Review — VoVNet/OSANet: An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection
OSA Module, Better Module Design Than Dense Block in DenseNet, Outperforms Pelee, DenseNet, ResNet Backbones
In this story, An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection, (VoVNet/OSANet), by ETRI, SS C&C, is reviewed. In this paper:
- One-shot aggregation (OSA) module is designed which is more efficient than Dense Block in DenseNet.
- By cascading OSA module, an efficient object detection network VoVNet is formed.
- It is also named as OSANet and further discussed in Scaled-YOLOv4.
This is a paper in 2019 CVPR Workshop. (Sik-Ho Tsang @ Medium)
Outline
- One-Shot Aggregation (OSA) Module in VoVNet
- VoVNet: Network Architecture
- Experimental Results
1. One-Shot Aggregation (OSA) Module in VoVNet

1.1. (a) Dense Block in DenseNet
- Reducing FLOPs and model sizes does not always guarantee the reduction of GPU inference time and real energy consumption. Memory access cost (MAC) is calculated. The MAC of each convolutional layer is:

- where k, h, w, ci, co, denote kernel size, height/width of input and output response, the channel size of input, and that of output response, respectively.
Dense connections induce high memory access cost (MAC) which is paid by energy and time.
The dense connection imposes the use of bottleneck structure which harms the efficiency of GPU parallel computation.
Also, dense connection makes later intermediate layer produce the features that are better but also similar to the features from former layers. In this case, the final layer is not required to learn to aggregate both features because they are representing redundant information.
1.2. (b) Proposed OSA Module in VoVNet
One-shot aggregation (OSA) module is designed to aggregate its feature in the last layer at once, as shown above.
- It has much less MAC than that with dense block. Substituting dense block of DenseNet-40 to OSA module with 5 layers with 43 channels reduces MAC from 3.7M to 2.5M.
- Also, OSA improves GPU computation efficiency. The input sizes of intermediate layers of OSA module are constant. Hence, it is unnecessary to adopt additional 1×1 conv bottleneck to reduce dimension. The means it consists of fewer layers.
2. VoVNet: Network Architecture

There are two types of VoVNet: lightweight network, e.g., VoVNet-27-slim, and large-scale network, e.g., VoVNet-39/57.
- VoVNet consists of a stem block including 3 convolution layers and 4 stages of OSA modules with output stride 32.
- An OSA module is comprised of 5 convolution layers with the same input/output channel for minimizing MAC, as mentioned above.
- Whenever the stage goes up, the feature map is downsampled by 3×3 max pooling with stride 2.
- VoVNet-39/57 have more OSA modules at the 4th and 5th stage where downsampling is done in the last module.
3. Experimental Results
3.1. Lightweight Models

- VoVNet always appears at the corner with better performance and efficiency.

- DSOD is used as the detector network with VoVNet as backbone.
The proposed VoVNet-27-slim based DSOD300 achieves 74.87%, which is better than DenseNet-67 based one even with comparable parameters.
- In addition to accuracy, the inference speed of VoVNet-27-slim is also two times faster than that of the counterpart with comparable FLOPs.
- Pelee has similar inference speed with DSOD with DenseNet-67. WIt is conjectured that decomposing a dense block into smaller fragmented layers deteriorates GPU computing parallelism.
The VoVNet-27-slim based DSOD also outperforms Pelee by a large margin of 3.97% at much faster speed.
3.2. Large-Scale Models


- The generalization to large-scale VoVNet, e.g.,VoVNet-39/57, in RefineDet, is validated.
- It is found that VoVNet and DenseNet obtain higher AP than ResNet on small and medium objects.
Furthermore, VoVNet improves 1.9%/1.2% small object AP gain from DenseNet121/161, which suggests that generating more features by OSA is better than generating deep features by dense connection on small object detection.
3.3. Mask R-CNN from Scratch
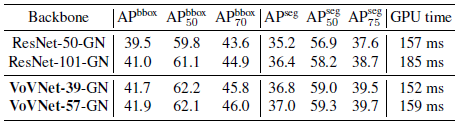
- VoVNet backbone is applied to Mask R-CNN with Group Norm (GN).
- DenseNet cannot be trained even on the 32GB V100 GPUs due to extreme memory footprint of DenseNet and larger input size of Mask R-CNN.
For object detection task, with faster speed, VoVNet-39 obtains 2.2%/0.9% absolute AP gains compared to ResNet-50/101, respectively.
For instance segmentation task, VoVNet-39 also improves 1.6%/0.4% AP from ResNet-50/101.
Reference
[2019 CVPRW] [VoVNet/OSANet]
An Energy and GPU-Computation Efficient Backbone Network for Real-Time Object Detection
Object Detection
2014-2017: …
2018: [YOLOv3] [Cascade R-CNN] [MegDet] [StairNet] [RefineDet] [CornerNet] [Pelee & PeleeNet]
2019: [DCNv2] [Rethinking ImageNet Pre-training] [GRF-DSOD & GRF-SSD] [CenterNet] [Grid R-CNN] [NAS-FPN] [ASFF] [Bag of Freebies] [VoVNet/OSANet]
2020: [EfficientDet] [CSPNet] [YOLOv4] [SpineNet]
