Review — Pale Transformer: A General Vision Transformer Backbone with Pale-Shaped Attention
Pale Shape Window for Self Attention
Pale Transformer: A General Vision Transformer Backbone with Pale-Shaped Attention,
Pale Transformer, by Baidu Research, National Engineering Laboratory for Deep Learning Technology and Application, and University of Chinese Academy of Sciences, 2022 AAAI (Sik-Ho Tsang @ Medium)
Image Classification, Vision Transformer, ViT, Transformer
- Conventional global self-attention increases memory quadratically while some of the works suggest to constraint the self-attention window to be localized, which makes the receptive field small.
- In this paper, a Pale-Shaped self-Attention (PS-Attention), which performs self-attention within a pale-shaped region. Pale Transformer is formed to solve the above problem.
Outline
- Pale-Shaped Self-Attention
- Pale Transformer
- Experimental Results
- Ablation Studies
1. Pale-Shaped Self-Attention

1.1. Prior Arts
- (a) Conventional global self-attention: used in ViT.
- (b) Shifted window self-attention: used in Swin Transformer. Shuffled window self-attention: used in Shuffle Transformer. Messenger used in MSG-Transformer.
- (c) Axial self-attention: used in Axial DeepLab.
- (d) Cross-shaped window self-attention: used in CSWin Transformer.
1.2. Pale-Shaped Self-Attention (PS-Attention)
- (e) Proposed pale-shaped self-attention: computes self-attention within a pale-shaped region (abbreviating as pale).
- One pale contains sr interlaced rows and sc interlaced columns, which covers a region containing (sr×w+sc×h-sr×sc) tokens.
- The number of pales is equal to N=h/sr=w/sc.
The receptive field of PS-Attention is significantly wider and richer than all the previous local self-attention mechanisms, enabling more powerful context modeling capacity.
1.3. Efficient Parallel Implementation

- The input feature X of size h×w×c is divided into two independent parts Xr and Xc of size both with h×w×c/2.

- Then, the self-attention is conducted within each row-wise and column-wise token group, respectively.
- Following CvT, three separable convolution layers ΦQ, ΦK, and ΦV are used to generate the query, key, and value:

- where MSA indicates the Multi-head Self-Attention.
- Finally, the outputs of row-wise and column-wise attention are concatenated along channel dimension, resulting in the final output Y of size h×w×c:

- Compared to the vanilla implementation of PS-Attention within the whole pale, such a parallel mechanism has a lower computation complexity.
- The standard global self-attention has a computational complexity of:
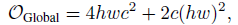
- The proposed PS-Attention under the parallel implementation has a computational complexity of:
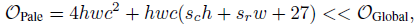
1.4. Pale Transformer Block
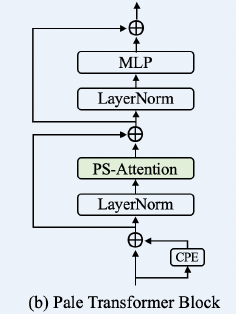
- Pale Transformer block consists of three sequential parts, the conditional position encoding (CPE), as in CPVT, for dynamically generating the positional embedding, the proposed PS-Attention module for capturing contextual information, and the MLP module for feature projection.
- The forward pass of the l-th block can be formulated as follows:

- where LN() refers to layer normalization, and the CPE (CPVT) is implemented as a simple depth-wise convolution.
2. Pale Transformer
2.1. Overall Architecture
- The Pale Transformer consists of four hierarchical stages. Each stage contains a patch merging layer and multiple Pale Transformer blocks.
- The patch merging layer aims to spatially downsample the input features by a certain ratio and expand the channel dimension by twice for a better representation capacity.
- For fair comparisons, the overlapping convolution for patch merging is used, which is the same as CvT.
2.2. Model Variants
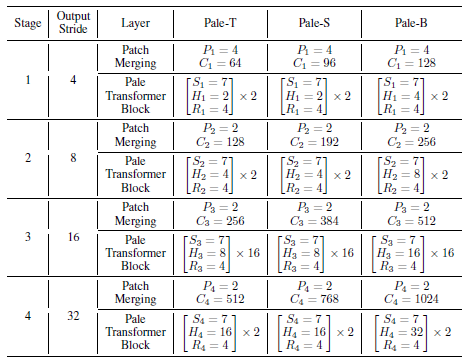

- Three variants of our Pale Transformer, named Pale-T (Tiny), Pale-S (Small), and Pale-B (Base), respectively.
- All variants have the same depth with [2, 2, 16, 2] in four stages.
- In each stage of these variants, the pale size is set as sr=sc=Si=7, and the same MLP expansion ratio of Ri=4 is used.
- Thus, the main differences among Pale-T, Pale-S, and Pale-B lie in the embedding dimension of tokens and the head number for the PS-Attention in four stages, i.e., variants vary from narrow to wide.
3. Experimental Results
3.1. ImageNet-1K

