Review — All Tokens Matter: Token Labeling for Training Better Vision Transformers
MixToken or LV-ViT, Token Labeling for Image Classification

All Tokens Matter: Token Labeling for Training Better Vision Transformers
MixToken, LV-ViT, by National University of Singapore, Nankai University, Peking University, and ByteDance
2021 NeurIPS, Over 50 Citations (Sik-Ho Tsang @ Medium)
Image Classification, Vision Transformer, ViT
- Conventional ViTs compute the classification loss on an additional trainable class token, other tokens are not utilized:
- MixToken takes advantage of all the image patch tokens to compute the training loss in a dense manner.
- Specifically, token labeling reformulates the image classification problem into multiple token-level recognition problems and assigns each patch token with an individual location-specific supervision generated by a machine annotator.
Outline
- MixToken or LV-ViT
- MixToken with CutMix
- Ablation Study
- Experimental Results
1. MixToken
1.1. Conventional ViT
- Given an image I, denote the output of the last transformer block as [Xcls, X1 , …, XN], where N is the total number of patch tokens, and Xcls and X1, .., XN correspond to the class token and the patch tokens, respectively. The classification loss for image I is:

- where H(.,.) is the softmax cross-entropy loss and ycls is the class label.
The above classification problem only adopts an image-level label as supervision whereas it neglects the rich information embedded in each image patch.
1.2. Token Labeling

- The dense score map can be generated by a pretrained model in advance, e.g.: NFNet-F6.

MixToken/LV-ViT leverages a dense score map for each training image and use the cross-entropy loss between each output patch token and the corresponding aligned label in the dense score map as an auxiliary loss at the training phase.
- Thus, the token labeling objective is:

- The total loss function is:

- where β=0.5.
Unlike Knowledge Distillation (KD), token labeling is a cheap operation. During training, MixToken only needs to crop the score map and perform interpolation to make it aligned with the cropped image.
2. MixToken with CutMix

- CutMix is directly on the raw images, let say I1 and I2, some of the resulting patches may contain content from two images, leading to mixed regions within a small patch.
- (Please feel free to visit CutMix.)
- MixToken, which can be viewed as a modified version of CutMix operating on the tokens after patch embedding.
- MixToken mixes the corresponding token labels by using a binary mask M:
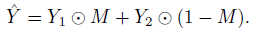
- where ⊙ is element-wise multiplication.
- The label for the class token can be written as:
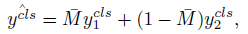
3. Ablation Study

- A slight architecture modification to ViT is that the patch embedding module is replaced with a 4-layer convolution to better tokenize the input image and integrate local information.
LV-ViT-T with only 8.5M parameters can already achieve a top-1 accuracy of 79.1% on ImageNet.

- Left: When training with the original ImageNet labels, using MixToken is 0.1% higher than using CutMix. When using the ReLabel supervision, we can also see an advantage of 0.2% over the CutMix baseline. Combining with token labeling, the performance can be further raised to 83.3%.
Right: When all the four augmentation methods are used, a top-1 accuracy of 83.1% is achieved. Interestingly, when the mixup augmentation is removed, the performance can be improved to 83.3%.
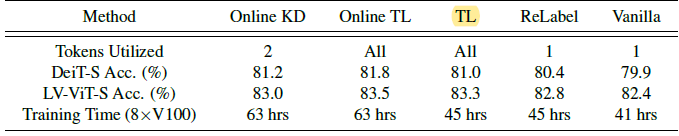
For both online and offline cases, using token-level supervision can improve the overall performance with only negligible additional training cost.
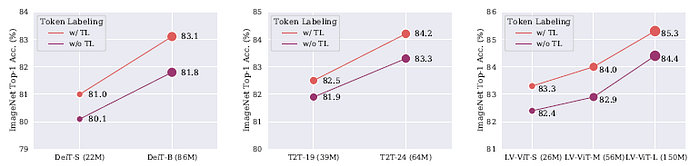
For different variants and scales of the models, the improvement is also consistent.

The proposed method has a consistent improvement on all different models.
4. Experimental Results
4.1 ImageNet & ImageNet-ReaL

The proposed model consistently outperforms other CNN-based and Transformer-based counterparts.
4.2. ADE20K


LV-ViT-L + UPerNet achieves the best result on ADE20K with only ImageNet-1K as training data in pretraining.
MixToken is used in such as Pale Transformer (2022 AAAI) to further boost the performance, in which I will review later on.
Reference
[2021 NeurIPS] [MixToken]
All Tokens Matter: Token Labeling for Training Better Vision Transformers
1.1. Image Classification
1989 … 2021 [MixToken] … 2022 [ConvNeXt] [PVTv2] [ViT-G] [AS-MLP] [ResTv2]
