Review — Learned in Translation: Contextualized Word Vectors (CoVe)
Extract the Word Vectors from Encoder Learned in Machine Translation

In this paper, Learned in Translation: Contextualized Word Vectors, (CoVe) by SalesForce, is reviewed. Conventionally, word vectors are obtained by sentence/word prediction task using unsupervised learning. In this paper:
- A deep LSTM encoder from an attentional sequence-to-sequence model trained for machine translation (MT) is used to contextualize word vectors (CoVe).
- The trained encoder outputs CoVe for other tasks.
This is a paper in 2017 NeurIPS with over 800 citations. (Sik-Ho Tsang @ Medium)
Outline
- MT-LSTM
- Context Vectors (CoVe)
- Experimental Results
1. MT-LSTM
- An attentional sequence-to-sequence model for English-to-German translation is trained.
- Given a sequence of words in the source language wx = [wx1, …, wxn] and a sequence of words in the target language wz = [wz1, …, wzm].
- Let GloVe(wx) be a sequence of GloVe vectors.
- GloVe(wx) is fed to a standard, two-layer, bidirectional, long short-term memory network (MT-LSTM).
- The MT-LSTM is used to compute a sequence of hidden states:

- An attentional decoder is used. the decoder first uses a two-layer, unidirectional LSTM to produce a hidden state hdect based on the previous target embedding zt-1 and a context-adjusted hidden state ~ht-1:

- The decoder then computes a vector of attention weights α representing the relevance of each encoding time-step to the current decoder state:

- where H refers to the elements of h stacked along the time dimension.
- The decoder then uses these weights as coefficients in an attentional sum that is concatenated with the decoder state and passed through a tanh layer to form the context-adjusted hidden state ~h:

- Finally, softmax is used:

2. Context Vectors (CoVe)
- What is learned by the MT-LSTM is transferred to downstream tasks by treating the outputs of the MT-LSTM as context vectors:

- For classification and question answering, for an input sequence w, each vector in GloVe(w) is concatenated with its corresponding vector in CoVe(w):

2.1. Classification with CoVe

- A biattentive classification network (BCN) is designed to handle both single-sentence and two-sentence classification tasks.
- In the case of single-sentence tasks, the input sequence is duplicated to form two sequences.
- Input sequences wx and wy are converted to sequences of vectors, ~wx and ~wy, as described in the previous section before being fed to the task-specific portion of the model as in the above figure.
2.1.1. ReLU Network & Encoder
- A function f applies a feedforward ReLU network and bidirectional LSTM (Encoder) are used to process ~wx and ~wy:
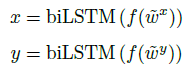
- These sequences are each stacked along the time axis to get matrices X and Y.
2.1.2. Biattention
- The biattention first computes an affinity matrix A. It then extracts attention weights with column-wise normalization:
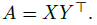

- Next, it uses context summaries:
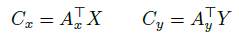
- to condition each sequence on the other.
2.1.3. Integrate
- The conditioning information are integrated into the representations for each sequence with two separate one-layer, bidirectional LSTMs that operate on the concatenation of the original representations (to ensure no information is lost in conditioning), their differences from the context summaries (to explicitly capture the difference from the original signals), and the element-wise products between originals and context summaries (to amplify or dampen the original signals):
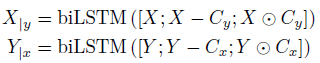
2.1.4. Pool
- The outputs of the bidirectional LSTMs are aggregated by pooling along the time dimension.
- The self-attentive pooling computes weights for each time step of the sequence:

- These weights are used to get weighted summations of each sequence:
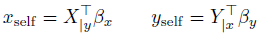
- The pooled representations are combined to get one joined representation for all inputs:
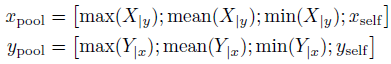
- Finally, this joined representation goes through a three-layer, batch-normalized maxout network [Goodfellow et al., 2013] to produce a probability distribution over possible classes.
2.2. Question Answering with CoVe
- Similar to classification with CoVe, but f is replaced with g that uses a tanh activation instead of a ReLU activation. In this case, one of the sequences is the document and the other the question in the question-document pair.
- These sequences are then fed through the coattention and dynamic decoder implemented as in the original Dynamic Coattention Network (DCN) [Dynamic coattention networks for question answering in 2017 ICRL]
- (Dynamic Coattention Network is not detailed in the paper, thus I also don’t mention it in details here.)
3. Experimental Results
3.1. Datasets & Results for Pretext Task
- 3 different English-German machine translation datasets to train 3 separate MT-LSTMs.
- MT-Small: The smallest MT dataset comes from the WMT 2016 multi-modal translation shared task. The training set consists of 30,000 sentence pairs that briefly describe Flickr captions and is often referred to as Multi30k.
- MT-Medium: The medium-sized MT dataset is the 2016 version of the machine translation task prepared for the International Workshop on Spoken Language Translation. The training set consists of 209,772 sentence pairs from transcribed TED presentations.
- MT-Large: The largest MT dataset comes from the news translation shared task from WMT 2017. The training set consists of roughly 7 million sentence pairs that comes from web crawl data, a news and commentary corpus, European Parliament proceedings, and European Union press releases.
- The corresponding context vectors from trained encoders are named CoVe-S, CoVe-M, and CoVe-L.
The MT-LSTM trained on MT-Small obtains an uncased, tokenized BLEU score of 38.5 on the Multi30k test set from 2016.
The model trained on MT-Medium obtains an uncased, tokenized BLEU score of 25.54 on the IWSLT test set from 2014.
The MT-LSTM trained on MT-Large obtains an uncased, tokenized BLEU score of 28.96 on the WMT 2016 test set. These results represent strong baseline machine translation models
3.2. Downstream Tasks
3.2.1. Datasets
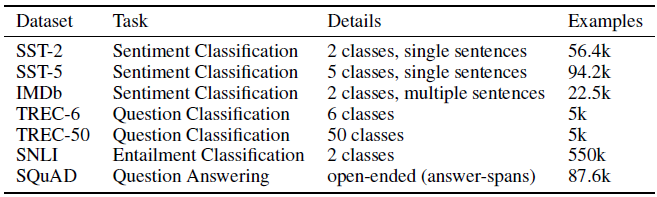
- Sentiment Analysis: The Stanford Sentiment Treebank (SST) and the IMDb dataset. Both of these datasets comprise movie reviews and their sentiment. SST-2 contains roughly 56,400 reviews after removing “neutral” examples. SST-5 contains roughly 94,200 reviews and does include “neutral” examples. IMDb contains 25,000 multi-sentence reviews.
