Galactica: A Large Language Model for Science
Galactica (GAL) 120B, Outperforms PaLM 540B

Galactica: A Large Language Model for Science,
Galactica, by Meta AI,
2022 arXiv v1, Over 50 Citations (Sik-Ho Tsang @ Medium)Language Model
1991 … 2022 [GPT-NeoX-20B] [GPT-3.5, InstructGPT] [GLM] [MT-NLG 530B] [Chinchilla] [PaLM] [AlexaTM] [BLOOM] [AlexaTM 20B] [OPT] [Switch Transformers] [LaMDA] [LoRA] 2023 [GPT-4]
==== My Other Paper Readings Are Also Over Here ====
- Galactica (GAL) is introduced, a large language model that can store, combine and reason about scientific knowledge.
- A large scientific corpus of papers, reference material, knowledge bases and many other sources, is proposed. Finally, Galactia outperforms SOTA approaches in many techincal knowledge datasets.
Outline
- Galactica
- Scientific Task Results
- General Capbilities
- Toxicity and Bias
1. Galactica
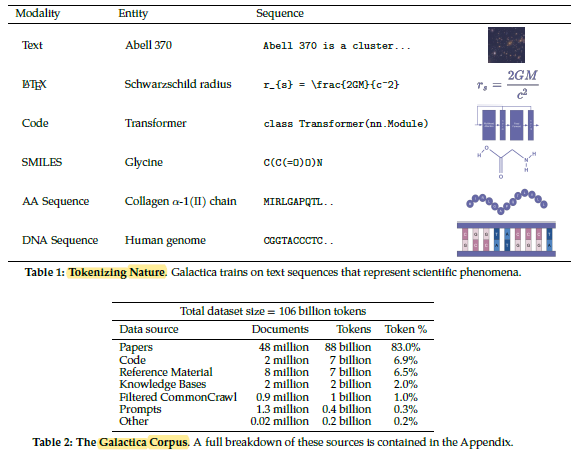
1.1. Corpus
- The corpus consists of 106 billion tokens from papers, reference material, encyclopedias and other scientific sources.
- Natural language sources are combined, such as papers and textbooks, and natural sequences, such as protein sequences and chemical formulae.
1.2. Tokenization


- A set of specialized tokenization is proposed:
- Citations: are wrapped with special reference tokens [START_REF] and [END_REF].
- Step-by-Step Reasoning: are wrapped with a working memory token <work>, mimicking an internal working memory context.
- Mathematics: for mathematical content, with or without LaTeX, ASCII operations are split into individual characters. Parentheses are treated like digits. The rest of the operations allow for unsplit repetitions. Operation characters are !”#$%&’*+,-./:;<=>?\^_‘| and parentheses are ()[]{}.
- Numbers: digits are split into individual tokens. For example 737612.62 -> 7,3,7,6,1,2,.,6,2.
- SMILES formula: Sequences are wrapped with [START_SMILES] and [END_SMILES] and with character-based tokenization applied. Similarly [START_I_SMILES] and [END_I_SMILES] are used where isomeric SMILES is denoted. For example, C(C(=O)O)N→C,(,C,(,=,O,),O,),N.
- Amino acid sequences: are wrapped with [START_AMINO] and [END_AMINO] and character-based tokenization is applied, treating each amino acid character as a single token. For example, MIRLGAPQTL -> M,I,R,L,G,A,P,Q,T,L.
- DNA sequences: a character-based tokenization is applied, treating each nucleotide base as a token, where the start tokens are [START_DNA] and [END_DNA]. For example, CGGTACCCTC -> C, G, G, T, A, C, C, C, T, C.
1.3. Prompt Pre-Training
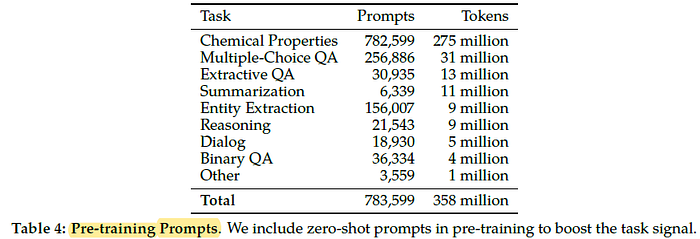
- Prompts are included in pre-training alongside the corpora.