- All the variants are trained from scratch for 300 epochs on 8 V100 GPUs with a total batch size of 1024.
Compared to the advanced CNNs, the Pale variants are +3.4%, +2.6%, and +2.0% better than the well-known RegNet models.
Pale Transformer outperforms the state-of-the-art Transformer-based backbones, and is +0.7% higher than the most related CSWin Transformer for all variants under the similar model size and FLOPs.
- *: indicates employing MixToken and token labeling loss during training.
Pale-T* achieves +0.9% gain than LV-ViT-S* with fewer computation costs. Pale-S* and Pale-B* achieve 85.0% and 85.8%, outperforming VOLO by +0.8% and +0.6%, respectively.
3.2. ADE20K
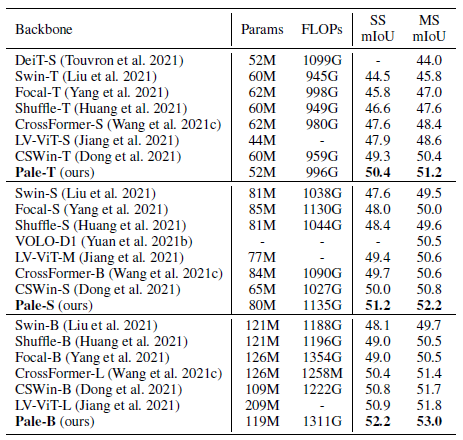
- UPerNet is used as decoder. SS: Single-Scale, MS: Multi-Scale.
Pale-T and Pale-S outperform the state-of-the-art CSWin by +1.1% and +1.2% SS mIoU, respectively. Besides, Pale-B achieves 52.5%/53.0% SS/MS mIoU, surpassing the previous best by +1.3% and +1.2%, respectively.
3.3. COCO
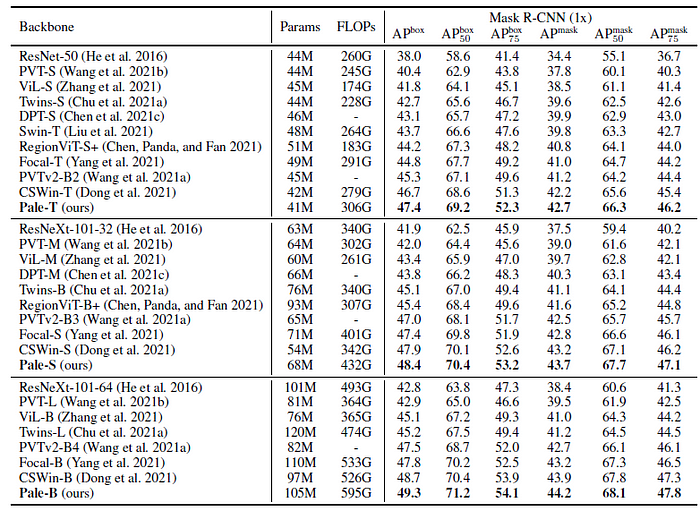
- Mask R-CNN framework is used.
Pale-T, Pale-S, and Pale-B achieve 47.4, 48.4, and 49.2 box mAP for object detection, surpassing the previous best CSWin Transformer by +0.7, +0.5, and +0.6, respectively.
- Besides, the proposed variants also have consistent improvement on instance segmentation, which are +0.5, +0.5, and +0.3 mask mAP higher than the previous best backbone.
4. Ablation Studies

Increasing the pale size (from 1 to 7) can continuously improve performance across all tasks, while further up to 9 does not bring obvious and consistent improvements but more FLOPs.
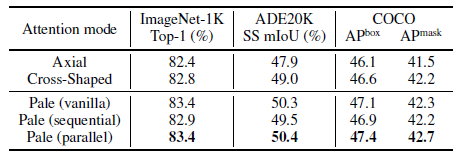
PS-Attention outperforms Axial and Cross-Shaped (CSWin) mechanisms.
Compared to the global self-attention, PS-Attention can reduce the computation and memory costs significantly. Meanwhile, it can capture richer contextual information under the similar computation complexity with previous local self-attention mechanisms.
Reference
[2022 AAAI] [Pale Transformer]
Pale Transformer: A General Vision Transformer Backbone with Pale-Shaped Attention
1.1. Image Classification
1989 … 2022 [ConvNeXt] [PVTv2] [ViT-G] [AS-MLP] [ResTv2] [CSWin Transformer] [Pale Transformer]
