin-T outperforms Swin-T by +4.5 box AP, +3.1 mask AP with the 1× schedule and +3.0 box AP, +2.0 mask AP with the 3× schedule respectively.
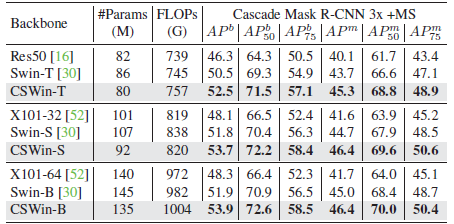
- When using Cascade Mask R-CNN, CSWin Transformers still surpass the counterparts by promising margins under different model configurations.
4.3. ADE20K
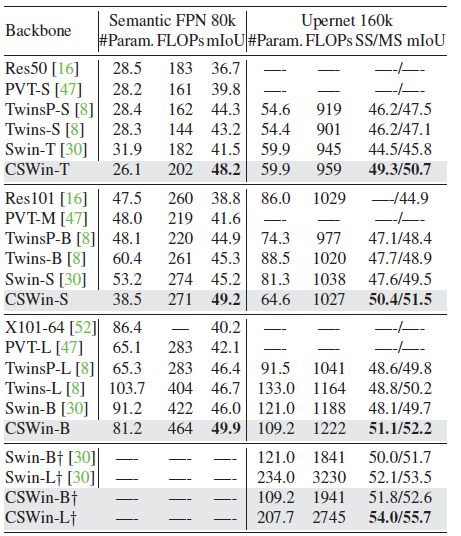
CSWin Transformers significantly outperform previous state-of-the-arts under different configurations.
- CSWin-T, CSWin-S, CSWin-B achieve +6.7, +4.0, +3.9 higher mIOU than the Swin counterparts with the Semantic FPN framework, and +4.8, +2.8, +3.0 higher mIOU with the UPerNet framework.
- When using the ImageNet-21K pretrained model, CSWin-L further achieves 55.7 mIoU and surpasses the previous best model by +2.2 mIoU, while using less computation complexity.
4.4. Inference Speed
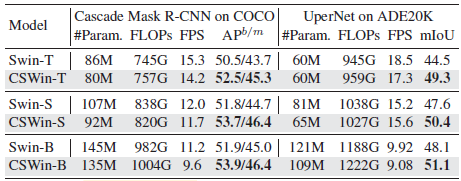
5. Ablation Study

CSWin (sw=1,2,7,7) obtains the highest accuracy/AP/mIoU.
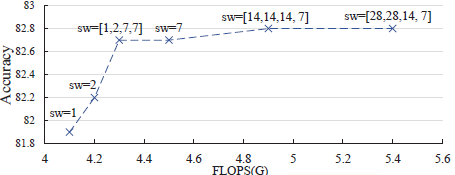
The default setting [1,2,7,7] achieves a good trade-off between accuracy and FLOPs.
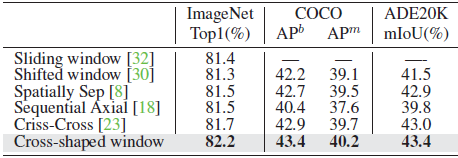
CSWin self-attention mechanism performs better than existing self-attention mechanisms across all the tasks.
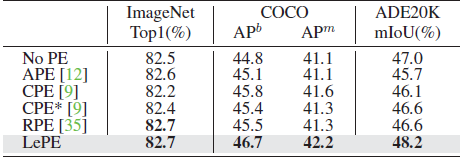
Though RPE achieves similar performance on the classification task with fixed input resolution, the proposed LePE performs better (+1.2 box AP and +0.9 mask AP on COCO, +0.9 mIoU on ADE20K) on downstream tasks.
Reference
[2022 CVPR] [CSWin Transformer]
CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows
1.1. Image Classification
1989 … 2022 [ConvNeXt] [PVTv2] [ViT-G] [AS-MLP] [ResTv2] [CSWin Transformer]