1.4. Models

- Galactica uses a Transformer architecture in a decoder-only setup, with modifications:
- GELU Activation.
- A 2048 length context window.
- No Biases, following PaLM, in any of the dense kernels or layer norms.
- Learned Positional Embeddings.
- Vocabulary of 50k tokens using BPE, which was generated from a randomly selected 2% subset of the training data.
- Model variants are shown as above.
2. Scientific Task Results
2.1. Pretraining
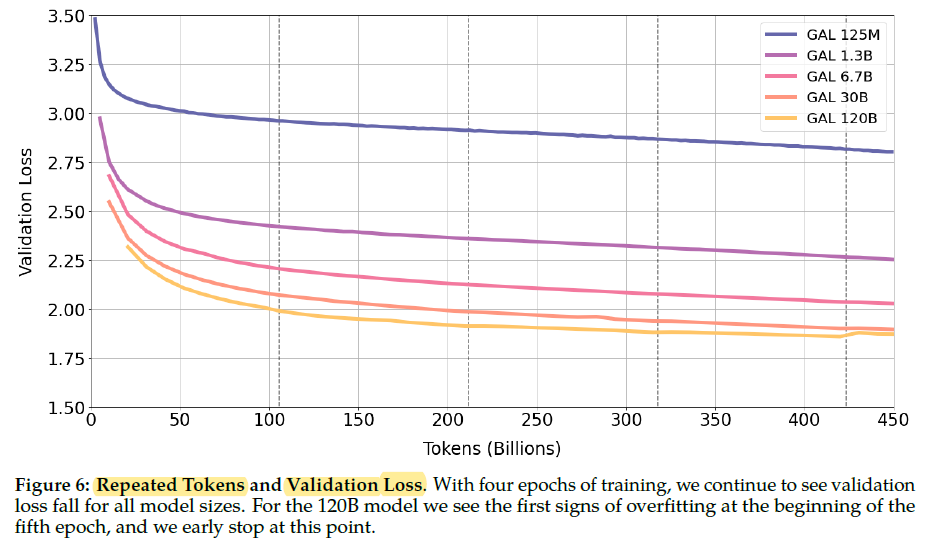
- Models are trained for 450 billion tokens, or approximately 4.25 epochs.
Validation loss continues to fall with four epochs of training. The largest 120B model only begins to overfit at the start of the fifth epoch.
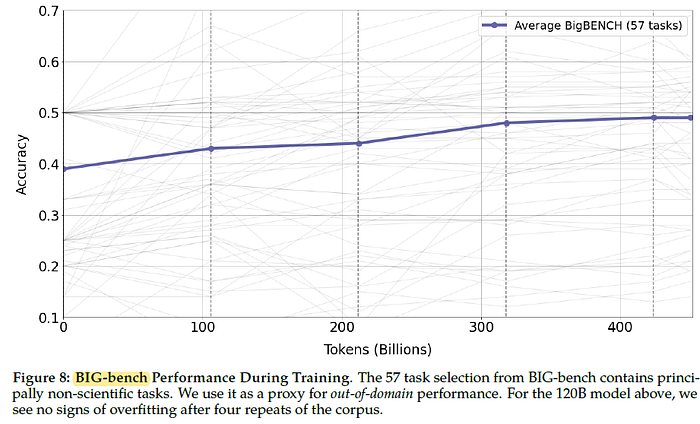
No signs of overfitting suggesting that use of repeated tokens is improving downstream performance as well as upstream performance.