- Question Classification: Small TREC dataset of open-domain, fact-based questions divided into broad semantic categories. The six-class and fifty-class versions of TREC, are referred to as TREC-6 and TREC-50.
- Entailment: Stanford Natural Language Inference Corpus (SNLI) is used, which has 550,152 training, 10,000 validation, and 10,000 testing examples. Each example consists of a premise, a hypothesis, and a label specifying whether the premise entails, contradicts, or is neutral.
- Question Answering: The Stanford Question Answering Dataset (SQuAD) is a large-scale question answering dataset based on Wikipedia with 87,599 training examples, 10,570 development examples, and a test set that is not released to the public. SQuAD examples assume that the question is answerable and that the answer is contained verbatim somewhere in the paragraph.
3.2.2. Results
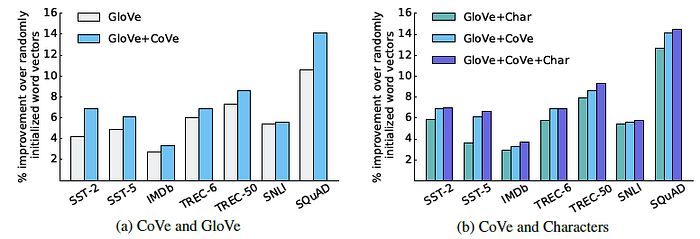
The models that use CoVe alongside GloVe achieve higher validation performance than models that use only GloVe.
- Additionally appending character n-gram embeddings can boost performance even further for some tasks.
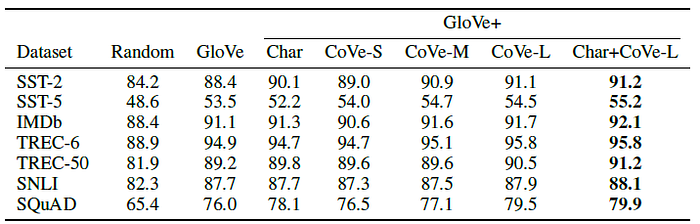
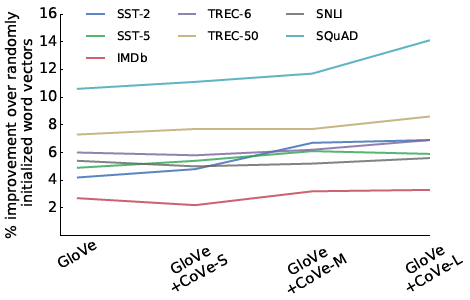
- There appears to be a positive correlation between the larger MT datasets, which contain more complex, varied language.
MT data has potential as a large resource for transfer learning in NLP.
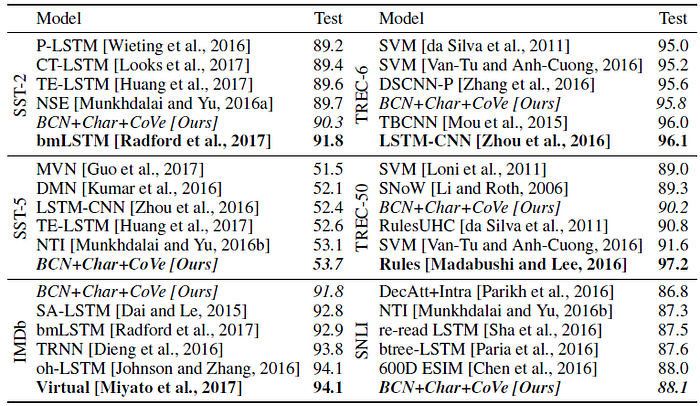
Final test performances on SST-5 and SNLI reached a new state of the art.
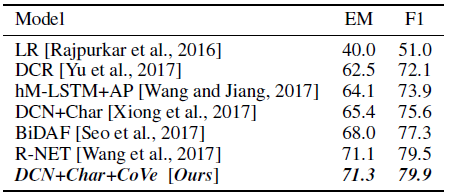
Using CoVe achieves higher validation exact match and F1 scores for single model question answering.
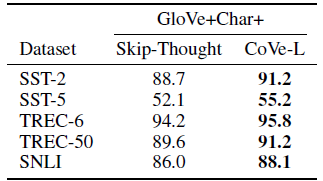
- Skip-Thought encoders are trained with an unsupervised method.
- The 4800 dimensional Skip-Thought vectors make training more unstable than using the 600 dimensional CoVe.
The above table shows that these differences make CoVe more suitable for transfer learning in our classification experiments.
Reference
[2017 NeurIPS] [CoVe]
Learned in Translation: Contextualized Word Vectors
Natural Language Processing (NLP)
Language/Sequence Model: 2007 [Bengio TNN’07] 2013 [Word2Vec] [NCE] [Negative Sampling] 2014 [GloVe] [GRU] [Doc2Vec] 2015 [Skip-Thought] 2016 [GCNN/GLU] [context2vec] [Jozefowicz arXiv’16] [LSTM-Char-CNN] 2017 [TagLM] [CoVe]
Machine Translation: 2014 [Seq2Seq] [RNN Encoder-Decoder] 2015 [Attention Decoder/RNNSearch] 2016 [GNMT] [ByteNet] [Deep-ED & Deep-Att] 2017 [ConvS2S] [Transformer]
Image Captioning: 2015 [m-RNN] [R-CNN+BRNN] [Show and Tell/NIC] [Show, Attend and Tell]