2.2. LaTeX
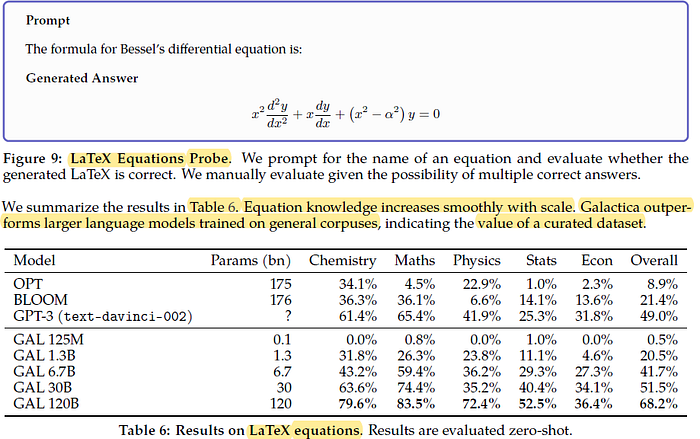
Equation knowledge increases smoothly with scale. Galactica outperforms larger language models trained on general corpuses, indicating the value of a curated dataset.
2.3. Domain Probes
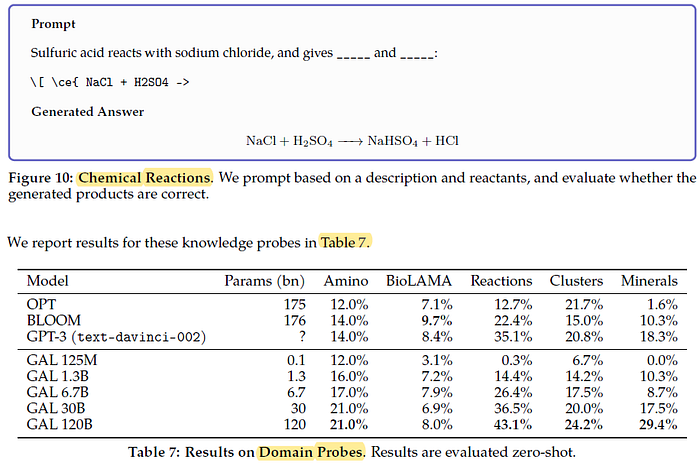
- AminoProbe: a dataset of names, structures and properties of the 20 common amino acids.
- BioLAMA: a dataset of biomedical factual knowledge triples.
- Chemical Reactions: a dataset of chemical reactions.
- Galaxy Clusters: a dataset of galaxy clusters with their constellation classifications.
- Mineral Groups: a dataset of minerals and their mineral group classifications.
We observe steady scaling behaviour in these knowledge probes, with the exception of BioLAMA.
2.4. Reasoning
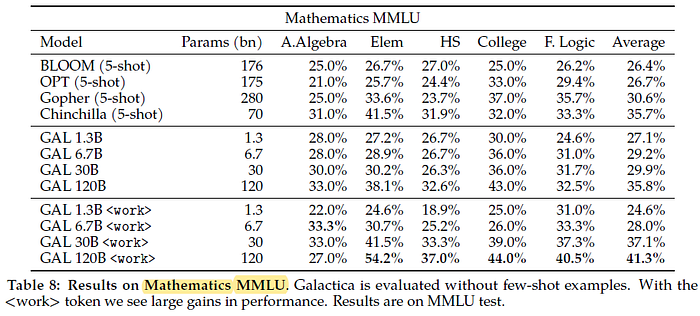
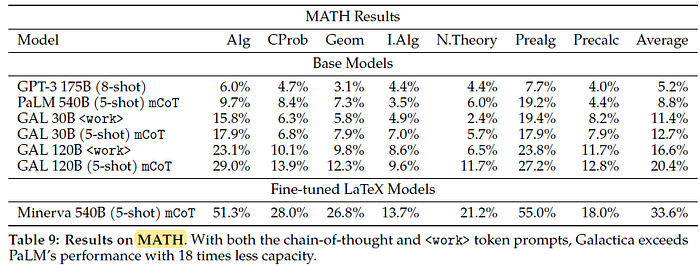
Galactica 30B outperforms PaLM 540B on both chain-of-thought and <work> prompts: an 18 times smaller model. This suggests Galactica may be a better base model for fine-tuning towards mathematical tasks.
2.5. Downstream Scientific NLP
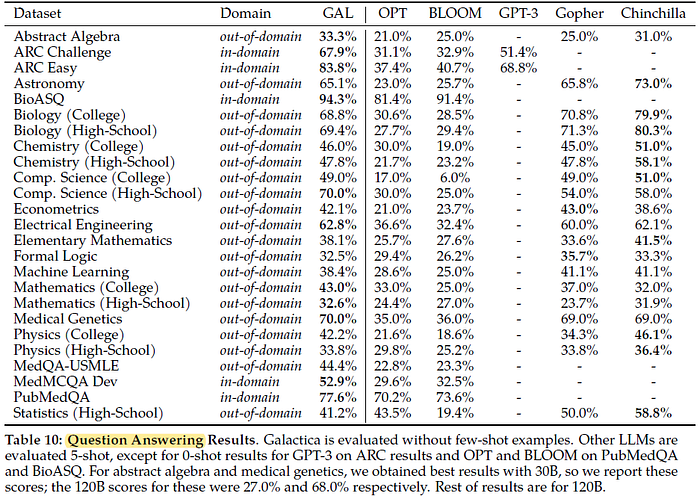
Galactica can compose its knowledge into the question-answering task, and performance is strong; significantly outperforming the other open language models, and outperforming a larger model (Gopher 280B) in the majority of tasks. Performance against Chinchilla is more variable, and Chinchilla appears to be stronger in a subset of tasks.
2.6. Citation Prediction
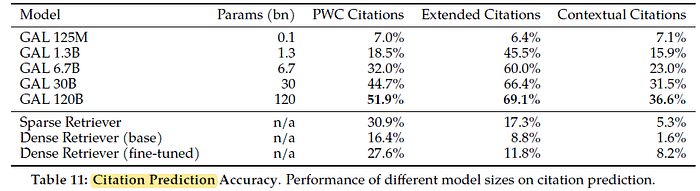
The performance on all evaluation sets increases smoothly with scale. At larger scales, Galactica outperforms the retrieval-based approaches as its context-associative power improves.
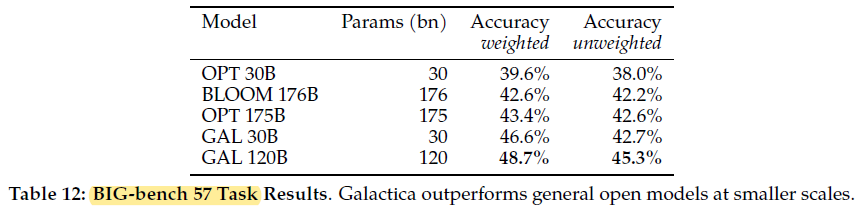

4. Toxicity and Bias
4.1. Bias

Galactica exhibits significantly lower stereotypical biases in most categories, with the exception of sexual orientation and age.
4.2. Toxicity
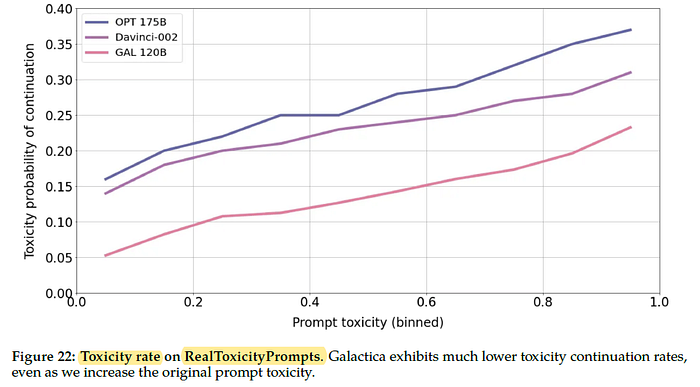
Galactica exhibits substantially lower toxicity rates than the other models.
(To be readable, I have skipped a lot indeed. For more details, please feel free to read the paper directly.)
